
Die automatisierte, Kein Code Datenstapel
Erfahren Sie, wie Astera Data Stack kann die Datenverwaltung Ihres Unternehmens vereinfachen und rationalisieren.

Automatisieren Sie die PDF-Datenextraktion für schnellere Einblicke
PDF (Portable Document Format) ist ein Industriestandard und eines der am weitesten verbreiteten Formate für die Präsentation und den Austausch von Informationen. Einige gängige Geschäftsdokumente, die im PDF-Format in der Lieferkette, der Unternehmensverwaltung und der Beschaffungsbranche geteilt werden, sind:
- Rechnungen
- Verträge
- Kauforder
- Meldungen
- HR-Formulare
- Versandhinweise
- Presentations
- Produkt- und Preislisten
Während sich PDFs hervorragend zum Austausch von Informationen eignen, kann es schwierig und mühsam sein, Erkenntnisse aus den Daten in diesen Dateien zu gewinnen, da dies bei den in PDF-Dateien gespeicherten Daten der Fall ist unstrukturiert und kann Text und Bilder enthalten.
Das Extrahieren unstrukturierter Daten wird noch schwieriger, wenn Sie dies manuell für jede PDF-Datei tun müssen. Das ist wo PDF-Scraping kommt zur Rettung. Es hilft, Daten aus PDF-Dateien automatisiert zu extrahieren.

Manuelle PDF-Datenextraktion
Das manuelle Extrahieren von Daten aus PDFs ist ressourcenintensiv. Es erfordert, dass jemand im Team die Tabelle auswählt und alle Informationen in den PDF-Tabellen manuell kopiert, was zu Fehlern und langen Bearbeitungszeiten führen kann.
Der Prozess wird noch schwieriger, wenn Hunderte von PDF-Dokumente ist involviert. Selbst wenn Sie mehrere Ressourcen für den Datenabruf haben, kann es ohne Automatisierung der Datenextraktion Tage oder Wochen dauern, bis Sie durch manuelle Dateneingabe umsetzbare Informationen erhalten.
Manuelle Datenextraktion: Kosten vs. Effizienz
Lassen Sie es uns in Zahlen aufschlüsseln, damit Sie die Kosten verstehen, wenn Sie Informationen aus PDFs extrahieren. Stellen Sie sich vor, Sie haben einen dedizierten Analysten an Bord, der dafür verantwortlich ist, Daten aus unstrukturierten PDF-Dokumenten abzurufen und zu analysieren. In diesem Fall könnten die Kosten wie folgt aussehen:
- Das durchschnittliche Gehalt eines Analysten = 60,000 USD pro Jahr (US-Medianlohn)
- Der Durchschnitt Zeitaufwand durch einen Analysten zur Datenextraktion aus PDF-Dokumente, einschließlich Datenextraktion, Reinigung und Vorbereitung pro Tag = 70 %
- Die Kosten, die einem Analysten beim Extrahieren und Vorbereiten unstrukturierter Daten aus PDF entstehen, = 42,000 US-Dollar
Bei der manuellen Datenextraktion wird die meiste Zeit und Mühe der Ressource für die Datenaufbereitung aufgewendet, statt sie zu analysieren. Darüber hinaus ist die manuelle Extraktion oft ungenau.
Ein alternativer Ansatz hierfür kann darin bestehen, die Extraktion auszulagern. Eine Enterprise-Klasse Datenextraktionswerkzeug Gefällt mir Astera ReportMiner kann eine kostengünstige und effiziente Lösung sein. Die Automatisierung des PDF-Datenextraktionsprozesses mit solchen Tools reduziert den manuellen Aufwand, beschleunigt die Datenverfügbarkeit und stellt die Datengenauigkeit sicher.
Automatisierte PDF-Datenextraktion
Unter Berücksichtigung der Herausforderungen der manuellen Datenextraktion besteht eine ideale Lösung für Unternehmen darin, alle Arten von PDF-Dokumenten mit minimalem menschlichen Eingriff durch Tools von Drittanbietern analysieren zu können. So kann PDF-Datenextraktionssoftware Ihrem Unternehmen helfen:
- Sie können Regeln und Formeln erstellen und konfigurieren, um Daten automatisch aus PDF in Excel zu extrahieren. Dies verringert die Zeit, die zum manuellen Suchen und Kopieren/Neueingeben der erforderlichen Informationen erforderlich ist.
- Sie können Daten aus Bildern durch integrierte OCR-Engines in Text extrahieren, ohne die Daten erneut manuell eingeben zu müssen. Dies verringert die Wahrscheinlichkeit von Tippfehlern und anderen Fehlern während der Extraktion.
- Sie können die Datenextraktion aus PDFs durch KI automatisieren. Dies geschieht durch die Verwendung von KI, um wichtige Felder zu erkennen und automatisch zu extrahieren.
- Sie können die gesamte Extraktionspipeline automatisieren und für einen Stapel von PDF-Dateien ausführen, um alle gewünschten Informationen auf einmal zu erhalten. Dies verbessert die Geschäftseffizienz und stellt sicher, dass die Daten bei Bedarf verfügbar sind.
Wie automatisiere ich die PDF-Datenextraktion?
Sie können die PDF-Datenerfassung mit einer dieser beiden Methoden automatisieren. Die erste Methode ist zeitaufwändig, erfordert mehr Ressourcen und hat eine höhere Trial-and-Error-Tendenz. Die zweite Methode hingegen ist mit Hilfe eines Datenextraktionstools vollständig automatisiert.
1. Verwenden Sie Codes und Skripte
Die erste Methode besteht darin, Code oder Skripte für die Dokumentenverarbeitung zu schreiben und die gewünschten Informationen aus PDF-Dokumenten zu extrahieren. Dies wird jedoch für die meisten Unternehmen nicht empfohlen, da es eine hohe Komplexität und dedizierte Entwicklerressourcen erfordert. Es erfordert oft, dass Sie Code neu schreiben/modifizieren, wenn sich die Dokumentstruktur ändert.
2. Verwenden Sie das Datenextraktionstool
Verwenden Sie ein Tool zum Extrahieren von Daten aus PDFs, z ReportMiner. Es ist eine Automatisierungslösung für die Datenextraktion mit integrierter Unterstützung für die automatische Datenextraktion. Es bietet eine einfache Benutzeroberfläche, die keine Programmierung erfordert. Daher wird dies für Unternehmen empfohlen, die Informationen schnell und genau aus großen Mengen von PDFs extrahieren müssen.
Ultraschall ReportMiner Vereinfacht die automatisierte PDF-Datenextraktion
Zu den wesentlichen Funktionen, die Sie benötigen, um die Datenextraktion aus verschiedenen PDF-Typen zu automatisieren, gehören:
- Textbasierte PDFs: Sie können eine Extraktionsvorlage erstellen, die aus Datenbereichen und Feldern besteht. Dies sind Abschnitte und Werte, die Sie extrahieren möchten. Durch dies, ReportMiner kann diese Dokumente lesen und Informationen abrufen.
- Gescannte (bildbasierte) PDFs: Nicht alle PDFs bestehen aus Textdaten. Die meisten von Unternehmen verwendeten PDF-Dokumente sind gescannte Bilder (z. B. Rechnungen). Die OCR-Funktion (optische Zeichenerkennung) von ReportMinner kann Textdaten aus Bildern extrahieren. Sobald Sie Ihr gescanntes Dokument durchlaufen haben ReportMinerEs ähnelt einem textbasierten PDF und vereinfacht die Informationserfassung.
- Formularbasierte PDFs: Häufig müssen sich Unternehmen mit PDF-Formularen auseinandersetzen, beispielsweise für Kundenbefragungen oder Mitarbeiterfeedbacks. Diese PDFs sind strukturierter als andere Typen. Sie können Gebrauch machen ReportMiner um wichtige Geschäftsdaten (z. B. Kundeninformationen) zu extrahieren und für Berichte und Analysen zu verwenden.
Sobald Sie eine Extraktionsvorlage in entworfen haben ReportMiner, können Sie es wiederverwenden, um die Extraktion aus PDFs mit ähnlichen Layouts zu automatisieren. Mit dem Tool können Sie PDF- und Excel-Dateien aus verschiedenen Quellen lesen, einschließlich FTP-Server, E-Mail-Server und unstrukturierte Systeme.
Wenn Sie eine schnellere Lösung bevorzugen, ReportMiner bietet KI-gestützte Datenerfassung, sodass keine Vorlagen mehr erstellt werden müssen. Es ermöglicht Ihnen, alle wichtigen Felder in Ihrem PDF einfach mit nur einem Klick zu extrahieren.
Die extrahierten Daten können weiter transformiert und an ein Ziel Ihrer Wahl exportiert werden. Einige beliebte Optionen sind Excel-Tabellen, Datenbanken und CSV-Dateien.
Starten Sie die automatische PDF-Datenextraktion mit ReportMiner
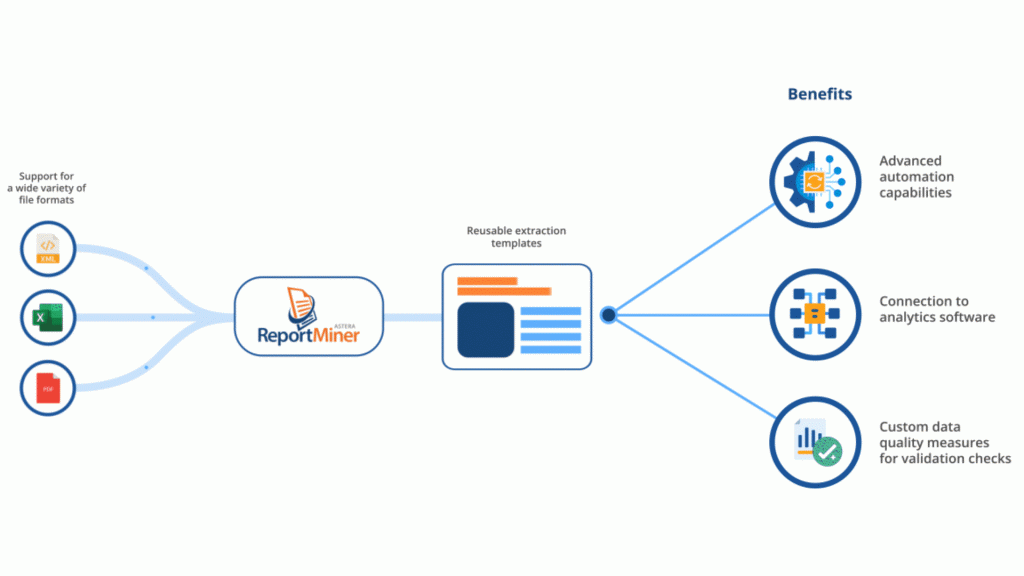
Unternehmen erfassen und verarbeiten eine Vielzahl von Informationen in PDF-Dokumenten, einschließlich Transaktions- und Berichtsdaten. Die Herausforderung besteht darin, diese Informationen mit angemessener Genauigkeit und Geschwindigkeit zu extrahieren und zu strukturieren. Dies kann durch die Automatisierung der PDF-Datenextraktion erreicht werden ReportMiner.
Laden Sie die Testversion herunter, um zu erfahren, wie Astera ReportMiner kann Ihnen helfen, Daten aus PDF-Dateien einfach zu extrahieren.



