
El automatizado, Sin código Pila de datos
Aprende cómo Astera Data Stack puede simplificar y agilizar la gestión de datos de su empresa.

Astera Centerprise Agiliza la conectividad a la base de datos de Amazon Redshift con Astera
Amazon Redshift es una solución basada en la nube bajo el paraguas de Amazon Web Services. Los bajos requisitos de mantenimiento, la escalabilidad, la velocidad y las funciones de compresión eficientes lo convierten en una opción popular de almacenamiento de datos para las empresas que manejan grandes cantidades de datos. Para hacer integración de datos con la base de datos Redshift (DB) más fácil, Astera Centerprise ha lanzado un conector preconstruido. El conector integrado se puede utilizar como objeto de origen y destino para acceder y almacenar datos. Los usuarios también pueden conectarse a la base de datos Redshift y utilizarla para la búsqueda de bases de datos y la búsqueda de sentencias SQL.
Cómo conectarse a la base de datos Redshift con Astera Centerprise
Astera Centerprise cuenta con un entorno de arrastrar y soltar, lo que permite a los usuarios comerciales conectarse a Redshift DB sin escribir largos fragmentos de código o especificar cadenas de conexión. Configure fácilmente la conectividad de Redshift para procesar datos o realizar búsquedas de bases de datos seleccionando Amazon Redshift en la lista desplegable de bases de datos compatibles.
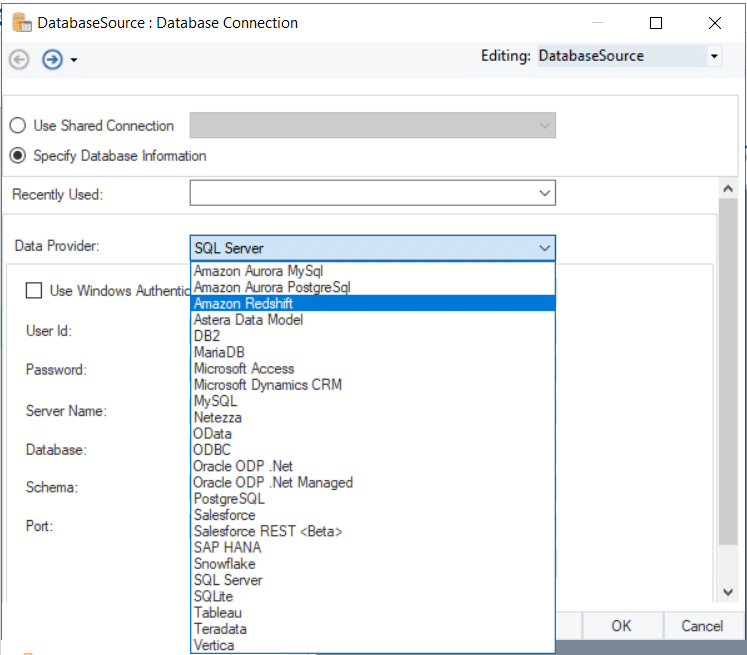
Figura 1: Desplácese por la lista de proveedores de datos admitidos por Astera Centerprise y conectarse a Redshift
Base de datos Redshift como fuente
Arrastre el fuente de tabla de base de datos objeto de la caja de herramientas y suéltelo en la ventana del diseñador para conectarse a la base de datos Redshift y utilizarlo como objeto de origen. A continuación, puede configurarlo seleccionando Redshift como proveedor de datos en la lista desplegable.
En el siguiente paso, debemos seleccionar la tabla de la que se obtendrán los datos. En este caso, estamos seleccionando una tabla con los detalles del empleado denominada pedidos.públicos. Podemos hacer clic en Partition Table for the Reading para dividir la tabla en segmentos más pequeños que se leerán individualmente. Esta opción se puede seleccionar para reducir la carga en la base de datos y mejorar el rendimiento. Aquí, también podemos seleccionar el campo clave para dividir la tabla en particiones.
Otra opción en la tabla de propiedades de la base de datos es para especificar la Estrategia de lectura. Aquí, podemos decidir si queremos leer los datos completos (carga completa) o solo los registros actualizados (carga incremental basada en campos de auditoría).
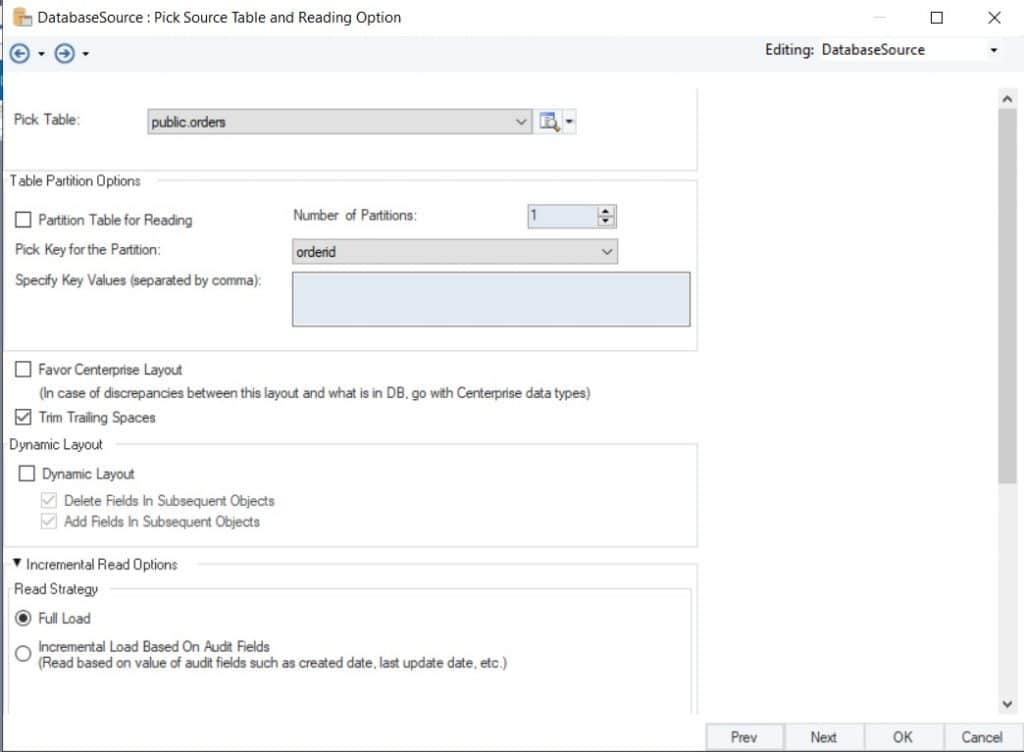
Figura 2: Selección de la tabla y estrategia de lectura para nuestra fuente de base de datos
La siguiente pantalla muestra el Generador de diseño para la tabla de origen de la base de datos. Aquí, podemos ver los tipos de datos y las longitudes de cada campo, junto con algunos otros detalles.
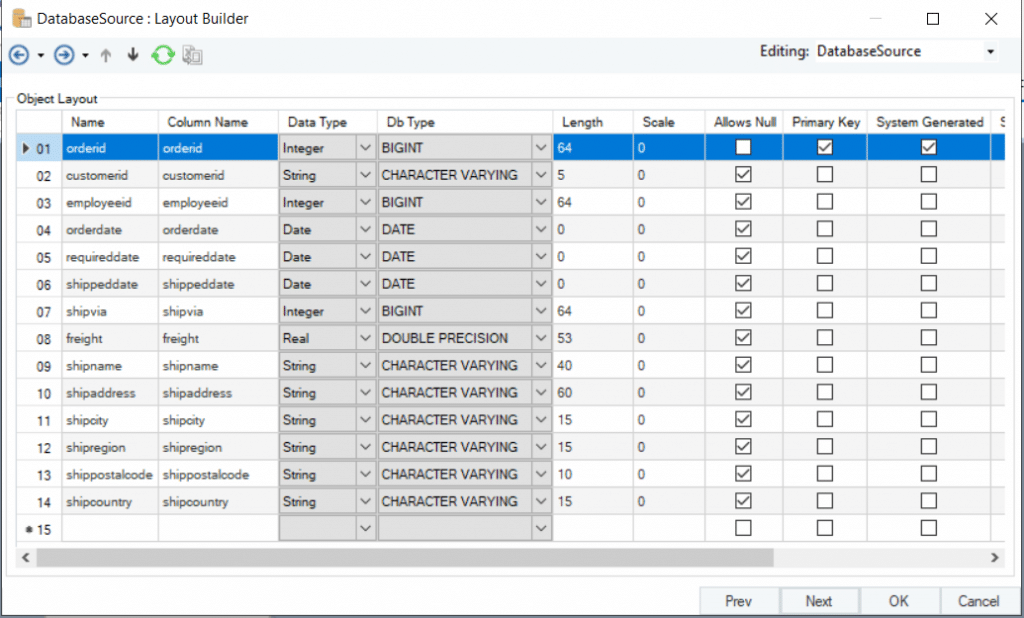
Figura 3: El generador de diseño de la tabla de base de datos de Redshift con detalles sobre el tipo de datos y la longitud de cada campo.
Los datos de esta tabla de Redshift se pueden procesar de múltiples maneras usando varias transformaciones incorporadas disponibles en Centerprise y cargado en un archivo, base de datos o cualquier otro destino disponible.
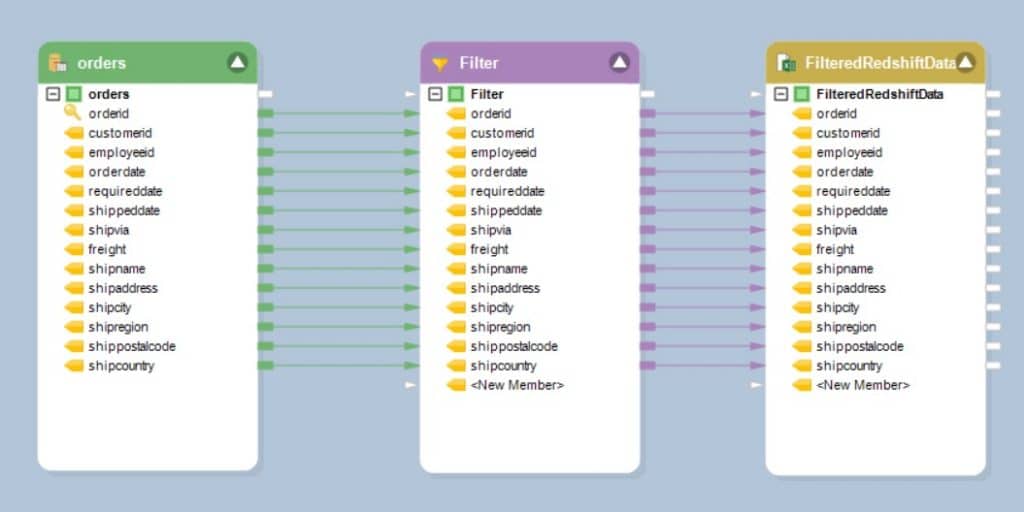
Figura 4: un flujo de datos que muestra la aplicación de un filtro a los datos obtenidos de una tabla Redshift y asignados a un objeto de destino de Excel
La captura de pantalla anterior muestra un flujo de datos que filtra los datos de la tabla Pedidos mediante una transformación de filtro y se asigna a un archivo de destino de Excel llamado FilteredRedshiftData.
Base de datos Redshift como destino
Los usuarios también pueden conectarse a la base de datos de Amazon Redshift y configurarla como un objeto de destino. Para esto, el destino de la tabla de base de datos el objeto debe arrastrarse desde la caja de herramientas y soltarse en el diseñador. A continuación, debemos apuntar el objeto de destino a la base de datos Redshift de la siguiente manera:
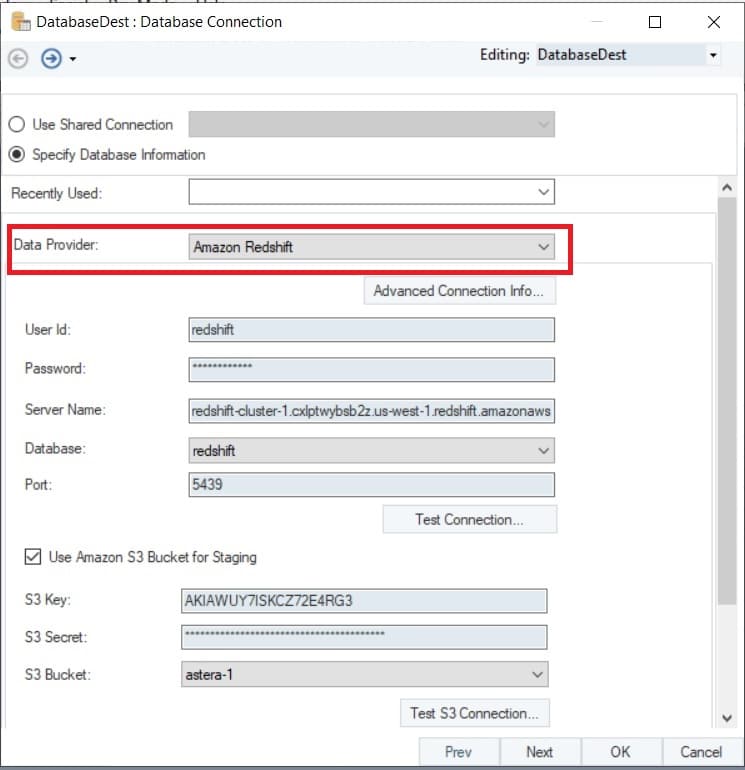
Figura 5: Configuración de un objeto de destino de tabla de base de datos con Redshift como proveedor de datos.
La imagen también muestra una opción en la que los usuarios pueden agregar sus credenciales de Amazon Simple Storage Service (S3) para cargar datos de forma masiva a Redshift DB.
Una vez que Redshift ha sido seleccionado como proveedor de datos, el usuario debe decidir si desea elegir una tabla existente, crear una nueva o sobrescribir los datos presentes en una existente. En este caso, hemos creado una nueva tabla en la base de datos y la hemos denominado WebAggregate.
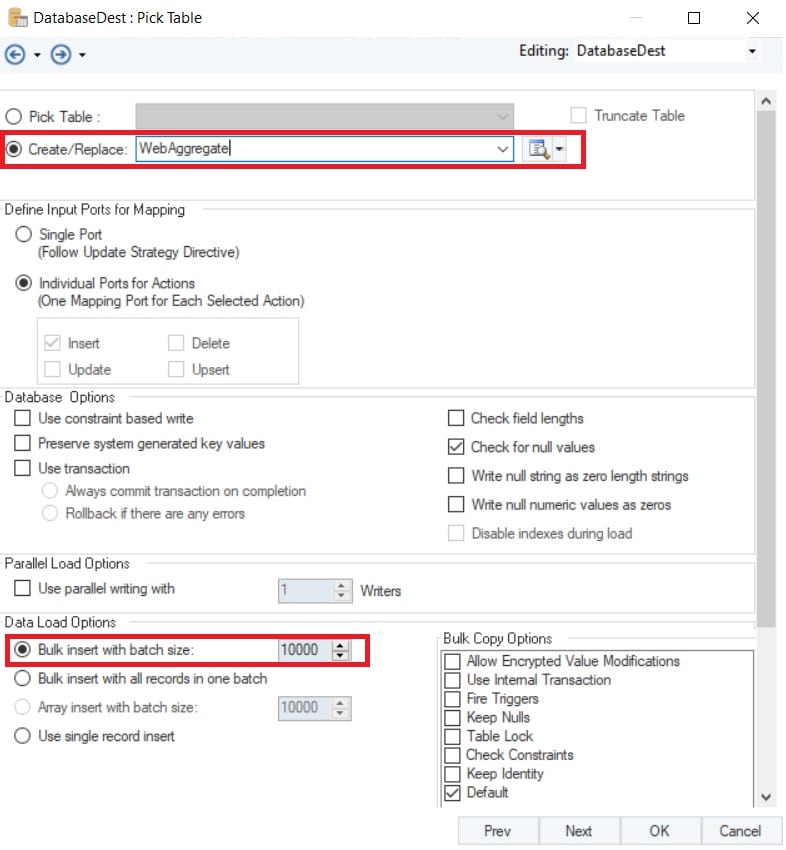
Figura 6: Se crea una nueva tabla de base de datos llamada WebAggregate para cargar datos de forma masiva.
En este ejemplo, los datos de un Objeto de origen de base de datos denominado WebConnectionRegistration se agrega y pasa a la tabla de la base de datos WebAggregate. El flujo de datos completo es el siguiente:
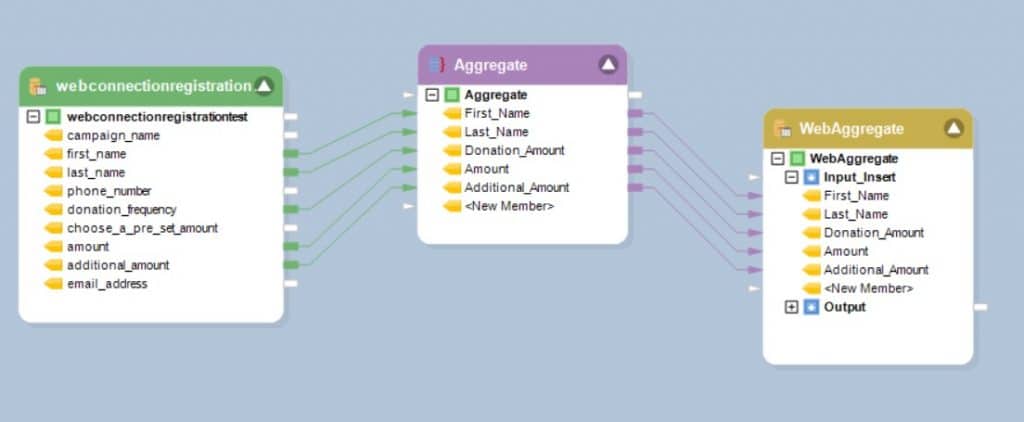
Figura 7: Los datos de una tabla de base de datos se agregan y se asignan a una tabla de destino de Redshift.
Aproveche al máximo la conectividad bidireccional con Redshift con Astera Centerprise
Los datos en la base de datos Redshift se pueden comprimir de manera mucho más eficiente que en las bases de datos basadas en filas, lo que reduce el tiempo de procesamiento y el tiempo para obtener información. Debido a los beneficios de Redshift sobre las bases de datos locales, las empresas que necesitan almacenar y procesar grandes cantidades de datos están buscando formas de crear un ecosistema empresarial bien conectado mediante la conexión a Redshift. A diferencia de los conectores que requieren mucha configuración manual, Astera CenterpriseEl conector Redshift hace que acceder y almacenar datos en la base de datos sea muy simple y conveniente.
Aquí hay algunos beneficios de usar Astera CenterpriseEl conector nativo de Redshift:
Conectividad ininterrumpida
Los usuarios no tienen que pasar por un proceso de configuración largo y complicado para conectarse a Redshift. Establecer una conexión es tan simple como seleccionar el proveedor de datos correcto de una lista desplegable y apuntar el objeto de la base de datos a la tabla correcta.
Facilidad de acceso
Conexión a Redshift usando Astera CenterpriseEl conector incorporado permite a los usuarios recuperar, transformar y cargar datos en el sistema de destino requerido con una mínima intervención de TI.
Automatización del flujo de trabajo
Con la ayuda de Astera Centerprise, los usuarios pueden automatizar sus flujos de trabajo de integración de Redshift para reducir el tiempo requerido para el análisis y aumentar la eficiencia del proceso.
El eficiente almacenamiento de datos de Amazon Redshift, el procesamiento paralelo y las capacidades de consulta simple lo convierten en una opción popular para las empresas interesadas en el análisis de datos. Con Astera CenterpriseCon el conector nativo de Redshift, las empresas pueden optimizar la conectividad de la base de datos Redshift y dedicar más tiempo a tomar decisiones basadas en datos.



