
Die automatisierte, Kein Code Datenstapel
Erfahren Sie, wie Astera Data Stack kann die Datenverwaltung Ihres Unternehmens vereinfachen und rationalisieren.

Was ist Data Warehousing? Konzepte, Funktionen und Beispiele
Im heutigen Geschäftsumfeld muss ein Unternehmen über zuverlässige Berichte und Analysen großer Datenmengen verfügen. Unternehmen müssen ihre Daten für verschiedene Aggregationsebenen sammeln und integrieren, vom Kundenservice über die Partnerintegration bis hin zu Geschäftsentscheidungen der obersten Ebene. Hier kommt Data Warehousing ins Spiel, um die Berichterstellung und Analyse zu erleichtern. Dieser Anstieg der Daten erhöht wiederum die Nutzung Data Warehouse um Geschäftsdaten zu verwalten.
Um die Bedeutung der Datenspeicherung zu verstehen, sehen wir uns die wichtigen Data-Warehousing-Konzepte an.
Was ist Data Warehousing?
Bei Data Warehousing werden Daten aus unterschiedlichen Datenquellen gesammelt, organisiert und verwaltet, um den jeweiligen Benutzern aussagekräftige geschäftliche Erkenntnisse und Prognosen zu liefern.
Die im DWH gespeicherten Daten unterscheiden sich von den in der Betriebsumgebung gefundenen Daten. Es ist so organisiert, dass relevante Daten geclustert werden, um den täglichen Betrieb, die Datenanalyse und die Berichterstattung zu erleichtern. Dadurch können Trends im Laufe der Zeit ermittelt werden und Benutzer können auf der Grundlage dieser Informationen Pläne erstellen. Dies unterstreicht die Bedeutung der Nutzung von Data Warehouses für Geschäftsentscheidungsträger.
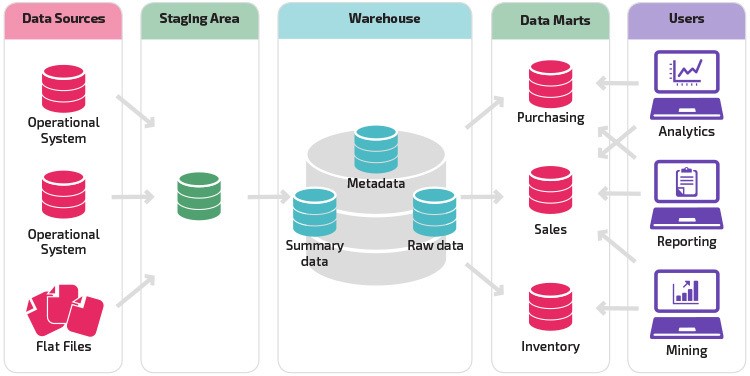
Data Warehouse-Architektur
Ansätze zur Kombination heterogener Datenbanken
Um verschiedene Datenbanken zu integrieren, gibt es zwei gängige Ansätze:
- Abfragegesteuert: Ein abfragegesteuerter Ansatz im Data Warehousing ist traditionell für die Erstellung von Integratoren und Wrappern auf der Grundlage verschiedener Datenbanken.
- Update-gesteuert: Ein aktualisierungsgesteuerter Ansatz zur Datenintegration ist eine Alternative zum abfragegesteuerten Ansatz und wird heute häufiger verwendet. Bei diesem Ansatz werden die Daten aus unterschiedlichen Quellen vorab zusammengeführt bzw. integriert und in einem Data Warehouse gespeichert. Später können Mitarbeiter auf diese Daten für Abfragen und Datenanalysen zugreifen.
Data Warehouse-Architektur
A Data Warehouse-Architektur verwendet dimensionale Modelle, um die beste Technik zum Extrahieren und Übersetzen von Informationen aus Rohdaten zu ermitteln. Beim Entwurf eines Echtzeit-Data-Warehouses auf Unternehmensebene sollten Sie jedoch drei Hauptarchitekturtypen berücksichtigen.
- Einstufige Architektur
- Zweistufige Architektur
- Dreistufige Architektur
Aktivieren der Funktionen
Zu den Hauptmerkmalen eines Data Warehouse gehören die folgenden:
- Fachorientiert: Es stellt Informationen bereit, die sich auf ein bestimmtes Thema beziehen, und nicht auf den laufenden Betrieb der Organisation. Beispiele für Themen sind Produktinformationen, Verkaufsdaten, Kunden- und Lieferantendetails usw.
- Integriert: Es wird durch die Kombination von Daten aus mehreren Quellen, wie z. B. Flatfiles und relationalen Datenbanken, entwickelt.
- Zeitunterschied: Die Daten in einem DWH liefern Informationen zu einem bestimmten historischen Zeitpunkt. Daher werden die Daten innerhalb eines bestimmten Zeitrahmens kategorisiert.
- Nicht flüchtig: Nichtflüchtig bezieht sich auf historische Daten, die nicht weggelassen werden, wenn neuere Daten hinzugefügt werden. Ein DWH ist von einer Betriebsdatenbank getrennt. Dies bedeutet, dass regelmäßige Änderungen in der Betriebsdatenbank nicht im Data Warehouse sichtbar sind.
Die Rolle von Datenpipelines im EDW
Viel Mühe steckt drin die wahre Kraft freisetzen Ihres Data Warehouse. Sie können zuverlässig, flexibel und mit geringer Latenz bauen ETL-Pipelines unter Verwendung einer Metadaten-gesteuerten ETL Ansatz.
Ein Data Warehouse wird mit gefüllt Datenpipelines. Sie transportieren Rohdaten aus unterschiedlichen Quellen zur Berichterstellung und Analyse in ein zentrales Data Warehouse. Dabei werden die Daten transformiert und optimiert.
Allerdings hat die Zunahme von Volumen, Geschwindigkeit und Vielfalt den traditionellen Ansatz zum Aufbau von Datenpipelines beeinträchtigt —mit manueller Codierung und Neukonfiguration - unwirksam und veraltet.
Automation ist ein wesentlicher Bestandteil für den Aufbau effizienter Datenpipelines, die der Agilität und Geschwindigkeit Ihrer Geschäftsprozesse entsprechen.
Automatisierung der Datenpipeline
Mithilfe der Datenpipeline-Automatisierung können Sie Daten nahtlos von der Quelle zur Visualisierung transportieren. Es handelt sich um einen modernen Ansatz zur Befüllung von Data Warehouses und erfordert die Gestaltung funktionaler und effizienter Datenflüsse.
Wie wir alle wissen, ist Aktualität eines der entscheidenden Elemente hochwertiger Business Intelligence. Automatisierte Datenpipelines helfen Ihnen, Daten schnell im Data Warehouse verfügbar zu machen.
Sie können veraltete, triviale oder duplizierte Daten eliminieren, indem Sie die Leistungsfähigkeit automatisierter und skalierbarer Datenpipelines nutzen. Dies maximiert die Datenzugänglichkeit und -konsistenz, um qualitativ hochwertige Analysen sicherzustellen.
Mit einem metadatengesteuerten ETL-Prozess können Sie neue Quellen nahtlos in Ihre Architektur integrieren und iterative Zyklen unterstützen, um Ihre BI-Berichterstellung und -Analyse zu beschleunigen.
Außerdem können Sie dem folgen ELT Ansatz. In ELT können Sie die Daten direkt in das Lager laden, um die Rechenkapazität des Zielsystems für die Ausführung zu nutzen Datentransformationen effizient.
Optimierung von Datenpipelines
Ein Unternehmen muss sich auf den Aufbau automatisierter Datenpipelines konzentrieren, die sich dynamisch an sich ändernde Umstände anpassen können – beispielsweise das Hinzufügen und Entfernen von Datenquellen oder das Ändern von Transformationen.
Natürlich kann es sehr ineffizient sein, ganze Datenbanken zu verschieben, wenn Sie Daten für Berichte oder Analysen benötigen.
Am besten laden Sie Daten inkrementell mit Datenerfassung ändern um Ihr Data Warehouse zu füllen. Es hilft, Redundanzen zu eliminieren und sorgt für maximale Datengenauigkeit.
Weitere wesentliche Funktionen, die zum Erstellen automatisierter Datenpipelines erforderlich sind, sind inkrementelles Laden, Jobüberwachung und Jobplanung.
- Durch inkrementelles Laden wird sichergestellt, dass Sie nicht jedes Mal, wenn sich die Quelltabelle ändert, alle Daten in Ihr Data Warehouse kopieren müssen. Dadurch wird sichergestellt, dass Ihr Data Warehouse immer korrekt und aktuell ist.
- Die Auftragsüberwachung hilft Ihnen, etwaige Probleme mit Ihrem aktuellen System zu verstehen und den Prozess zu optimieren.
- Durch die Jobplanung können Benutzer Daten täglich, wöchentlich, monatlich oder nur dann verarbeiten, wenn die Daten bestimmte Auslöser oder Bedingungen erfüllen.
Die Orchestrierung und Automatisierung Ihrer Datenpipelines kann manuelle Arbeit eliminieren, Reproduzierbarkeit einführen und die Effizienz maximieren.
Beispiele für Data Warehousing in verschiedenen Branchen
Big Data ist für uns von entscheidender Bedeutung geworden Data Warehousing und Business Intelligence über mehrere Branchen hinweg. Sehen wir uns einige Beispiele für Data Warehousing in verschiedenen Branchen an.
Investment- und Versicherungssektor
Unternehmen nutzen ein Data Warehouse vor allem zur Analyse von Kunden- und Markttrends und anderen Datenmustern in diesen Branchen. Devisen- und Aktienmärkte sind zwei wichtige Teilsektoren. Dabei spielen Data Warehouses eine entscheidende Rolle, denn ein einziger Punkt Unterschied kann auf breiter Front zu massiven Verlusten führen. DWHs werden in der Regel in diesen Sektoren gemeinsam genutzt und konzentrieren sich auf das Echtzeit-Datenstreaming.
Einzelhandelsketten
Einzelhandelsketten nutzen DWHs für Vertrieb und Marketing. Häufige Verwendungszwecke sind die Verfolgung von Artikeln, die Prüfung von Preisrichtlinien, die Verfolgung von Sonderangeboten und die Analyse von Kauftrends von Kunden. Einzelhandelsketten integrieren in der Regel EDW-Systeme für Business-Intelligence- und Prognoseanforderungen.
Gesundheitswesen
Unternehmen im Gesundheitswesen nutzen ein DWH, um Patientenergebnisse vorherzusagen. Sie verwenden es auch, um Behandlungsberichte zu erstellen und Daten mit Versicherungsanbietern, Forschungslabors und anderen medizinischen Einheiten auszutauschen. EVWs sind das Rückgrat der Gesundheitssysteme, da die neuesten, aktuellen Behandlungsinformationen für die Rettung von Leben von entscheidender Bedeutung sind.
Arten von Data Warehouses
Es gibt drei Haupttypen von Data Warehouses. Jeder hat seine spezifische Rolle Datenmanagement Operationen.
1- Enterprise Data Warehouse
Ein Enterprise Data Warehouse (EDW) ist eine zentrale Datenbank zur Erleichterung von Entscheidungen im gesamten Unternehmen. Zu den wichtigsten Vorteilen eines EDW gehören:
- Zugriff auf organisationsübergreifende Informationen.
- Die Fähigkeit, komplexe Abfragen auszuführen.
- Die Ermöglichung bereicherter, weitsichtiger Erkenntnisse für datengesteuerte Entscheidungen und eine frühzeitige Risikobewertung.
2- ODS (Betriebsdatenspeicher)
In ODS wird das DWH in Echtzeit aktualisiert. Daher verwenden Organisationen es häufig für routinemäßige Unternehmensaktivitäten, beispielsweise zum Speichern von Mitarbeiterdaten. Auch Geschäftsprozesse nutzen ODS, um dem EDW Daten bereitzustellen.
3- Datenmarkt
Es handelt sich um eine Teilmenge eines DWH, die eine bestimmte Abteilung, Region oder Geschäftseinheit unterstützt. Bedenken Sie Folgendes: Sie haben mehrere Abteilungen, darunter Vertrieb, Marketing, Produktentwicklung usw. Jede Abteilung verfügt über ein zentrales Repository, in dem sie Daten speichert. Dieses Repository ist ein Datamart.
Das EDW speichert die Daten aus dem Data Mart täglich/wöchentlich (oder wie konfiguriert) im ODS. Das ODS fungiert als Bereitstellungsbereich für Datenintegration. Anschließend werden die Daten zur Speicherung für BI-Zwecke an das EDW gesendet.
Lager in 4 einfachen Schritten
Warum brauchen Unternehmen Data Warehousing und Business Intelligence?
Viele Geschäftsanwender fragen sich, warum Data Warehousing so wichtig ist. Der einfachste Weg, dies zu erklären, ist durch die verschiedenen Vorteile für die Endbenutzer. Diese schließen ein:
- Verbesserter Endbenutzerzugriff auf eine Vielzahl von Unternehmensdaten
- Erhöhte Datenkonsistenz
- Zusätzliche Dokumentation der Daten
- Potenziell niedrigere Rechenkosten und höhere Produktivität
- Bereitstellung eines Ortes zum Kombinieren verwandter Daten aus verschiedenen Quellen
- Schaffung einer Computerinfrastruktur, die Änderungen in Computersystemen und Geschäftsstrukturen unterstützen kann
- Endbenutzer können Ad-hoc-Abfragen oder Berichte ausführen, ohne die Leistung der Betriebssysteme zu beeinträchtigen
Tools und Techniken für das Data Warehousing
Die Dateninfrastruktur der meisten Organisationen ist eine Sammlung verschiedener Systeme. Beispielsweise könnte eine Organisation über ein einziges System verfügen, das Kundenbeziehungen, Personalwesen, Vertrieb, Produktion, Finanzen, Partner usw. verwaltet. Diese Systeme sind oft schlecht oder überhaupt nicht integriert. Dies macht es schwierig, einfache Fragen zu beantworten, obwohl die Informationen „irgendwo“ im Internet verfügbar sind unterschiedliche Datensysteme.
Unternehmen können DWH-Tools nutzen, um diese Probleme zu lösen, indem sie eine einzige Datenbank mit homogenen Daten erstellen. Die Softwaretools für Extrahieren und die Umwandlung der Daten in ein homogenes Format zum Laden in das DWH sind ebenfalls wichtige Bestandteile eines Data-Warehousing-Systems.
Enterprise Data Warehousing Automation Tool von Astera Software
Astera Data Warehouse Builder beschleunigt die Entwicklung eines Data Warehouse von Grund auf. Es unterstützt zahlreiche Integrationen, automatisiert die Datenmodellierung und liefert ein leistungsstarkes DWH über eine einheitliche, intuitive Plattform.
ADWB ist metadatengesteuert Data-Warehousing-Automatisierungstool mit einem umfangreichen Datenmodellierer und umfasst alle oben genannten Schlüsselfunktionen eines Data Warehouse. Die Reverse-Engineering-Funktionalität ermöglicht es Benutzern, Datenbanken mit wenigen Klicks zu erstellen, ohne Codes schreiben zu müssen. Ebenso können Benutzer mit der einfachen Drag-and-Drop-Option schnell Schemata von Grund auf entwickeln. Die folgenden Bilder zeigen kurz die Funktionsweise des ADWB.
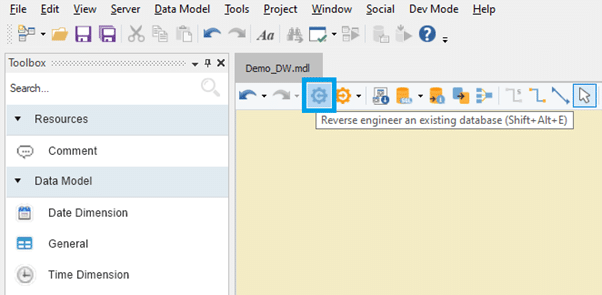
Reverse-Engineering-Funktion in Astera DWB
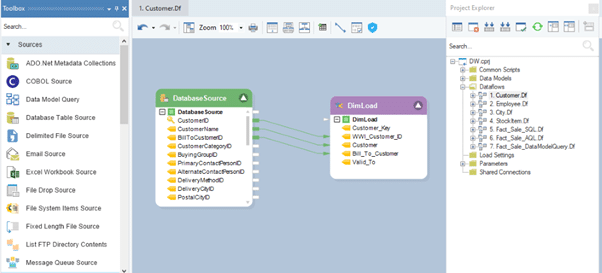
Datenfluss zum Auffüllen der Dimensionstabelle in ADWB
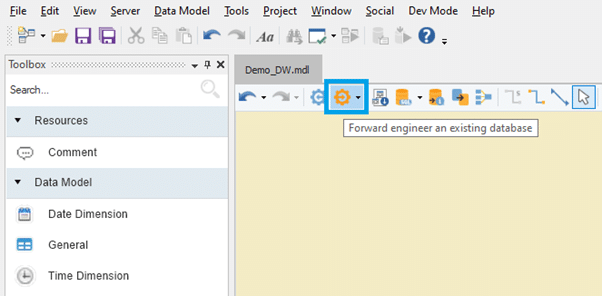
Sobald das Schema erstellt und die Daten ausgefüllt sind, kann das Datenmodell genauso schnell für die Datenbank des Unternehmens nach vorne entwickelt werden.
Erfahren Sie mehr darüber So erstellen Sie Ihr Data Warehouse von Grund auf mit Astera Data Warehouse Builder, eine leistungsstarke Lösung, die alle Ihre Geschäftsanforderungen erfüllt.
Wenn Sie Ihren Anwendungsfall besprechen oder eine Live-Demo des Produkts sehen möchten, lassen Sie es uns wissen, und unsere Experten werden sich mit Ihnen in Verbindung setzen.



