
Die automatisierte, Kein Code Datenstapel
Erfahren Sie, wie Astera Data Stack kann die Datenverwaltung Ihres Unternehmens vereinfachen und rationalisieren.

Ihr Leitfaden zur mühelosen Verwendung von AWS S3-Daten
Unternehmen verzichten zunehmend auf veraltete lokale Datenbanken und nutzen stattdessen moderne Cloud-Speicheroptionen, die ihnen die Skalierbarkeit und Flexibilität bieten, um mit dem explosionsartigen Datenwachstum umzugehen. Amazon Web Services ist der größte Player auf dem Cloud-Markt, gefolgt von Google Cloud Platform und Microsoft Azure. Laut a Canalys-Bericht, wuchs der weltweite Cloud-Markt im April 35 um 2021 % und AWS hatte einen Marktanteil von 32 %.
Was ist Amazon S3?
AWS hat entworfen Amazon S3 als Objekt-Cloud-Speicher, der Unternehmen maximale Flexibilität und Skalierbarkeit bietet. Die Fähigkeit von Amazon S3, große Mengen strukturierter und unstrukturierter Daten wie Videos, Bilder zu speichern und mit der Branche zu skalieren macht es für viele Unternehmen zur ersten Wahl. Organisationen wie Netflix und Pinterest nutzen S3-Speicherdienste für Backups, Archive und Data Lakes.
Arbeiten mit Amazon S3-Buckets
Um Daten in Amazon S3 zu speichern, müssen Sie einen Bucket erstellen, und Sie können dann eine beliebige Anzahl von Objekten innerhalb eines Buckets hochladen. Amazon ist ein Schlüsselwertspeicher, was bedeutet, dass jeder Bucket einen weltweit eindeutigen Namen hat. Da alle AWS-Konten denselben Namespace verwenden, können keine zwei Buckets dieselbe Identität haben.
Das Wichtigste, was Sie beim Speichern von Amazon S3 beachten sollten, ist die Erstellung von Buckets in der Region, die Ihnen näher ist. Es hilft Ihnen, die Speicherkosten zu senken und die Latenz beim Abrufen von Daten zu optimieren.
Was macht Amazon S3 zu einer idealen Speicherwahl?
Was Amazon S3 von anderen Speicheroptionen auf dem Markt unterscheidet, ist einfach und dennoch robust. Hier sind einige der Funktionen, die Amazon S3 zur perfekten Wahl für Unternehmen machen, die in Erwägung ziehen, in die Cloud zu wechseln:
Zuverlässigkeit
Amazon S3 verspricht eine Haltbarkeit von 99.999 %, was bedeutet, dass mehrere Kopien von Daten systemübergreifend erstellt werden, sodass es vor allen Ausfällen und Fehlern geschützt bleibt und bei Bedarf verfügbar ist.
Sicherheit
Amazon S3 befasst sich mit dem kritischsten Anliegen beim Speichern von Daten in der Cloud: Sicherheit. Mit S3 können Benutzer alle auf Konto- oder Bucket-Ebene gespeicherten Objekte blockieren. S3 ist auch mit mehreren Compliance-Programmen wie HIPAA, EU-Datenschutz, FISMA usw. konform.
Handlichkeit
Das Beste an Amazon S3 ist seine Verwaltbarkeit. Cloud Storage verfügt über Ebenen kostengünstiger Speicherklassen, die es Ihnen ermöglichen, Daten entsprechend der Zugriffshäufigkeit zu speichern.
Amazon S3-Speicherklassen
Amazon S3-Standard: Der S3-Standard bietet eine geringe Latenz und einen hohen Durchsatz, wodurch er ideal für dynamische Websites, mobile Anwendungen, Inhaltsverteilung und Big-Data-Analysen geeignet ist.
Amazon S3 Standard – Seltener Zugriff: Der seltene Standardzugriff hat niedrige Speicherkosten pro GB, aber eine hohe Leistung, wodurch es ideal für Backups als Speicher für die Notfallwiederherstellung oder Langzeitspeicherung ist.
Amazon S3 One Zone – seltener Zugriff: Eine Zone wird nur in einer einzigen Verfügbarkeitszone gespeichert, im Vergleich zu drei Verfügbarkeitszonen für andere Klassen. Daher sind die Speicherkosten 20 % geringer als bei anderen Speicherklassen.
Amazon S3 Gletscher: Amazon S3 Glacier ist aufgrund seiner kostengünstigen Struktur ideal für die Datenarchivierung.
Erstellen von Amazon S3-Datenpipelines mit Astera
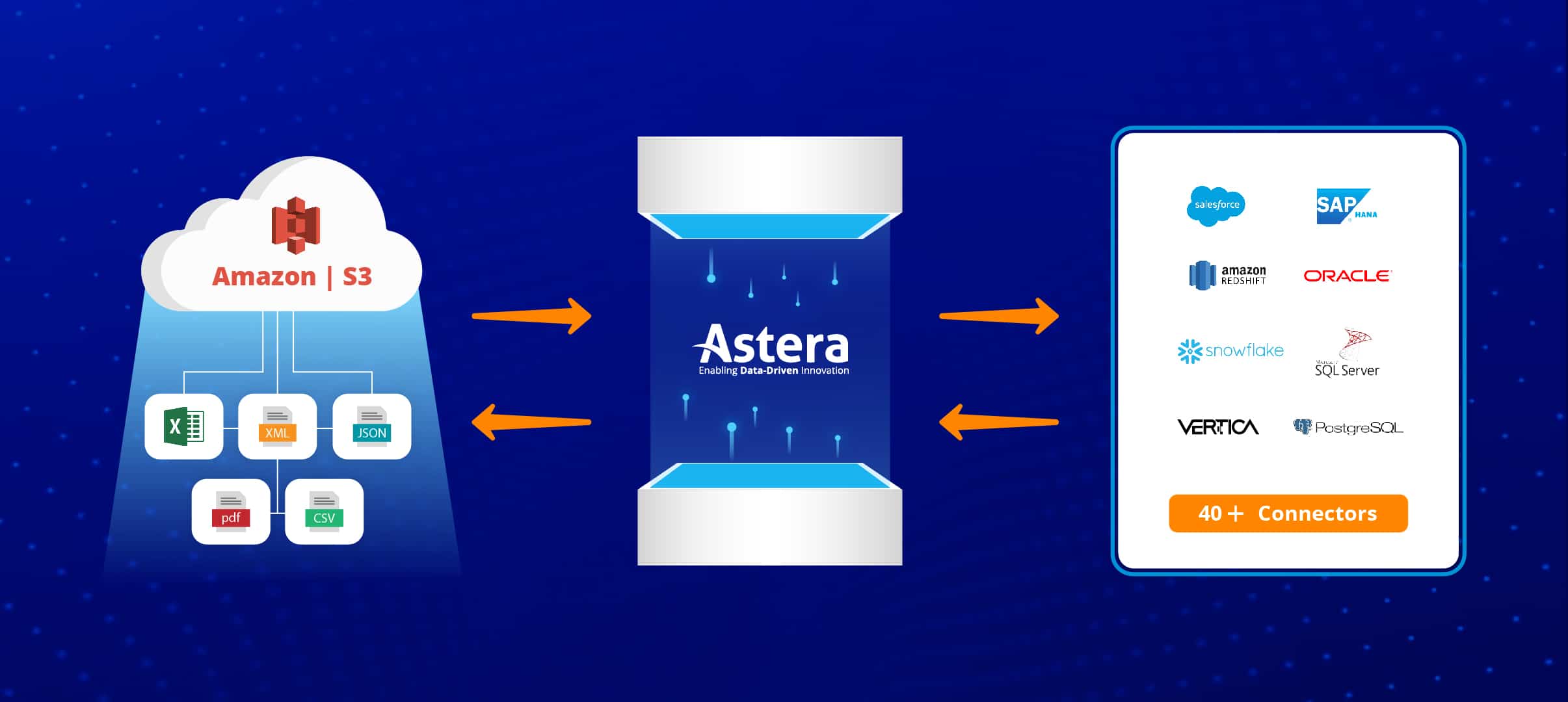
Amazon S3-Datenpipeline
Cloud-Speicher kann nur dann im wahrsten Sinne des Wortes genutzt werden, wenn es einfach ist, Daten dorthin hochzuladen und zu migrieren, bei Bedarf darauf zuzugreifen und sie nahtlos zu integrieren mit anderen Quellen, um eine einheitliche Ansicht für die Analyse zu erstellen. Astera ist ein codefreies Datenintegrationstool, das den Komplexität der Zusammenführung von On-Premise-Systemen mit modernen Cloud-Plattformen, sodass Geschäftsanwender die Skalierbarkeit und Rechenleistung von Amazon S3 wirklich nutzen können, ohne täglich auf IT-Teams angewiesen zu sein.
Zugreifen auf Amazon S3-Daten
Tools wie Astera verfügen über einen integrierten Connector für Amazon S3, der sowohl am Ziel als auch an der Quelle innerhalb Ihrer Datenpipeline verwendet werden kann. Das bedeutet, dass das Werkzeug die manuelle Arbeit erledigt und Sie müssen sich keine Gedanken über Wartungsanforderungen oder Konfigurationsprobleme machen; Alles, was Sie tun müssen, ist, den Amazon S3-Connector einfach per Drag-and-Drop in unser Dataflow-Builder-Modul zu ziehen und schon können Sie den Cloud-Service in wenigen einfachen Schritten für die Verwendung in Ihrer Pipeline konfigurieren.
Sobald Sie den Amazon S3-Cloudspeicher konfiguriert haben, können Sie mit der Integration von S3-Daten in Ihre Unternehmensarchitektur beginnen AsteraDie ausgefeilten Transformationen von s ermöglichen das Sortieren, Filtern und Aggregieren von Daten sowie das Durchführen von Qualitätsprüfungen, bevor sie für Analysen verwendet werden.
Daten nach Amazon S3 migrieren
Initiativen zur Datenmodernisierung sind einer der Hauptgründe, warum Unternehmen auf Cloud-Speicher umsteigen. AsteraEnd-to-End-Datenintegrationsfunktionen von erleichtern Modernisierung von Legacy-Daten Initiativen indem die Zeit, die zum Extrahieren von Datensätzen benötigt wird, erheblich verkürzt wird disparat Quellen und übertragen Sie diese in die Cloud.
Angenommen, Sie sind ein Finanzunternehmen wie eine Bank die auf die Modernisierung von Altbeständen übergehen möchten, um Kosten und Sicherheit zu verbessern, und die Produktivität steigern. Sie können damit beginnen, Daten auf Cloud-Plattformen zu verschieben. Diese Datenmigration kann jedoch manchmal kompliziert werden unkonventionelle Datenquellen und immer anziehender behördliche Anforderungs.
Mit der Astera's eingebaute Anschlüsse Dank der codefreien Umgebung entfällt die Notwendigkeit, benutzerdefinierte Prozesse zu erstellen zur Verbesserung der Gesundheitsgerechtigkeit Nehmen Sie unternehmensübergreifende Daten zu Amazon S3. Dank der Jobplanungs- und Automatisierungsorchestrierungsfunktionen entfällt die manuelle Arbeit, die mit sich wiederholenden Aufgaben verbunden ist, und stellt sicher, dass stets aktuelle Daten auf Ihrer Cloud-Plattform verfügbar sind. Durch die Automatisierung wird auch die Art und Weise standardisiert, wie Daten während der Übertragung behandelt werden sollen, wodurch das Fehlerpotenzial verringert wird.
Verwenden von Amazon S3 als Data Lake
Ein Data Lake kann beweisen eine hervorragende Ressource zum Speichern strukturierter und unstrukturierter Daten aus unterschiedlichen Quellen wie Geschäftsanwendungen, IoT-Geräten, Sensoren und sozialen Medien. Aufbau eines Data Lake auf Cloud-Speicher wie Amazon S3 können zu besserer Sicherheit führen, mehr+ Skalierbarkeit, schnellere Bereitstellungszeit und reduzierte Kosten.
Nehmen wir ein Beispiel für ein Pharmaunternehmen, das führt umfangreiche Recherchen durch, um Medikamente entwickeln. Dieses Unternehmen muss Petabyte an Daten aus internen und externen Quellen verwalten, einschließlich klinische Studien, Arbeitsabläufe im Labor, Gesundheitsdienstleister. Und verschiedene andere Kooperationen. Ein Data Lake ist eine ideale Lösung, um alle Daten effektiv an einem Ort zu verwalten und Innovationen beschleunigen.
Dieses Unternehmen kann nutzen Astera codefreie Umgebung und Konnektivität zu verschiedenen Quellen zu Erstellen Sie nahtlos einen Weg von Betriebsdaten zu erweiterten Analysen.
Sich zusammenschliessen Amazon S3 zu Redshift
AAnalyse von S3-Daten in Amazon Redshift
ETL-Daten von einem Amazon S3-Data Lake zu Redshift oder einem anderen Data Warehouse Reiseziels wie Schneeflocke or Azure und speisen Sie die transformierten Daten dann in BI- oder Visualisierungstools ein, indem Sie Astera integrierte Konnektoren und intuitive Datenzuordnungsfunktionen. Führen Sie Datenqualitätsprüfungen durch, um sicherzustellen, dass die Datenübertragung zu 100 % korrekt ist, damit keine fehlenden oder beschädigten Daten in Ihre Daten-Dashboards gelangen.
Daten auf S3 entladen
Redshift entlädt zu S3 sind oft erforderlich, wenn Sie den Platz verwalten müssen a Rotverschiebungs-Cluster. Dort gibt es zwei Möglichkeiten, dies zu tun: YSie können sich entweder für den Redshift UNLOAD SQL-Befehl entscheiden, was bedeutet, dass Sie die Komplikation des Schreibens von Codes durchlaufen müssen, oder sich für den einfacheren Weg mit entscheiden Astera. Ziehen Sie einfach den Amazon Redshift-Konnektor per Drag-and-Drop und erstellen Sie eine Datenpipeline von Redshift zu Amazon S3.
Extrahieren, integrieren, automatisieren!
Astera vereinfacht die Verbindung zu Amazon S3. Ob Datenmigration nach Amazon S3 oder Integration mit anderen Quellen, Astera ermöglicht es auch Geschäftsanwendern, relevante Prozesse problemlos abzuwickeln. Mit Astera, können Sie sich wiederholende Aufgaben automatisieren und Ihre Datenmigrations- und Integrationsprojekte beschleunigen.
Willst du versuchen Astera ? Laden Sie eine herunter Kostenlose Testphase



