
Die automatisierte, Kein Code Datenstapel
Erfahren Sie, wie Astera Data Stack kann die Datenverwaltung Ihres Unternehmens vereinfachen und rationalisieren.

Datenpipeline-Architektur: Alles, was Sie wissen müssen
Der Erfolg eines jeden Unternehmens hängt heute davon ab, wie schnell es Daten verarbeiten kann, weshalb eine hohe Skalierbarkeit erforderlich ist Datenpipelines wird für den Betrieb eines Unternehmens immer wichtiger. Datenpipelines sind die moderne Lösung dafür automatisieren, and Skala repetitiv technische Daten Einnahme, Transformation, und Integrationsaktivitäten. Eine geeignete Datenpipeline-Architektur kann die Verfügbarkeit hochwertiger Daten für nachgelagerte Systeme und Anwendungen erheblich beschleunigen.
In diesem Blog besprechen wir, was eine Datenpipeline-Architektur ist und warum sie vorab geplant werden muss Datenintegration Projekt. Als Nächstes sehen wir uns die grundlegenden Teile und Prozesse einer Datenpipeline an. Wir werden auch andere erkunden Datenpipeline-Architekturs und über eines der Besten sprechen Datenverwaltungstools auf dem Markt.
Was ist eine Datenpipeline-Architektur?
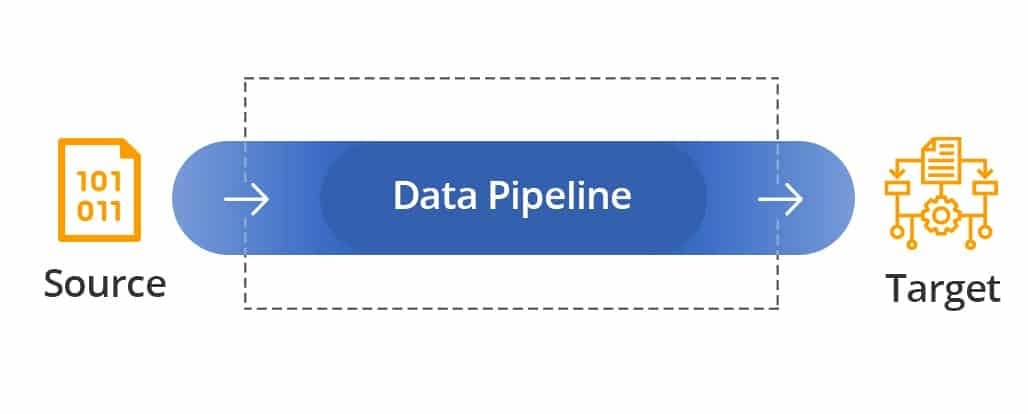
Einfach ausgedrückt nimmt eine Datenpipeline Daten von der Quelle, verarbeitet sie und verschiebt sie an das Ziel, genau wie jede andere Pipeline in der physischen Welt. Sie können sich die Datenpipeline-Architektur so vorstellen organisiertes, vernetztes System, das Rohdaten aufnimmt, verfeinert, speichert, analysiert und dann die wertvollen Ergebnisse weitergibt – alles auf systematische und automatisierte Weise. Das Ziel besteht darin, nachgelagerten Anwendungen und Endbenutzern einen konsistenten Fluss sauberer und konsistenter Daten bereitzustellen.
Im Gegensatz zu einem ETL-Pipeline Dabei handelt es sich um das Extrahieren von Daten aus einer Quelle, deren Transformation und das anschließende Laden in ein Zielsystem. Eine Datenpipeline ist eine etwas umfassendere Terminologie und ETL (Extrahieren, Transformieren, Laden) nur eine Teilmenge. Der Hauptunterschied zwischen ETL und der Datenpipeline-Architektur besteht darin, dass letztere Datenverarbeitungstools verwendet, um Daten von einem System in ein anderes zu verschieben, unabhängig davon, ob die Daten transformiert sind oder nicht.
Ihre Daten ändern
Komponenten der Datenpipeline-Architektur
Nachdem Sie nun eine Vorstellung von der Datenpipeline-Architektur haben, werfen wir einen Blick auf den Entwurf und gehen auf die einzelnen Komponenten einer Datenpipeline ein:
Datenquellen: Ihre Datenpipeline beginnt bei den Datenquellen, in denen Ihre Daten generiert werden. Ihre Datenquellen Dies können Datenbanken sein, in denen Kundeninformationen gespeichert sind, Protokolldateien, die Systemereignisse erfassen, oder externe APIs, die Echtzeit-Datenströme bereitstellen. Diese Quellen generieren das Rohmaterial für Ihre Datenreise. TDie Art der Quelle bestimmt die Methode der Datenaufnahme.
Datenaufnahme: Als nächstes folgt die Datenaufnahmekomponente, die Daten aus Quellsystemen sammelt und in die Datenpipeline importiert. Dies kann je nach Anforderung durch Stapelverarbeitung oder Echtzeit-Streaming erfolgen. Datenaufnahme Dies kann im Wesentlichen auf zwei Arten erfolgen: durch Stapelverarbeitung, bei der Daten in geplanten Intervallen erfasst werden, oder durch Echtzeit-Streaming, bei dem Daten kontinuierlich fließen, während sie generiert werden.
Die Datenaufnahme hängt auch von der Art der Daten ab, mit denen Sie arbeiten. Wenn Sie beispielsweise hauptsächlich über unstrukturierte Daten wie PDFs verfügen, benötigen Sie eine spezielle Datenextraktionssoftware wie z Astera Bergmann melden.
Datenverarbeitung: Dies ist einer der wichtigsten Schritte in der Architektur, da er die Daten für den Konsum nutzbar macht. Rohdaten können unvollständig sein oder Fehler enthalten beispielsweise ungültige Felder wie eine Staatsabkürzung oder eine Postleitzahl, die nicht mehr existiert. Ebenso können Daten auch beschädigte Datensätze enthalten, die in einem anderen Prozess gelöscht oder geändert werden müssen. Bei der Datenbereinigung geht es darum, Daten zu standardisieren, Duplikate zu entfernen und Nullwerte einzugeben.
Die Verarbeitungsphase umfasst auch die Datentransformation. Abhängig von Ihren Daten müssen Sie möglicherweise verschiedene Transformationen wie Normalisierung, Denormalisierung, Sortierung, Baumverknüpfung usw. implementieren. Das Ziel der Transformation besteht darin, Daten in eine zu konvertieren geeignetes Format für die Analyse.
Datenspeicher: Anschließend werden die verarbeiteten Daten in Datenbanken gespeichert bzw Data Warehouse. Ein Unternehmen kann Daten für verschiedene Zwecke speichern, beispielsweise zur historischen Analyse, zur Redundanz oder einfach, um sie den Benutzern an einem zentralen Ort zugänglich zu machen. Je nach Zweck können Daten an verschiedenen Orten gespeichert werden, beispielsweise in relationalen Datenbanken. Zum Beispiel, Für strukturierte Daten mit wohldefinierten Schemata eignen sich PostgreSQL, MySQL oder Oracle.
NoSQL-Datenbanken wie MongoDB, Cassandra sind auf Flexibilität und Skalierbarkeit ausgelegt und eignet sich gut für den Umgang mit unstrukturierten oder halbstrukturierten Daten und kann horizontal skaliert werden, um große Mengen zu verwalten.
Daten werden auch in Data Warehouses gespeichert. Allerdings werden Data Warehouses häufig mit Cloud-Speicherplattformen wie Google Cloud, Amazon S3 und Microsoft Blob Storage kombiniert, die große Datenmengen speichern.
Datenanalyse: In der Datenanalysekomponente wird die rohe Kraft der Daten zum Leben erweckt. Dabei geht es darum, die gespeicherten Daten abzufragen, zu verarbeiten und aussagekräftige Erkenntnisse abzuleiten. Datenanalysten und Wissenschaftler verwenden unterschiedliche Tools und Technologien, um Analysen durchzuführen, wie z. B. deskriptive, prädiktive und statistische Analysen, um Erkenntnismuster und Trends in Daten aufzudecken.
Zu den am häufigsten verwendeten Sprachen und Techniken zur Datenanalyse gehört SQL, das sich am besten für relationale Datenbanken eignet. Darüber hinaus verwenden Benutzer häufig auch Python- oder R-Programmierung.
Datenvisualisierung: Eine Datenpipeline endet bei der Datenvisualisierung, bei der Daten in Tabellen und Kreisdiagramme umgewandelt werden, damit Datenanalysten sie leichter verstehen können. Visualisierungswerkzeuge wie PowerBI und Tableau Bieten Sie eine intuitive Benutzeroberfläche zum Erkunden von Rohdaten. Analysten und Datenwissenschaftler können interaktiv durch Datensätze navigieren, Muster erkennen und sich ein vorläufiges Verständnis der Informationen verschaffen.
Lesen Sie mehr: Die 10 besten Datenpipeline-Tools
Arten von Datenpipelines und ihre Architektur
Keine Datenpipeline-Architektur gleicht der anderen, da es keine einheitliche Art der Datenverarbeitung gibt. Abhängig von der Vielfalt und Anzahl der Datenquellen müssen Daten möglicherweise mehrmals transformiert werden, bevor sie ihr Ziel erreichen.
Architektur der Stapelverarbeitung

Stapel Datenpipeline ist eine Datenverarbeitungstechnik, bei der Daten gesammelt, verarbeitet und anschließend die Ergebnisse ermittelt werden in Abständen. Es wird typischerweise für große Datenmengen verwendet, die verarbeitet werden können, ohne dass sofortige Ergebnisse erforderlich sind.
Normalerweise, data wird in Batches oder Chunks unterteilt. Diese Unterteilung dient dazu, die Verarbeitung großer Datensätze übersichtlicher zu verwalten. Jeder Stapel stellt eine Teilmenge der Gesamtdaten dara und wird verarbeitet unabhängig. Die Verarbeitung kann verschiedene Vorgänge wie Filterung, Aggregation, statistische Analyse usw. umfassen. Die Ergebnisse jedes Stapelverarbeitungsschritts werden normalerweise in einem persistenten Speichersystem gespeichert.
Anwendungsfälle: Geeignet für Szenarien, in denen die Echtzeitverarbeitung nicht kritisch ist, z. B. tägliche oder stündliche Datenaktualisierungen. Zum Beispiel gibt es ein E-Commerce-Unternehmen, das seine Verkaufsdaten analysieren möchte, um Einblicke in das Kundenverhalten, die Produktleistung und allgemeine Geschäftstrends zu gewinnen ermöglicht es dem E-Commerce-Unternehmen, eine detaillierte Analyse seiner Verkaufsdaten durchzuführen, ohne dass Echtzeitergebnisse erforderlich sind.
Komponenten:
- Datenquelle: Woher die Rohdaten stammen.
- Stapelverarbeitungs-Engine: Verarbeitet Daten in vordefinierten Intervallen.
- Lagerung: Enthält verarbeitete Daten.
- Scheduler: Löst die Stapelverarbeitung zu bestimmten Zeiten aus.
Streaming-Daten-Pipeline
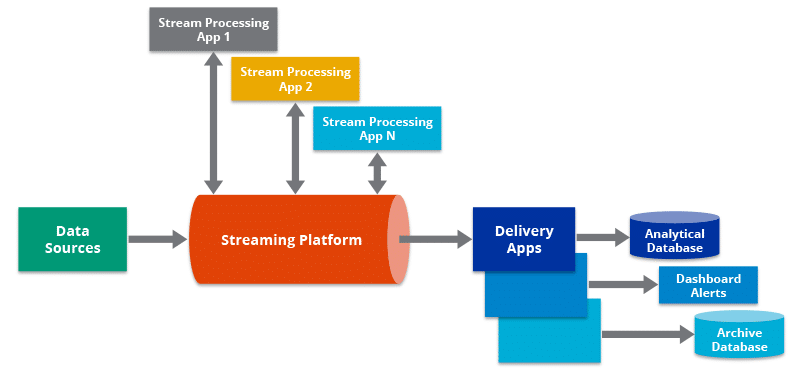
Die Stream-Verarbeitung führt Operationen an Daten in Bewegung oder in Echtzeit durch. Es ermöglicht Ihnen, Bedingungen innerhalb eines kürzeren Zeitraums nach Erhalt der Daten schnell zu erkennen. Dadurch können Sie Daten direkt bei der Erstellung in das Analysetool eingeben und erhalten umgehend Ergebnisse.
Die Streaming-Datenpipeline verarbeitet die Daten aus dem POS-System während der Erstellung. Die Stream-Verarbeitungs-Engine sendet Ausgaben von der Datenpipeline an Datenrepositorys, Marketing-Apps, CRMs und mehrere andere Anwendungen, zusätzlich zum Zurücksenden an das POS-System selbst.
Anwendungsfälle: Ideal für Anwendungen, die eine Datenverarbeitung mit geringer Latenz erfordern. Zum Beispiel ichIn der Finanzbranche ist die Erkennung betrügerischer Transaktionen von entscheidender Bedeutung, um finanzielle Verluste zu verhindern und die Sicherheit der Benutzerkonten zu gewährleisten. Herkömmliche Stapelverarbeitungssysteme reichen möglicherweise nicht aus, um betrügerische Aktivitäten schnell zu erkennen. Eine Streaming-Datenpipeline hingegen kann eine Echtzeitanalyse von Transaktionen ermöglichen, während sie stattfinden von Geldautomaten, Kreditkarten etc.
Komponenten der Datenpipeline
- Datenquelle: Erzeugt kontinuierliche Datenströme.
- Stream-Verarbeitungs-Engine: Verarbeitet Daten in Echtzeit.
- Lagerung: Speichert optional verarbeitete Daten für die historische Analyse.
Lambda
Die Lambda-Architektur ist eine Datenverarbeitungsarchitektur, die sowohl für die Stapel- als auch für die Stream-Verarbeitung von Daten ausgelegt ist. Es wurde von Nathan Marz eingeführt, um die Herausforderungen der Big-Data-Verarbeitung zu bewältigen, bei der Anforderungen an niedrige Latenzzeiten für Echtzeitanalysen mit der Notwendigkeit der Verarbeitung großer Datenmengen im Batch-Modus einhergehen. Die Lambda-Architektur erreicht dies durch die Kombination von Stapelverarbeitung und Stream-Verarbeitung in einem einzigen, skalierbaren und fehlertoleranten System.
Hier sind die wichtigsten Komponenten und Schichten der Lambda-Architektur:
Batch-Ebene:
- Funktion: Bewältigt die Verarbeitung großer Mengen historischer Daten auf fehlertolerante und skalierbare Weise.
- Datenspeicherung: Verwendet normalerweise ein verteiltes Dateisystem wie Apache Hadoop Distributed File System (HDFS) oder cloudbasierte Speichersysteme.
- Verarbeitungsmodell: Bei der Stapelverarbeitung werden Berechnungen für einen vollständigen Datensatz ausgeführt, wodurch Ergebnisse erzeugt werden, die normalerweise in einer Stapelansicht oder einer Stapelschicht-Bereitstellungsschicht gespeichert werden.
Geschwindigkeitsschicht:
- Funktion: Befasst sich mit der Echtzeitverarbeitung von Datenströmen und liefert Ergebnisse mit geringer Latenz für aktuelle Daten.
- Datenspeicherung: Basiert normalerweise auf einem verteilten und fehlertoleranten Speichersystem, das schnelle Schreib- und Lesevorgänge für die Echtzeitverarbeitung unterstützt.
- Verarbeitungsmodell: Bei der Stream-Verarbeitung werden Daten bei ihrem Eintreffen in Echtzeit analysiert, um aktuelle Ergebnisse zu liefern.
Servierschicht:
- Funktion: Führt die Ergebnisse der Batch- und Geschwindigkeitsebenen zusammen und bietet eine einheitliche Ansicht der Daten.
- Datenspeicherung: Verwendet eine NoSQL-Datenbank oder eine verteilte Datenbank, die sowohl Batch- als auch Echtzeitdaten verarbeiten kann.
- Verarbeitungsmodell: Stellt vorberechnete Stapelansichten und Echtzeitansichten für die abfragende Anwendung bereit.
Abfrageebene:
- Funktion: Ermöglicht Benutzern die Abfrage und den Zugriff auf die Daten in der Bereitstellungsschicht.
- Datenspeicherung: Abfrageergebnisse werden von der Bereitstellungsschicht abgerufen.
- Verarbeitungsmodell: Ermöglicht Ad-hoc-Abfragen und die Untersuchung von Batch- und Echtzeitansichten.
ETL-Pipeline
Es gibt einen Unterschied zwischen einem ETL-Pipeline und eine Datenpipeline. Eine ETL-Pipeline ist eine Form einer Datenpipeline Wird verwendet, um Daten aus verschiedenen Quellen zu extrahieren, sie in ein gewünschtes Format umzuwandeln und sie für Analyse-, Berichts- oder Business-Intelligence-Zwecke in eine Zieldatenbank oder ein Data Warehouse zu laden. Der Hauptzweck einer ETL-Pipeline besteht darin, das zu erleichtern Bewegung von Daten aus verschiedenen Quellen an ein zentrales Repository, wo sie effizient analysiert und für die Entscheidungsfindung genutzt werden können.
ELT-Pipeline
An ELT (Extract, Load, Transform)-Pipeline ist eine Alternative zum herkömmlichen ETL-Ansatz. Während das grundlegende Ziel beider ETL und ELT ist da zu bewegen und vorzubereiten. Für die Analyse unterscheiden sie sich in der Reihenfolge, in der der Transformationsschritt erfolgt. In einer ETL-Pipeline erfolgt die Transformation vor dem Laden der Daten in das Zielsystem, während in einer ELT-Pipeline die Transformation nach dem Laden der Daten in das Zielsystem durchgeführt wird.
ELT-Pipelines nutzen häufig die Verarbeitungsleistung moderner Data Warehouses, die für die Bewältigung umfangreicher Datentransformationen ausgelegt sind.
Auf dem Gelände
Eine lokale Datenpipeline bezieht sich auf eine Reihe von Prozessen und Tools, mit denen Unternehmen Daten innerhalb ihrer eigenen physischen Infrastruktur oder Rechenzentren sammeln, verarbeiten, umwandeln und analysieren, anstatt sich auf cloudbasierte Lösungen zu verlassen. Dieser Ansatz wird häufig aus Gründen wie Datensicherheit, Compliance-Anforderungen oder der Notwendigkeit einer direkteren Kontrolle über die Infrastruktur gewählt.
Lokale Architekturen basieren auf Servern und Hardware, die sich physisch im eigenen Rechenzentrum oder in der eigenen Einrichtung einer Organisation befinden. OOrganisationen haben die vollständige Kontrolle über Hardware, Software und Netzwerkkonfigurationen. Sie sind für den Kauf, die Wartung und die Aufrüstung aller Komponenten verantwortlich. Allerdings, sDer Ausbau der Infrastruktur ist oft mit erheblichen Kapitalinvestitionen verbunden und der Ausbau kann einige Zeit in Anspruch nehmen.
Cloud native
Eine Cloud-native Datenpipeline-Architektur ist darauf ausgelegt, die Vorteile des Cloud Computing zu nutzen und Skalierbarkeit, Flexibilität und Kosteneffizienz zu bieten. Typischerweise handelt es sich dabei um eine Kombination aus verwalteten Diensten, Mikrodiensten und Containerisierung.
Eine Cloud-native Datenpipeline-Architektur ist so konzipiert, dass sie dynamisch und skalierbar ist und auf sich ändernde Datenverarbeitungsanforderungen reagiert. Es optimiert die Ressourcennutzung, erhöht die Flexibilität und führt häufig zu kostengünstigeren und effizienteren Datenverarbeitungsabläufen im Vergleich zu herkömmlichen Lösungen vor Ort.
Es ist dirtilisierens die serverlose Funktionen und Dienste, um den Betriebsaufwand zu reduzieren und Ressourcen je nach Bedarf zu skalieren.
So erhöhen Sie die Geschwindigkeit der Datenpipeline
Unabhängig davon, für welche Datenarchitektur Sie sich entscheiden, kommt es letztendlich darauf an, wie schnell und effizient Ihre Datenpipeline ist. Nun, es gibt bestimmte Kennzahlen, an denen Sie messen können o Bewerten Sie die Geschwindigkeit einer Datenpipeline. Diese Metriken bieten Einblicke in verschiedene Aspekte der Verarbeitungsfähigkeiten der Pipeline:
1. Durchsatz
It misst die Rate, mit der Daten über einen bestimmten Zeitraum erfolgreich von der Pipeline verarbeitet werden.
Durchsatz (Datensätze pro Sekunde oder Bytes pro Sekunde) = Gesamtzahl der verarbeiteten Datensätze oder Datengröße / für die Verarbeitung benötigte Zeit
2. Latenz
Latenz ist die Zeit, die ein Datenelement benötigt, um die gesamte Pipeline von der Quelle zum Ziel zu durchlaufen.
Latenz = End-to-End-Verarbeitungszeit eines Datensatzes
3. Bearbeitungszeit
Es misst die Zeit, die zum Transformieren oder Bearbeiten der Daten innerhalb der Pipeline benötigt wird.
Verarbeitungszeit = Zeit, die für die Transformation oder Verarbeitung eines Datensatzes benötigt wird
4. Ressourcennutzung
Die Ressourcennutzung misst, wie effizient die Pipeline während der Datenverarbeitung Rechenressourcen (CPU, Speicher usw.) nutzt.
Ressourcennutzung = (Tatsächliche Ressourcennutzung / Maximal verfügbare Ressourcen) * 100
Wichtige Designüberlegungen
Beim Einrichten einer Datenpipeline-Architektur ist es wichtig, bestimmte Faktoren und Best Practices zu berücksichtigen Erstellen Sie eine Datenpipeline-Architektur, die robust, skalierbar und einfach zu verwalten ist. So können Sie Ihre Datenpipeline gestalten:
Modularität: Das modulare Design fördert die Wiederverwendung von Code, vereinfacht die Wartung und ermöglicht einfache Aktualisierungen einzelner Komponenten. Teilen Sie die Pipeline in kleinere, unabhängige Module oder Dienste auf. Jedes Modul sollte eine klar definierte Verantwortung haben und die Kommunikation zwischen Modulen sollte standardisiert sein.
Fehlertoleranz: Durch die Integration der Fehlertoleranz in die Pipeline wird sichergestellt, dass sich das System nach Fehlern ordnungsgemäß erholen und die Datenverarbeitung fortsetzen kann. Implementieren Sie Wiederholen Sie Mechanismen für vorübergehende Fehler, verwenden Sie Prüfpunkte, um den Fortschritt zu verfolgen, und richten Sie Überwachung und Warnung bei abnormalen Bedingungen ein.
Orchestrierung: Orchestrierungstools helfen bei der Planung und Verwaltung des Datenflusses durch die Pipeline und stellen sicher, dass Aufgaben in der richtigen Reihenfolge mit den richtigen Abhängigkeiten ausgeführt werden. Sie können verwenden Werkzeuge wie Astera Centerprise bis dDefinieren Sie Workflows, die die logische Abfolge von Pipeline-Aktivitäten darstellen.
Parallelverarbeitung: Durch die parallele Verarbeitung kann die Pipeline große Datensätze effizienter verarbeiten, indem sie Arbeitslasten auf mehrere Ressourcen verteilt. Astera Centerprise unterstützt eine leistungsstarke Parallelverarbeitungs-ETL/ELT-Engine, die Sie für Ihre Datenpipelines verwenden können.
Datenpartitionierung: Stellen Sie sicher, dass Sie zeffiziente Datenpartitionierung als es Verbessert die Parallelität und Gesamtleistung durch die Verteilung von Datenverarbeitungsaufgaben auf mehrere Knoten. Zu den gängigen Techniken gehören Bereichspartitionierung, Hash-Partitionierung oder Listenpartitionierung.
Skalierbarkeit: Denken Sie immer an die Skalierbarkeit. Entwerfen Sie die Pipeline so, dass sie horizontal (Hinzufügen weiterer Instanzen) oder vertikal (Erhöhung der Ressourcen pro Instanz) skaliert werden kann. Nutzen Sie cloudbasierte Dienste für eine automatische Skalierung je nach Bedarf.
Versionskontrolle: Verwenden Sie Versionskontrollsysteme wie Git für Pipeline-Code und Konfigurationsdateien. Befolgen Sie Best Practices zum Verzweigen, Zusammenführen und Dokumentieren von Änderungen.
Testing: IImplementieren Sie Unit-Tests für einzelne Komponenten, Integrationstests für Workflows und End-to-End-Tests für die gesamte Pipeline. Schließen Sie Tests für ein Datenqualität und Randfälle. Strenge Tests werde sicherstellen dass die Pipeline zuverlässig funktioniert und stets den Geschäftsanforderungen entspricht.
Kontinuierliche Verbesserung der Datenpipeline-Architektur
Die Definition der Datenpipeline-Architektur ist kein einmaliger Prozess. Du musst behalten Identifizieren von Bereichen mit Verbesserungspotenzial, Implementieren von Änderungen und Anpassen der Architektur an sich ändernde Geschäftsanforderungen und technologische Fortschritte. Das Ziel besteht darin, sicherzustellen, dass die Datenpipeline robust und skalierbar bleibt und den sich ändernden Anforderungen der Organisation gerecht wird. Folgendes können Sie tun:
- Überwachen Sie regelmäßig die Leistung und den Gesundheitszustand der Datenpipeline. Verwenden Sie Überwachungstools, um Kennzahlen zur Ressourcennutzung, Datenverarbeitungszeiten, Fehlerraten und anderen relevanten Indikatoren zu erfassen. Analysieren Sie die gesammelten Daten, um Engpässe, Ineffizienzbereiche oder potenzielle Fehlerquellen zu identifizieren.
- Richten Sie Feedbackschleifen ein, die es Benutzern, Dateningenieuren und anderen Stakeholdern ermöglichen, Einblicke und Feedback zur Leistung und Funktionalität der Pipeline zu geben.
- Definieren Sie KPIs für die Datenpipeline und überprüfen Sie diese regelmäßig. Zu den wichtigsten Kennzahlen können Durchsatz, Latenz, Fehlerraten und Ressourcennutzung gehören. Verwenden Sie KPIs, um die Wirksamkeit der Datenpipeline zu bewerten und Verbesserungsbemühungen zu leiten.
- Implementieren Sie inkrementelle Verbesserungen, anstatt umfassende Überarbeitungen durchzuführen. Kleine, gezielte Verbesserungen sind einfacher zu verwalten und können kontinuierlich in die bestehende Pipeline integriert werden. Priorisieren Sie Verbesserungen basierend auf ihren Auswirkungen auf Leistung, Zuverlässigkeit und Benutzerzufriedenheit.
Astera Centerprise-Das codefreie automatisierte Datenpipeline-Tool
Astera Centerprise ist ein Datenpipeline-Tool ohne Code, das über eine visuelle und intuitive Benutzeroberfläche verfügt. Das Tool wurde unter Berücksichtigung der Zugänglichkeit für Geschäftsanwender entwickelt, sodass diese auch Datenpipelines erstellen können, ohne sich zu sehr auf die IT-Abteilung verlassen zu müssen. Möchten Sie mit der Selbstverwaltung von Datenpipelines mit hohem Datenvolumen beginnen? Probieren Sie es aus 14 Tage lang kostenlos.



