
Die automatisierte, Kein Code Datenstapel
Erfahren Sie, wie Astera Data Stack kann die Datenverwaltung Ihres Unternehmens vereinfachen und rationalisieren.

ETL vs. ELT: Was ist besser? Der ultimative Leitfaden (2024)
ETL (Extrahieren, Transformieren, Laden) ist seit einigen Jahrzehnten der traditionelle Ansatz für Datenanalyse und Warehousing. Allerdings haben wir heute auch die Möglichkeit dazu ELT (Extrahieren, Laden, Transformieren) ein alternativer Ansatz zur Datenverarbeitung. Seit der Einführung von ELT gab es immer eine Debatte darüber, welcher Ansatz der bessere ist.
Das Ziel dieses Blogs ist es, die Debatte zwischen ETL und ELT ein für alle Mal zu beenden.
ETL vs. ELT: Showdown
ETL und ELT sind beide wichtig Datenintegration Strategien mit unterschiedlichen Wegen zum gleichen Ziel: Daten für Entscheidungsträger zugänglich und umsetzbar zu machen. Obwohl beide eine zentrale Rolle spielen, können ihre grundlegenden Unterschiede erhebliche Auswirkungen auf die Datenverarbeitung, -speicherung und -analyse haben.
Lassen Sie uns zunächst untersuchen, was passiert, wenn „T“ und „L“ vertauscht werden.
Was ist ETL?
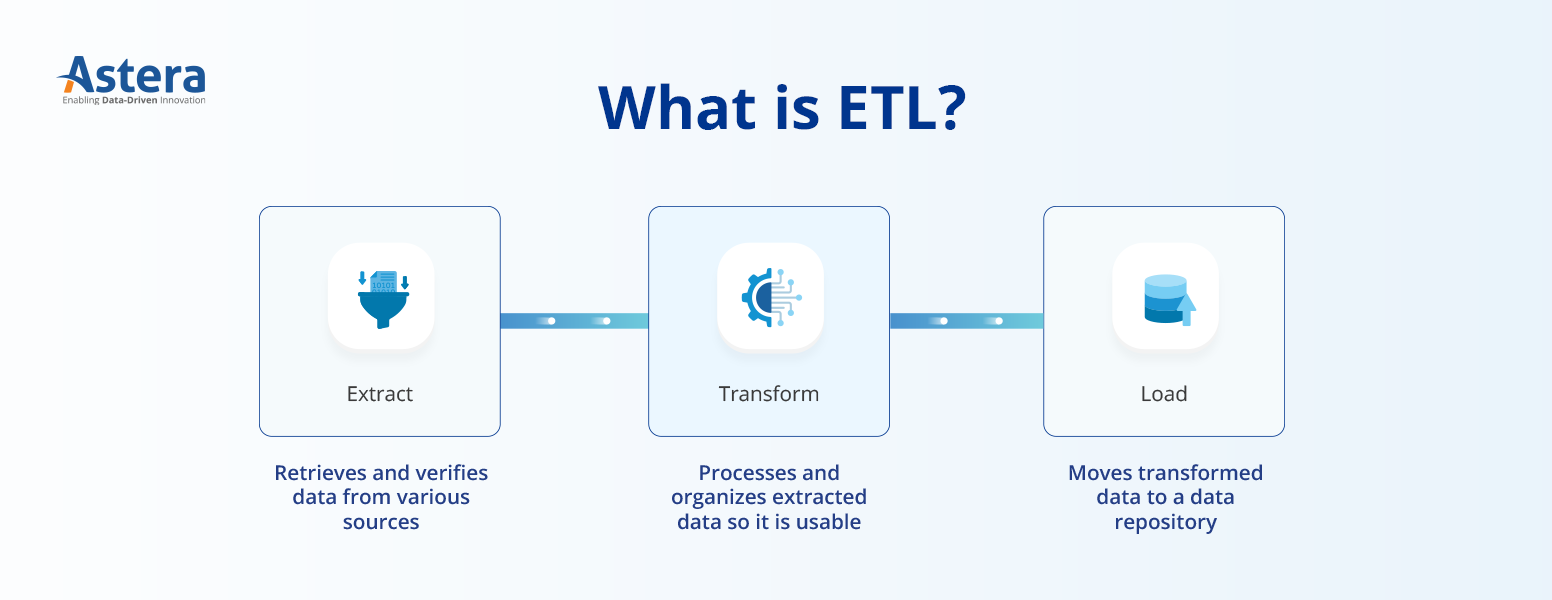
Bevor Sie sich zwischen ETL und ELT entscheiden, ist es wichtig, die Bedeutung der einzelnen Begriffe zu verstehen.
Damit Was ist ETL??
ETL ist traditionell ein wichtiger Schritt im Datenintegrationsprozess, der dabei hilft, Daten aus unterschiedlichen Datenquellen an das Ziel zu übertragen.
ETL beginnt mit dem Extrahieren von Daten aus verschiedenen Quellen in einen Staging-Bereich. Diese Daten sind möglicherweise nicht immer einheitlich und liegen oft in unterschiedlichen Formaten vor. Die direkte Übertragung dieser Daten an das Ziel führt häufig zu Fehlern. Daher ist es am besten, sie zu bereinigen und zu validieren, damit nur qualitativ hochwertige Daten das Endziel erreichen.
Nach der Transformation werden die bereinigten Daten in die angegebenen Ziele geladen.
ETL ist in modernen Business-Intelligence-Prozessen von entscheidender Bedeutung, da es die Integration roher strukturierter oder unstrukturierter Daten aus verschiedenen Quellen an einem Ort ermöglicht, um geschäftliche Erkenntnisse zu gewinnen.
Manche Leute stellen oft die Frage, „Ist ETL veraltet?“
Die Antwort darauf hängt von den Anforderungen einer Organisation ab, z. B. wie viele Datensysteme vorhanden sind, ob diese Daten transformiert werden müssen, ob zeitnaher Zugriff auf die zusammengestellten Daten erforderlich ist usw.
Bevor wir näher darauf eingehen, wann ETL die bessere Wahl ist, sollten wir zunächst verstehen, was ELT ist.
Was ist ELT?
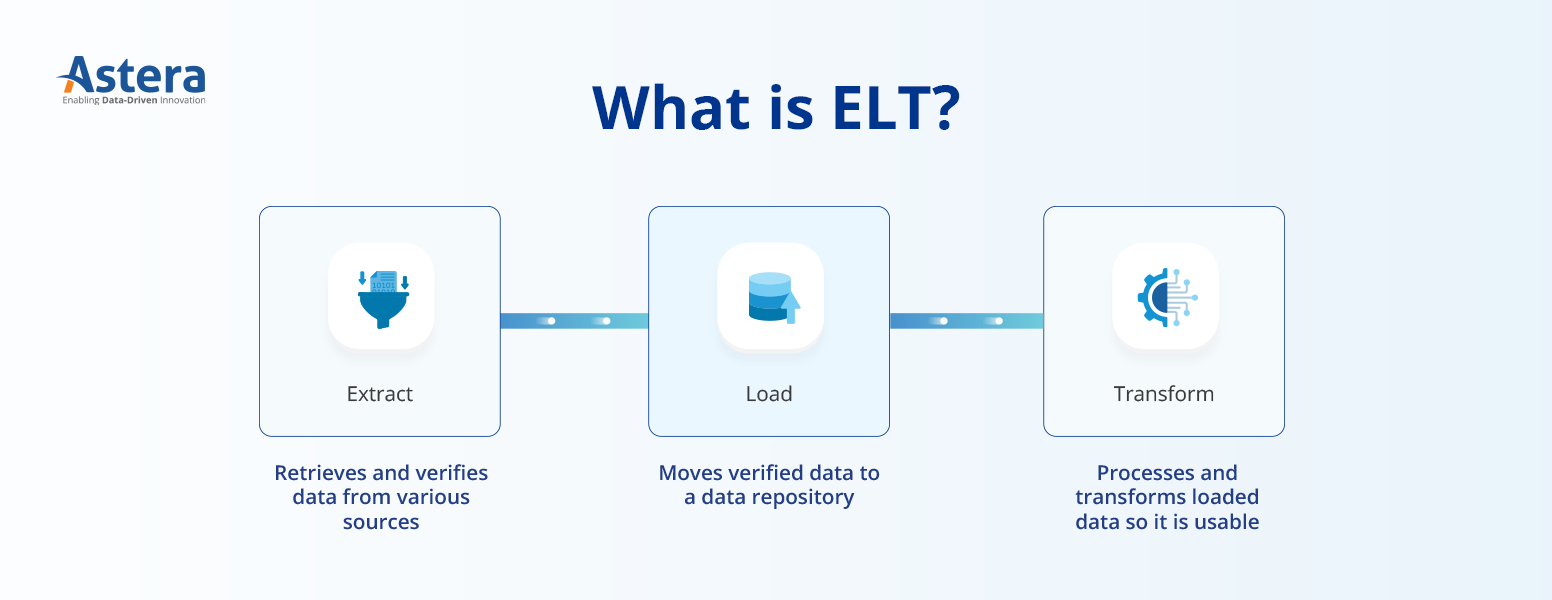
ELTs Die Bedeutung unterscheidet sich stark von ETL. Die Anfangsphase von ELT funktioniert auf die gleiche Weise wie ETL, was bedeutet, dass Rohdaten zunächst aus verschiedenen Datenquellen extrahiert werden. Im Gegensatz zu ETL, bei dem Daten zunächst transformiert werden, bevor sie geladen werden, werden die Daten bei ELT direkt in das Ziel geladen und dann innerhalb des Ziels transformiert, z Data Warehouse.
Der Hauptvorteil dieses Ansatzes besteht darin, dass Datenbenutzer jederzeit problemlos auf alle Rohdaten zugreifen können.
Es ist wichtig zu beachten, dass BI-Tools Big Data nicht nutzen können, ohne sie zu verarbeiten. Der nächste Schritt besteht also darin, die Daten zu bereinigen und zu standardisieren. Das ETL-Warehouse normalisiert die gespeicherten Daten für die Erstellung benutzerdefinierter Dashboards und Geschäftsberichte.
Im Vergleich zu ETL reduziert ELT die Ladezeit erheblich. Darüber hinaus ist ELT eine ressourceneffizientere Methode, da es die Verarbeitungsfähigkeiten des Ziels nutzt.
ELT eignet sich besser für Cloud-Datenbanken, Speicherplattformen und Data Warehouses wie z Schneeflocke or Amazon RedShift weil diese Plattformen die Kapazität haben, Rohdaten in großen Mengen zu speichern.
ETL-Prozess vs. ELT-Prozess
ETL-Prozess
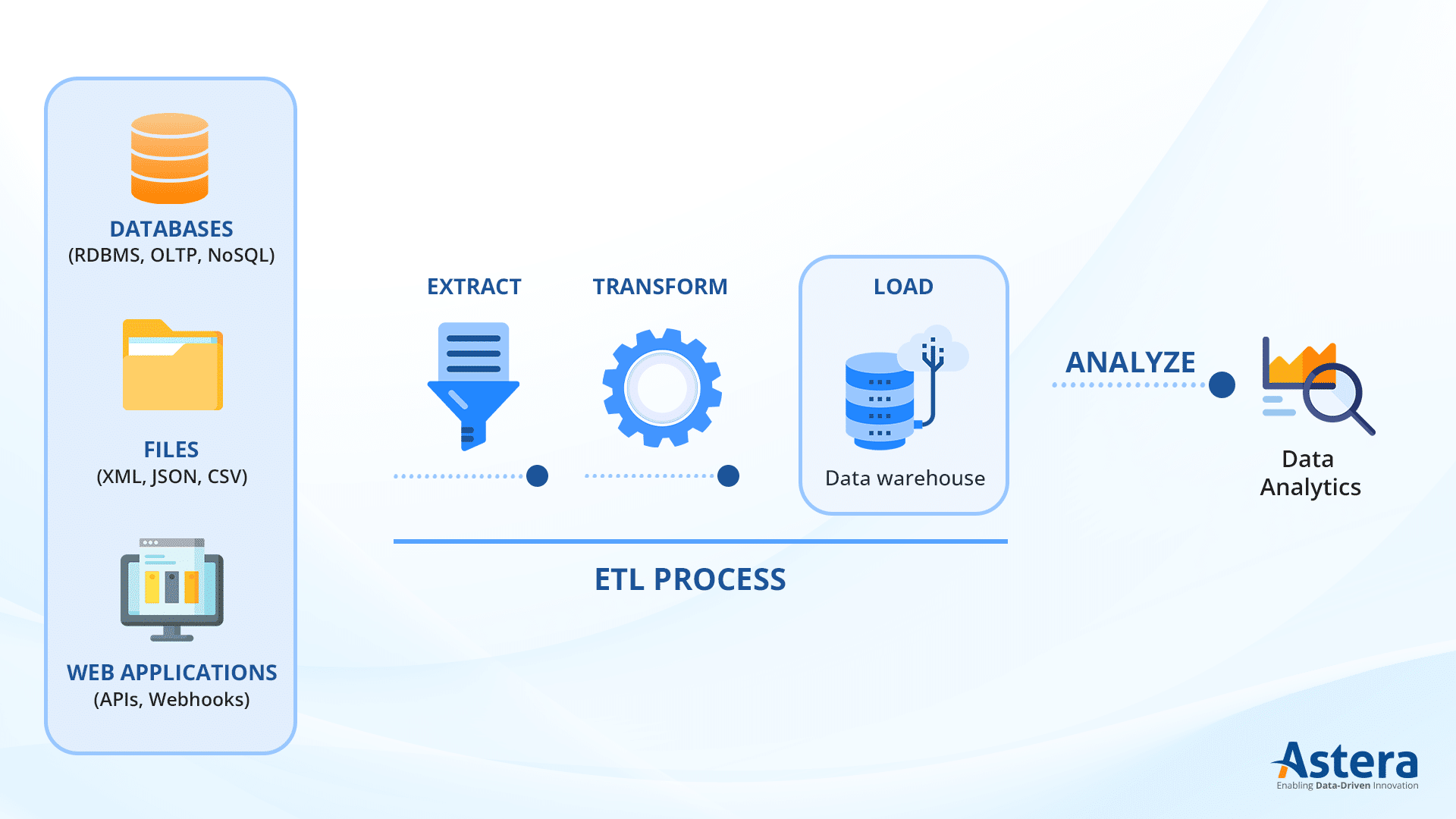
An ETL-Prozess kann für verschiedene Anwendungsfälle wie Datenmigration, Integration oder einfach nur Datenreplikation verwendet werden.
Unabhängig davon beginnt der grundlegende Prozess mit der Datenextraktion, bei der Daten aus unterschiedlichen Quellen extrahiert und dann zur Transformation in einen Staging-Bereich verschoben werden. Nun gibt es je nach Anwendungsfall verschiedene Arten von Transformationen, die auf diese Daten angewendet werden können. Wenn die Daten beispielsweise aus zwei verschiedenen Quellen stammen, werden sie durch eine Join-Transformation kombiniert.
Die Daten müssen außerdem bereinigt und validiert werden, bevor sie an das endgültige Ziel gesendet werden.
Sobald dies erledigt ist, wird es schließlich in das Ziel geladen, bei dem es sich entweder um eine andere Datenbank oder ein Warehouse handeln kann. Benutzer können aus mehreren Optionen wählen, hauptsächlich Volllast und inkrementeller Last. Beim Vollladen werden alle Daten auf einmal geladen, während bei der zweiten Option die Daten stapelweise hochgeladen werden.
Dadurch entsteht eine organisierte Pipeline mit einer klaren Reise für die Daten von Punkt A nach Punkt B.
ELT-Prozess
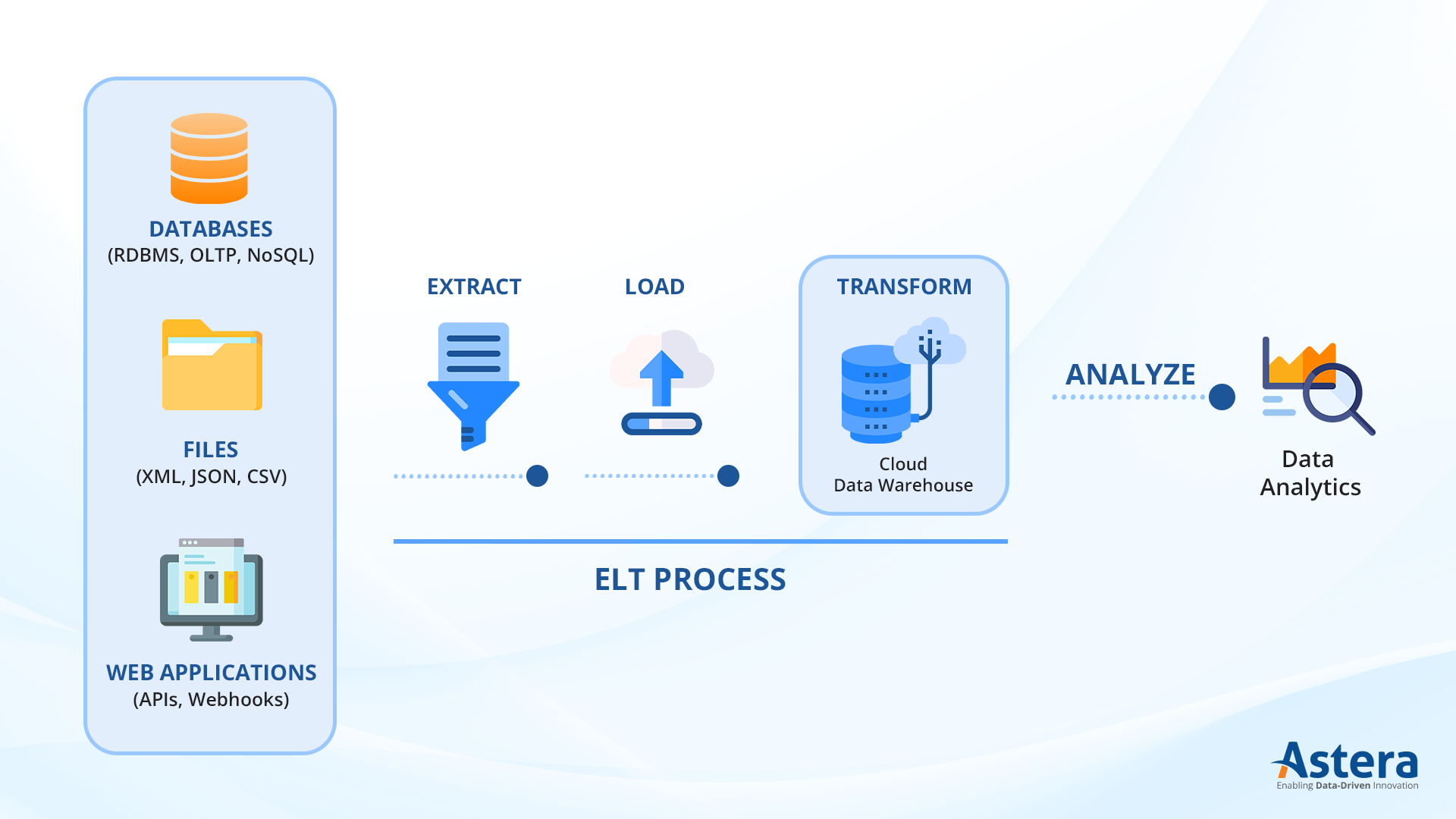
Der ELT-Prozess beginnt auf die gleiche Weise wie der ETL, also mit der Datenextraktion. Sobald die Daten extrahiert wurden, werden sie in einen Staging-Bereich verschoben, bei dem es sich um einen temporären Speicherort innerhalb des Zielsystems oder ein separates Speichersystem handeln kann. Staging ist für die Datenvalidierung und die Sicherstellung der Datenkonsistenz vor dem Laden in das Ziel-Repository von entscheidender Bedeutung.
Der nächste Schritt besteht darin, das Schema für die Datentabellen im Ziel-Repository zu definieren. In diesem Schritt müssen Benutzer Tabellen erstellen und Spaltendatentypen definieren. Die Daten werden dann mithilfe von Tools und Technologien wie SQL-basierten Ladeskripten in das Ziel-Repository geladen. Datenpipelines, oder codefreie ELT-Tools wie Astera Centerprise.
ETL vs. ELT-Architektur: 8 Hauptunterschiede
Schauen wir uns einige der wichtigsten Unterschiede zwischen beiden Ansätzen an.
-
Verwandlungsprozess
Die Reihenfolge des Transformationsprozesses ist ein wesentlicher Unterschied zwischen ELT und ETL. Der ETL-Ansatz verarbeitet und transformiert Daten vor dem Laden. Alternativ transformieren ELT-Tools Daten nicht direkt nach der Extraktion. Stattdessen laden sie die Daten unverändert in das Warehouse. Datenanalysten können die benötigten Daten auswählen und vor der Analyse umwandeln.
-
Datengröße
Ein wesentlicher Unterschied zwischen ETL und ELT ist die Datengröße. ETL-Warehouses funktionieren am besten mit kleineren Datensätzen. ELT-Systeme können jedoch große Datenmengen verarbeiten.
-
Datenladezeit
Die ETL- und die ELT-Architektur unterscheiden sich auch hinsichtlich der Gesamtwartezeit für die Übertragung der Rohdaten in das Ziel-Warehouse. ETL ist ein zeitaufwändiger Prozess, da Datenteams es zur Transformation zunächst in einen Zwischenraum laden müssen. Danach lädt das Datenteam die verarbeiteten Daten in das Ziel.
Die ELT-Architektur bietet Unterstützung für unstrukturierte Daten. Dadurch entfällt die Notwendigkeit einer Transformation vor dem Laden. So können Benutzer direkt in ein Data Warehouse übertragen, was ELT weniger zeitaufwändig macht.
-
Datenanalysezeit
Ein weiterer Unterschied zwischen ETL und ELT ist die Zeit, die für die Durchführung der Analyse benötigt wird. Da Daten in einem ETL-Warehouse transformiert werden, können Datenanalysten sie ohne Verzögerungen analysieren. Die in einem ELT-Warehouse vorhandenen Daten werden jedoch nicht transformiert. Daher müssen Datenanalysten sie bei Bedarf umwandeln. Dieser Ansatz erhöht die Wartezeit für die Datenanalyse.
-
Compliance
Cyberangriffe betroffen 155.8 Millionen US-Bürger allein im Jahr 2020. Um das Risiko eines Datendiebstahls zu verringern, müssen Unternehmen CCPA, DSGVO, HIPAA und andere Datenschutzbestimmungen befolgen. Aus diesem Grund ist Compliance ein entscheidender Faktor in der Debatte zwischen ETL und ELT.
ETL-Tools Entfernen Sie vertrauliche Informationen, bevor Sie sie in das Lager laden. Dadurch wird ein unbefugter Zugriff auf die Daten verhindert. Andererseits laden ELT-Tools den Datensatz in das Warehouse, ohne vertrauliche Informationen zu entfernen. Daher sind diese Daten anfälliger für Sicherheitsverletzungen.
-
Unterstützung unstrukturierter Daten
Die Unterstützung unstrukturierter Daten ist ein weiterer wichtiger Unterschied zwischen ETL und ELT. Die ETL-Integration ist mit der relationalen kompatibel Datenbankmanagementsystem. Daher werden keine unstrukturierten Daten unterstützt. Mit anderen Worten: Sie können unstrukturierte Daten nicht integrieren, ohne sie zu transformieren.
Der ELT-Prozess ist frei von solchen Einschränkungen. Es kann übertragen werden strukturierte und unstrukturierte Daten problemlos ins Lager.
-
Komplexität der Transformation
Ein weiterer Unterschied ist die Komplexität der Transformation. Der ELT-Ansatz ermöglicht die Übertragung großer Datenmengen an das Ziel. Allerdings können Sie bestimmte erweiterte Transformationen, wie z. B. bestimmte Namenstypen oder Adressanalysen, nicht in die zugrunde liegende Datenbank übertragen. Daher müssen sie auf dem Staging-Server ausgeführt werden. Dies kann mitunter zu einem „Datensumpf“ führen. Es ist eine Herausforderung, diese an einem Ort gespeicherten Massendaten manuell zu sortieren und zu bereinigen.
Der traditionelle ETL-Ansatz macht den Prozess viel einfacher. Dies liegt daran, dass Sie Daten in Stapeln bereinigen können, bevor Sie sie laden.
-
Verfügbarkeit von Tools und Experten
Aus Astera Centerprise zu SSIS und Informatica PowerCenter, eine Vielzahl unterschiedlicher Arten von ETL-Tools sind auf dem Markt erhältlich. Da diese Technologie schon seit Jahrzehnten existiert, können Unternehmen diese effektiven Tools optimal nutzen. Für ELT, eine relativ neue Technologie, können wir das jedoch nicht sagen. Daher stehen nur begrenzte ELT-Ressourcen und -Tools zur Verfügung, um die Kundenanforderungen zu erfüllen. Darüber hinaus sind auf dem Markt zahlreiche ETL-Experten verfügbar, während die Belegschaft für ELT-Experten knapp ist.
Die folgende Tabelle zeigt einige zusätzliche Unterschiede.
| Vergleichsparameter | ETL | ELT |
| Einfache Einführung | ETL ist ein gut entwickeltes Verfahren, das seit über 20 Jahren verwendet wird, und ETL-Experten sind leicht verfügbar. | ELT ist eine neue Technologie, daher kann es schwierig sein, Experten zu finden und eine ELT-Pipeline zu entwickeln. |
| Datengröße | ETL eignet sich besser für den Umgang mit ähnlichen Datensätzen, die komplexe Transformationen erfordern. | ELT eignet sich besser für den Umgang mit großen Mengen strukturierter und unstrukturierter Daten. |
| Reihenfolge des Prozesses | Datentransformationen finden nach der Extraktion im Staging-Bereich statt. Nach der Transformation werden die Daten in das Zielsystem geladen. | Daten werden extrahiert, in das Zielsystem geladen und anschließend transformiert. |
| Verwandlungsprozess | Der Bereitstellungsbereich befindet sich auf der ETL-Lösungen Server. | Der Staging-Bereich befindet sich in der Quell- oder Zieldatenbank. |
| Ladezeit | Die Ladezeiten bei ETL sind länger als bei ELT, da es sich um einen mehrstufigen Prozess handelt: (1) Daten werden in den Staging-Bereich geladen, (2) Transformationen finden statt, (3) Daten werden in das Data Warehouse geladen. | Das Laden der Daten erfolgt schneller, da nicht auf Transformationen gewartet werden muss und die Daten nur einmal in das Zielsystem geladen werden. |
ETL vs. ELT: Vor- und Nachteile
Werfen wir einen Blick auf einige bemerkenswerte Vor- und Nachteile:
Vorteile einer ETL-Pipeline
- ETL-Pipelines eignen sich in der Regel am besten für die Datenbereinigung, -validierung und -transformation vor dem Laden von Daten in ein Zielsystem.
- Mit ETL-Pipelines können Sie Ihre Daten aus mehreren Quellsystemen problemlos in einem einzigen, konsistenten Format zusammenfassen.
- Sie können aktuelle Datenquellenplattformen beibehalten, ohne sich Gedanken über die Datensynchronisierung machen zu müssen, da ETL keine gemeinsame Unterbringung von Datensätzen erfordert.
- Der ETL-Prozess extrahiert große Mengen an Metadaten und kann auf SMP- oder MPP-Hardware ausgeführt werden, die ohne Leistungskonflikte mit der Datenbank effizienter verwaltet und genutzt werden kann.
- Mit ETL-Pipelines können Sie komplexe Datentransformationen anwenden. Wenn Ihre Daten eine komplizierte Geschäftslogik oder erhebliche Änderungen in der Datenstruktur erfordern, bevor sie verwendet werden können, bietet ETL eine besser kontrollierte Umgebung für diese Transformationen.
- ETL reduziert die Komplexität und den Ressourcenbedarf von Analysen erheblich, da Transformationen angewendet werden, bevor Daten in ein Zielsystem geladen werden.
- Sie können ETL-Pipelines entwerfen, um sowohl Batch- als auch Echtzeit-Datenintegration zu verarbeiten und die Flexibilität bei der Datenverarbeitung basierend auf spezifischen Anforderungen zu nutzen.
Nachteile von ETL
- Die langfristige Wartung von ETL-Pipelines kann eine Herausforderung sein. Da sich Datenquellen weiterentwickeln und sich Geschäftsanforderungen ändern, muss die ETL-Logik regelmäßig aktualisiert und getestet werden.
- If Datenqualität Werden Probleme während des ETL-Prozesses nicht erkannt und behoben, können sie sich auf nachgelagerte Systeme ausbreiten und zu falschen Analysen und Entscheidungen führen.
- Es besteht das Risiko, dass Daten verloren gehen oder Informationen weggelassen werden, wenn Transformationsregeln nicht sorgfältig entworfen und getestet werden.
- Der ETL-Prozess kann ressourcenintensiv sein und insbesondere bei großen Datensätzen erhebliche Rechenleistung und Speicherkapazität erfordern.
Vorteile einer ELT-Pipeline
- Mit ELT sind Sie flexibler, da Sie rohe, unverarbeitete Daten in einem Data Warehouse oder Data Lake speichern und für verschiedene Zwecke und Analysen verwenden können.
- Der ELT-Ansatz priorisiert das Laden von Daten gegenüber der Datentransformation. Dadurch können Daten schnell in das Zielsystem geladen werden und stehen schneller für die Analyse zur Verfügung.
- ELT eignet sich am besten für unstrukturierte Daten, da es den Schema-on-Read-Ansatz verwendet, bei dem Sie Daten ohne strenge Schemaanforderungen erfassen können
- ELT-Pipelines bilden die Grundlage für fortgeschrittene Analyse-, maschinelles Lern- und Data-Science-Projekte, da sie Datenwissenschaftlern den Zugriff auf Rohdaten und deren Bearbeitung ermöglichen, um Modelle und Erkenntnisse zu erstellen.
- ELT-Pipelines können ETL-Prozesse (Extrahieren, Transformieren, Laden) vereinfachen, indem sie komplexe Datentransformationen in das Ziel-Data-Warehouse verlagern.
- Das Beste an ELT-Pipelines ist, dass das Risiko eines Datenverlusts nicht geringer ist, da die Rohdaten direkt in das Zielsystem geladen werden.
Nachteile von ELT
- ELT-Pipelines können ein Unternehmen an bestimmte Data-Warehousing-Lösungen binden, was möglicherweise zu einer Anbieterbindung und eingeschränkter Flexibilität führt.
- Transformationen werden für verschiedene analytische Anwendungsfälle wiederholt, was möglicherweise zu Redundanz beim Datenverarbeitungsaufwand führt.
- In ein Data Warehouse geladene Rohdaten sind möglicherweise weniger zugänglich und für Geschäftsanwender und Datenanalysten schwieriger zu verarbeiten, was einen höheren Aufwand für die Erstellung benutzerfreundlicher Ansichten und Transformationen bedeutet.
- ELT-Pipelines umfassen häufig keine umfassenden Datenqualitätsprüfungen und -transformationen, bevor Daten in das Zielsystem geladen werden, was zusätzliche Tools oder Unterstützung erfordert Datenqualitätsmanagement.
- ELT verlässt sich häufig auf Data-Warehousing-Lösungen, deren Betrieb kostspielig sein kann, insbesondere beim Umgang mit großen Datensätzen, da Speicherkosten, Lizenzgebühren und Infrastrukturkosten schnell in die Höhe schnellen können
ETL vs. ELT: Welches ist die bessere Datenverwaltungsstrategie?
Es gibt keinen klaren Schnitt“better Strategie". Welchen Ansatz Sie wählen, hängt von Ihren spezifischen Anforderungen ab Datenmanagement Anforderungen. Hier wäre ETL eine bessere Option im Vergleich zu ELT:
- Es bestehen Datenschutzbedenken:
Sie müssen vertrauliche Informationen schützen, bevor Sie Daten an ein Ziel laden. ETL reduziert das Risiko des Verlusts vertraulicher Informationen. Darüber hinaus stellt es sicher, dass Ihr Unternehmen nicht gegen Compliance-Standards verstößt.
- Historische Sichtbarkeit ist wichtig:
Historische Daten ermöglichen eine ganzheitliche Sicht auf Geschäftsprozesse. Vom Kunden bis zum Lieferanten bietet es detaillierte Einblicke in die Stakeholder-Beziehungen. ETL ist für diesen Zweck die ultimative Wahl. Es kann bei der Erstellung benutzerdefinierter Dashboards und präziser Berichte hilfreich sein.
- Die Daten liegen in einem strukturierten Format vor:
Wenn Sie sich nicht sicher sind, wann Sie ETL verwenden sollten, ermitteln Sie die Art der Daten. ETL eignet sich besser, wenn die Daten strukturiert sind. Während Sie ETL zum Strukturieren unstrukturierter Daten verwenden können, können Sie damit keine unstrukturierten Daten an das Ziel weiterleiten.
- Sie benötigen historische Daten:
Sie benötigen einen umfassenden Prüfpfad und eine historische Nachverfolgung von Datenänderungen, da Sie mit ETL-Prozessen Transformationsaktivitäten erfassen und protokollieren können.
- Datenaggregation ist wichtig:
Das Aggregieren und Zusammenfassen von Daten aus mehreren Quellen oder mit unterschiedlicher Granularität ist eine wichtige Anforderung, da Sie mit ETL während der Transformationsphase aggregierte Datensätze erstellen können.
- Sie arbeiten mit Legacy-Systemen:
Sie haben es mit Altsystemen zu tun, die Datentransformationen erfordern, um das Zielschema zu erfüllen.
Auf der Kehrseite, Wir empfehlen die Verwendung von ELT, wenn:
- Die Verfügbarkeit von Daten hat Priorität:
Wenn Sie mit großen Datenmengen arbeiten, ist ELT die beste Wahl, da es Daten in das Ziel-Warehouse laden kann, unabhängig davon, ob sie strukturiert oder unstrukturiert sind.
- Datenanalysten sind ELT-Experten:
Ihre Organisation verfügt über ELT-Experten, da es nicht so einfach ist, ELT-Experten zu finden, da sich die Technologie noch weiterentwickelt.
- Budget ist kein Problem:
Mit dem ELT-Prozess können Sie Informationen ohne Transformationen laden. Allerdings kann der Aufbau einer ELT-Pipeline im Vergleich zu ETL technisch aufwändiger und teurer sein. Eine Organisation mit einem ausreichenden Budget kann diesen Ansatz wählen.
- Rohdatenspeicherung ist erforderlich:
Sie möchten rohe, unveränderte Daten für historische oder zukünftige Analysen aufbewahren, da ELT Daten vor der Transformation in das Ziel-Repository lädt, sodass Sie eine Aufzeichnung der Originaldaten beibehalten können.
- Skalierbarkeit ist Ihnen wichtig:
Sie müssen große Datenmengen effizient verarbeiten, da ELT die Skalierbarkeit cloudbasierter Datenspeicher- und Cloud-Data-Warehouse-Ressourcen für Transformationen nutzen kann.
- Echtzeit- oder nahezu Echtzeitverarbeitung ist erforderlich:
Ihre Datenverarbeitungsanforderungen erfordern Transformationen oder Aktualisierungen mit geringer Latenz, da Sie mit ELT Daten laden können, sobald sie verfügbar sind, und anschließend Transformationen anwenden können.
- Schemaänderungen häufig:
Sie erwarten häufige Änderungen am Datenschema oder der Datenstruktur, da ELT Schemaänderungen flexibler aufnimmt, da Transformationen innerhalb des Ziel-Repositorys durchgeführt werden.
- CKomplexe Transformationen sind beteiligt:
Ihre Datentransformationen sind komplex und erfordern eine fortschrittliche Verarbeitung, wie z. B. Modelle für maschinelles Lernen oder Big-Data-Analyse-Frameworks, die ELT effektiv unterstützen kann.
Holen Sie sich das Beste aus beidem mit Astera Centerprise
![]()
ETL und ELT bereiten Daten für eine detaillierte Analyse vor. Egal für welche Methode Sie sich entscheiden, Astera Centerprise kann Ihre Bedürfnisse erfüllen.
Die funktionsreiche Benutzeroberfläche funktioniert gut mit den meisten Betriebssystemen, einschließlich Windows und Linux. Das Datenintegrationslösung ist sowohl für erfahrene Entwickler als auch für neue Datenanalysten einfach zu verwenden. Sie müssen keinen komplexen Code schreiben, um die gewünschte Aufgabe auszuführen. Stattdessen können Sie erweiterte Vorgänge mithilfe von Drag-and-Drop-Funktionen ausführen.
Die Software beschleunigt den Datenintegrationsprozess durch optimalen Ressourceneinsatz. Es kann Daten aus unterschiedlichen Quellen nahtlos extrahieren und transformieren. Darüber hinaus verfügt es über einen integrierten Job-Scheduler zur Automatisierung von Arbeitsabläufen.



