
Die automatisierte, Kein Code Datenstapel
Erfahren Sie, wie Astera Data Stack kann die Datenverwaltung Ihres Unternehmens vereinfachen und rationalisieren.

Hier ist, warum Sie einen PDF-Extraktor brauchen
Eine PDF-Extraktionssoftware kann Ihnen dabei helfen, unstrukturierte Daten in PDF-Dateien in saubere, strukturierte Daten zu konvertieren, die in einem Data Warehouse für Berichte und Business Intelligence gespeichert werden können. Das Portable Document Format-Dateien (PDFs) sind einfach zu teilen und anzuzeigen und behalten ihre Integrität auf allen Plattformen (Windows, macOS, Linux usw.) bei. Daher machen sie einen Großteil von Verkaufsrechnungen, Rechtsdokumenten und anderen offiziellen Geschäftsdokumenten im gesamten Unternehmensbereich aus .
Trotz der Tatsache, dass PDF-Dateiformate großartige geschäftliche Einblicke enthalten, sind sie nicht ideal für Berichte und Analysen eingerichtet, dh sie sind unstrukturierte Dateien, sodass Datenextraktionstools benötigt werden, um diese Dokumente in Insight-Generatoren umzuwandeln.
Datenextraktion aus PDFs
Das Extrahieren von Daten aus PDF-Dateien ist ein integraler Bestandteil des Datenmanagement-Workflows. Es ermöglicht Unternehmen, rohen, unstrukturierten Text in Dokumenten in strukturierte Daten umzuwandeln, um ein zentralisiertes Datenrepository für Berichte und Analysen zu unterhalten. Allerdings ist das kein Kinderspiel, denn die Daten in PDFs sind nicht strukturiert, also ordentlich in Spalten und Zeilen angeordnet. PDF-Extraktoren verwenden gescannte Bilder von Seiten aus der Datei und führen eine optische Zeichenerkennung durch, um Text daraus zu extrahieren.
Datenextraktion aus PDFs: Welche Möglichkeiten haben Sie?
Wenn es um die Datenextraktion aus PDF-Dokumenten geht, besteht der erste Instinkt darin, die Daten einfach per Hand in die Systeme einzugeben. Das ist in Ordnung, wenn Sie ein paar Dokumente haben. Aber wenn täglich Hunderte und Tausende von Dateien verarbeitet werden, wird es selbst für mittelständische Unternehmen zu einer weit weniger praktikablen Option.
Vergleichen wir die manuelle Dateneingabe mit einigen der anderen verfügbaren Optionen für die Datenextraktion aus PDF-Dokumenten:
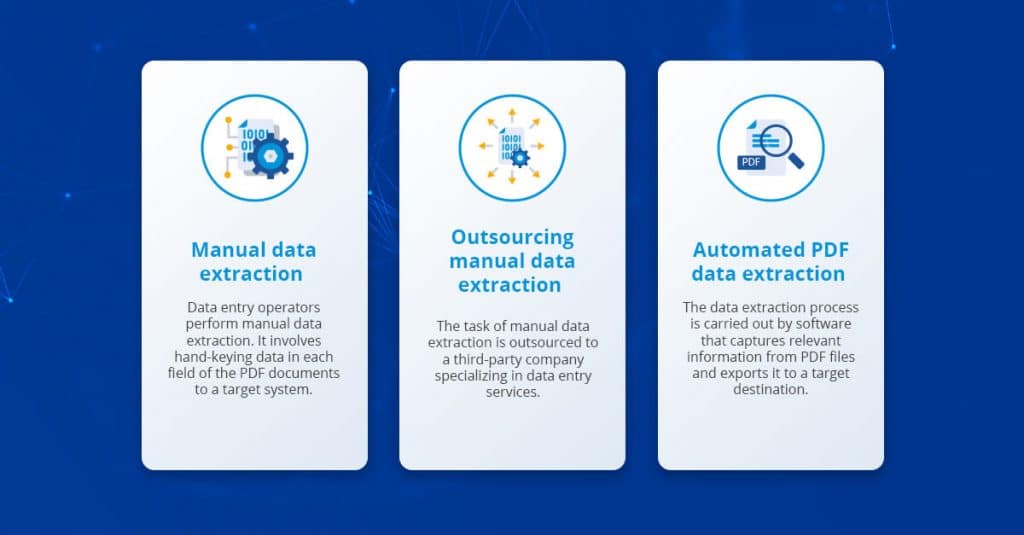
- Die manuelle Datenextraktion ist kostspielig, repetitiv und zeitaufwändig. Es ist eine unpraktische Option für die Verarbeitung großer Datenmengen. Es ist auch anfällig für menschliche Fehler, die die Datenqualität beeinträchtigen.
- Outsourcing kann die Kosten und die Geschwindigkeit der Datenextraktion bis zu einem gewissen Grad minimieren; Es wirft jedoch ernsthafte Bedenken hinsichtlich Datensicherheit und Qualitätskontrolle auf, die diese Vorteile zunichte machen.
- Die automatisierte Datenextraktion ist die schnellste und effizienteste Methode, um Daten aus PDF-Dateien zu erfassen. Moderne PDF-Extraktoren können Tausende von Dokumenten in Sekunden verarbeiten.
KI-zentrierte Datenextraktion vs. vorlagenbasierte Datenextraktion
Grundsätzlich gibt es zwei Ansätze zur Datenextraktion: KI-zentrierte Extraktion und vorlagenbasierte Datenextraktion.
KI-zentrierte Datenextraktion
Die KI-zentrische Datenextraktion ist ein neuartiger Ansatz, bei dem maschinelles Lernen und Deep-Learning-Algorithmen verwendet werden, um Beziehungen zwischen Datensätzen und gescannten Dokumenten herzustellen. Data Scientists trainieren Modelle, um Schlüsselnamen für Schlüsselfelder in Geschäftsdaten basierend auf Benutzereingaben zu erkennen, sie zu taggen und dann den relevanten Text aus dem unstrukturierten Dokument zu erfassen.
Dieser Ansatz bietet Unternehmen Vielseitigkeit und Skalierbarkeit und eignet sich hervorragend für Konversations-KI, bei der Verständlichkeit und Antworten in Echtzeit erforderlich sind. Geschulte Chatbots können beispielsweise sehr schnell erwartete Anfragen von Kunden beantworten. Darüber hinaus können Unternehmen die Reaktionszeit mit kontextbasierten Antworten minimieren.
Der KI-zentrierte Datenextraktionsprozess erfordert jedoch ein beträchtliches Dataset-Training und maschinelle Lernfähigkeiten – da Modelle trainiert werden müssen, um Mehrdeutigkeiten, Kontext und mehrere komplexe Aspekte im Zusammenhang mit der Spracherkennung zu verstehen.
Ein Datenmodellierer muss das richtige Datenvolumen bestimmen, das zum Trainieren jedes Modells erforderlich ist, um sicherzustellen, dass die Genauigkeit und Qualität der algorithmischen Ausgabe den Geschäftsanforderungen entspricht. Wenn dieser Prozess schlecht konzipiert oder implementiert ist, kann er zu Daten von schlechter Qualität aus Textdateien führen.
Template-basierte Datenextraktion
Die vorlagenbasierte Datenextraktion ist ein bewährter Ansatz zur Verarbeitung digitalisierter PDF-Dokumente in großem Maßstab. Dabei wird eine Datenextraktionsvorlage erstellt, um bestimmte Textabschnitte im Dokument zu isolieren. Das Muster wird anhand der Position und Nähe des Textes im Dokument angegeben.
Beispielsweise kann ein Benutzer ein Muster oder mehrere Muster angeben, um Daten aus einem bestimmten Bereich eines PDF-Dokuments zu extrahieren. Die Schablone würde nach dem/den Muster(n) mit einer bestimmten Kombination aus Alphabeten, Wörtern, numerischen oder alphanumerischen Zeichen suchen, die vom Benutzer angegeben werden, um Informationen zu erfassen.
Es erfordert im Vergleich zu seinem KI-zentrierten Gegenstück eine relativ geringe Rechenkapazität und bietet eine höhere Genauigkeit. Außerdem können die Vorlagen für ähnlich strukturierte PDF-Dokumente wiederverwendet werden, was die Datenextraktion beschleunigt. Diese Skalierbarkeit ist besonders nützlich, wenn Daten aus großen Mengen von PDF-Dateien extrahiert werden.
Allerdings bringt die vorlagenbasierte Datenextraktion auch einige Herausforderungen mit sich. Beispielsweise kann ein PDF-Dokument ein schwebendes Feld enthalten, dh die Feldposition einer einzelnen Zeile unterscheidet sich von den übrigen Zeilen. In einigen Fällen ist eine Spalte aufgrund von Datenverzerrungen falsch ausgerichtet.
Moderne vorlagenbasierte Datenextraktionslösungen wurden entwickelt, um diese Herausforderungen anzugehen und alle möglichen Muster für eine nahtlose Datenerfassung aus PDF- und anderen unstrukturierten Dateien zu erstellen.
Wichtige Funktionen, auf die Sie in einem PDF-Extraktor achten sollten
Die Datenextraktionsanforderungen von Organisationen unterscheiden sich von einem Anwendungsfall zum anderen. Hier sind einige der wichtigsten Must-Have-Funktionen in einem PDF-Extraktor:
- Konnektoren zu verschiedenen Datenquellen und Zielen
- Automatisierungsfunktionen
- Workflow-Orchestrierung
- Zero-Code-Umgebung
- Leicht erlernbare, intuitive Benutzeroberfläche
Astera ReportMiner — Der automatisierte No-Code-PDF-Extraktor
Astera ReportMiner ist ein PDF-Extraktor der Enterprise-Klasse, der die Verarbeitung unstrukturierter Dokumente automatisiert und vereinfacht. Seine intuitive, leicht zu erlernende Benutzeroberfläche ermöglicht Geschäftsanwendern dies nahtlos Extrahieren Sie wertvolle Informationen aus PDF-Dokumenten. Benutzer können benutzerdefinierte Datenqualitätsregeln erstellen, um extrahierte Daten aus den PDF-Dateien zu validieren.
Hauptmerkmale von Astera ReportMiner

Automatisierte Datenextraktion: Erfolgsgeschichten von Astera Software
Im Laufe der Jahre Astera ReportMiner hat zahlreichen Organisationen geholfen, Zeit zu sparen, indem Datenextraktionsaktivitäten automatisiert wurden. Hier sind einige Erfolgsgeschichten von Kunden, die unseren PDF-Extraktor verwenden:
Schnellere Verarbeitung von PDF-Schadensdatenmanagement für Aclaimant
Aclaimant, ein fortschrittlicher Anbieter von Risikominderungs- und Vorfallmanagementsystemen, verwendet Astera ReportMiner zum schnellen Extrahieren von Seiten aus PDF-Dateien. Es verwendet ReportMiner um Daten aus Antragsformularen im PDF-Format zu erfassen und in Excel- und CSV-Berichte zu schreiben. Dies führte zu einer 50-prozentigen Reduzierung des Zeit- und Ressourcenaufwands für die manuelle Transkription von Antragsformularen.
Lesen Sie die vollständige Fallstudie hier.
Automatisierte PDF-Datenextraktion für einen IT-Dienstleister einer Regierungsorganisation
Astera ReportMiner ermöglicht es einem IT-Dienstleister, der die Informationen zum Arbeitsverlauf von Regierungspersonal verarbeitet, die PDF-Datenextraktion zu vereinfachen und Fehler zu minimieren, wodurch über 1000 manuelle Arbeitsstunden pro Jahr eingespart werden.
Lesen Sie die vollständige Fallstudie hier.
Datenextraktion aus Kundenbestellungs-PDFs innerhalb von Minuten für die Ciena Corporation
Ciena Corporation, ein Anbieter von Netzwerkdiensten, Software und Ausrüstung, verwendet Astera ReportMiner Schlüsseldaten aus Kundenbestellungs-PDFs in nur 2 Minuten statt Stunden zu extrahieren. Das Unternehmen ist nun in der Lage, Kundenwünsche 15-mal schneller zu erfüllen.
Lesen Sie die vollständige Fallstudie hier.
Extrahieren Sie Daten in wenigen einfachen Schritten
Astera ReportMiner ist ein PDF Extractor, der mit einer intuitiven Zero-Code-Benutzeroberfläche mit erweiterten Funktionen zum Erfassen von Daten aus PDF-Dateien ausgestattet ist.
1) Importieren Sie eine PDF-Datei
Laden Sie eine PDF-Datei aus Ihrem lokalen oder freigegebenen Verzeichnis hoch. Der Text auf den PDF-Seiten wird im Designer des Berichtsmodells angezeigt.
*ReportMiner unterstützt verschiedene Dateitypen, einschließlich Excel, RTF, PRN, EDI usw.
2) Erstellen Sie ein Berichtsmodell
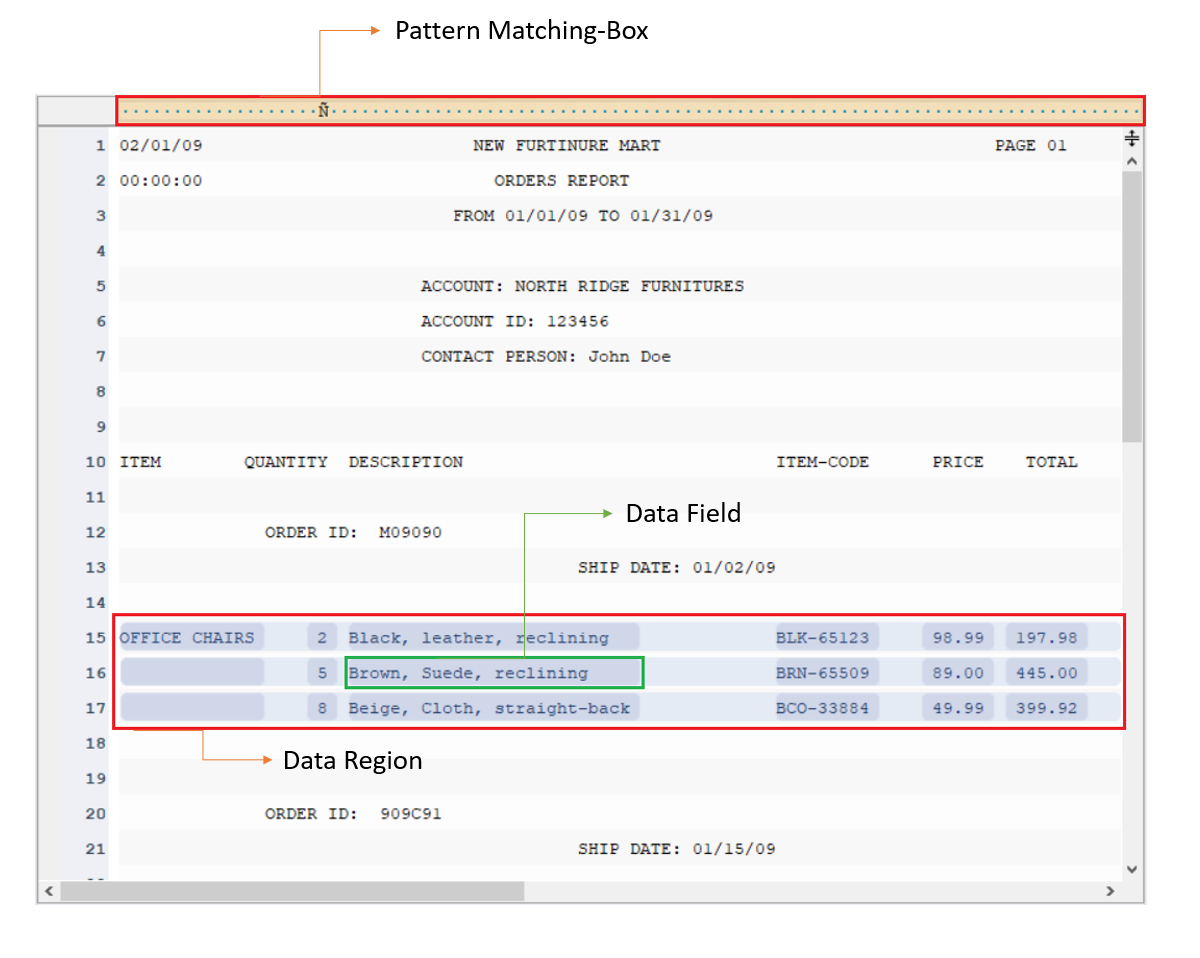
Erstellen Sie mithilfe von Musterfeldern und Bereichseigenschaftsfenstern ein Berichtsmodell, indem Sie die zu extrahierenden Datensätze und Seiten auswählen und ein Muster in einer intuitiven Umgebung ohne Code angeben.

Geben Sie das Muster für übereinstimmende Bereiche für die Datensätze in den Seiten an, die Sie aus der PDF-Datei extrahieren möchten. Wiederholen Sie den Vorgang, um weitere Datenfelder zu erstellen und alle relevanten Informationen im Dokument zu erfassen.
Die Extraktionsvorlage gibt Ihnen die vollständige Kontrolle über den Datenextraktionsprozess. Selbst wenn Sie ein mehrseitiges Dokument haben, können Sie relevante Informationen von bestimmten Seiten oder einem Teil davon erfassen.
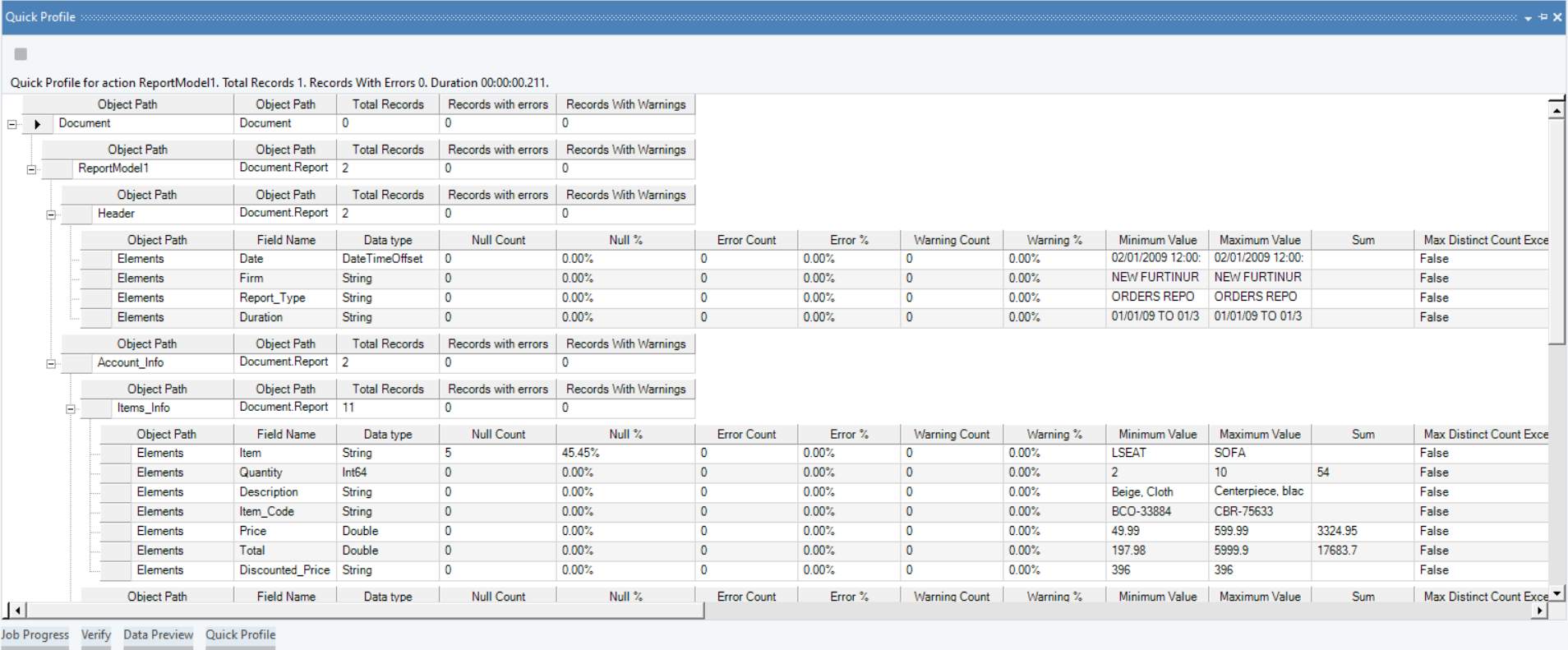
Sobald die Daten extrahiert wurden, können Sie die Datenvorschaufunktion verwenden, um die Genauigkeit und Vollständigkeit der Informationen sicherzustellen.
3) Daten zum Ziel exportieren
Du kannst dich Exportieren Sie die extrahierten Daten von PDF-Dateien zu einer Excel-Datei, CSV oder einer beliebigen Datenbank Ihrer Wahl, ob lokal oder in der Cloud. Sie können das Berichtsmodell auch in einem Datenfluss öffnen, um Daten zu bereinigen und Transformationen anzuwenden, bevor Sie sie an Ihr Zielziel exportieren.
Und du bist fertig. In wenigen einfachen Schritten strukturieren Sie nahtlos die unstrukturierten Daten, die in PDF-Geschäftsdokumenten enthalten sind.
Wenn Sie nach einem intelligenten und intuitiven Tool zum Extrahieren von PDF-Daten suchen, herunterladen eine 14-tägige kostenlose Testversion unserer automatisierten Datenextraktionslösung noch heute oder rufen Sie uns an unter +1 888-77-ASTERA um Ihren Anwendungsfall zu besprechen.



