
El automatizado, Sin código Pila de datos
Aprende cómo Astera Data Stack puede simplificar y agilizar la gestión de datos de su empresa.

Enfoque tradicional frente al almacenamiento de datos basado en metadatos

Desde sistemas de información de gestión monolíticos hasta almacenes de datos y lagos de datos modelados dimensionalmente, hemos visto cambios masivos en la forma en que las organizaciones recopilan, procesan, almacenan y analizan sus datos a lo largo de los años. Cada avance en tecnología y técnicas ha sido guiado por un esfuerzo consciente para introducir mayor agilidad, accesibilidad y escalabilidad a sus informes y análisis.
Con razón, en un entorno operativo donde las preferencias de los clientes y las condiciones reinantes del mercado pueden cambiar instantáneamente, las empresas a menudo necesitan visualizar y consultar datos en cuestión de horas para obtener esa ventaja crucial sobre los competidores. Una arquitectura de datos ágil es fundamental para alcanzar ese objetivo.
Escriba la enfoque basado en metadatos. Utilizando Astera DW Builder, puede crear modelos de datos completos que integren el diseño, la lógica y los relacionados mapeo de datos que constituyen la mayor parte del desarrollo del almacén de datos y luego replican el esquema completo en una base de datos local o en la nube de su elección. A partir de ahí, estará listo para poblar, consumir o actualizar su almacén de datos con facilidad.
Al final del día, tiene un proceso rápido y receptivo creado para brindar información procesable de acuerdo con su cronograma. Compare nuestro enfoque sobre cómo solían hacerse las cosas y podrá ver las ventajas de los metadatos y el enorme valor que nuestro producto aporta al proceso de desarrollo.
Por qué el almacenamiento de datos debe evolucionar
El enfoque tradicional

Cuando hablamos de la enfoque tradicional, nos referimos al desarrollo estilo cascada, que ha dominado este espacio desde los años 90. En este proceso, el almacén de datos se construye en una secuencia meticulosamente planificada de fases que son las siguientes:
- Reunión de requisitos: En esta etapa, los desarrolladores se reunirán con analistas comerciales y otros usuarios finales para documentar qué tipo de BI se requiere.
- diseño: Después de estudiar los requisitos, los desarrolladores diseñarán una arquitectura prototipo que abarque la estructura física / lógica y las asignaciones de datos necesarias para completar y mantener
- Crear accesibilidad: Luego, los desarrolladores deben decidir cómo acceder a los datos del almacén para informes y análisis. Los datos podrían estar disponibles a través de una plataforma de BI front-end como PowerBI o Tableau o una solución personalizada creada para satisfacer las necesidades de la organización.
- Pruebas: Implica una parte de control de calidad para identificar y resolver cualquier error que pueda obstaculizar la usabilidad / rendimiento. Además de las pruebas de aceptación del usuario para garantizar que el almacén de datos cumpla con su propósito declarado.
Su almacén de datos no es un proyecto. Es un proceso.
La limitación más significativa del enfoque en cascada es que el desarrollo está orientado hacia una solución final presentada como la respuesta a todos los requisitos de BI de la organización. Este enfoque costoso no tiene en cuenta la naturaleza cambiante de estas necesidades.
- Si bien los requisitos comerciales se recopilan en función de las necesidades actuales de los usuarios finales, también deben abarcar cualquier escenario posible que podría desarrollarse dentro de meses o incluso años. Por supuesto, tratar de predecir el estado futuro de su negocio es más fácil de decir que de hacer.
- Debido a que hay tantas transferencias a lo largo del proceso de desarrollo desde los analistas de negocios hasta los desarrolladores, arquitectos y especialistas en ETL, siempre existe la posibilidad de que los requisitos se malinterpreten. Como resultado, la solución final podría estar lejos de lo acordado inicialmente, es decir, el Susurro chino
- También existe la clara posibilidad de que los usuarios finales no hayan comprendido sus requisitos en primer lugar. Es posible que hayan subestimado los datos que deben integrarse.
- Por supuesto, como la mayoría de estos problemas solo se identifican en la fase de prueba, cualquier solución aumentará el costo y los plazos del proyecto.
Bien, pero ¿qué mejora el enfoque basado en metadatos?
Comencemos con lo que queremos decir con el enfoque basado en metadatos porque hay muchas facetas en la forma en que tratamos el desarrollo del almacén de datos en Astera Constructor de DW.
Todo comienza con el modelo de datos
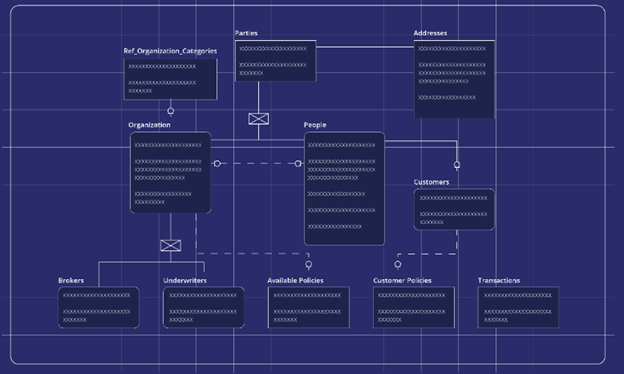
Lo primero que hay que tener en cuenta es que ponemos modelado de datos en la parte delantera y central de nuestro producto. Nuestro diseñador de modelos de datos completo y sin código permite a los usuarios diseñar cada elemento de su EDW en un único proceso de principio a fin. Inmediatamente, esto elimina las transferencias secuenciales que caracterizan el enfoque en cascada. En cambio, lo que tiene es un proceso de diseño perfecto que puede ser iniciado y administrado por una sola persona (si es necesario).
Probablemente desee tener usuarios técnicos y no técnicos involucrados en la creación de sus modelos de datos y flujos ETL en la práctica. Este tipo de colaboración está intrínsecamente soportado en nuestro producto, ya que todos los elementos necesarios para diseñar un modelo de datos se gestionan y configuran a nivel de metadatos. Ya sea que esté modelando las entidades de su sistema de origen o configurando tablas de hechos y dimensiones individuales, todo esto es posible interactuando directamente con el modelo de datos utilizando conceptos definidos por el negocio.
La gran ventaja aquí es que el usuario final puede traducir sus requisitos conceptuales en un modelo de datos físicos. En este caso, todas las relaciones entre entidades, las reglas comerciales y las convenciones de nomenclatura se acuerdan durante la fase de diseño, en lugar de aclararse al final cuando se presenta realmente un prototipo. Otro beneficio clave es que a medida que se construye el modelo, el usuario final puede proporcionar comentarios inmediatos sobre cualquier corrección que deba realizarse o ajustar sus requisitos iniciales en función del diseño de trabajo del almacén de datos.
El resultado es un modelo de datos terminado que está alineado con las necesidades de la organización.
Trabaje de forma iterativa para cumplir con los requisitos de BI

En esta etapa, hablemos de desarrollo ágil y en qué se diferencia del enfoque en cascada. En esta metodología se valoran algunos valores fundamentales: la colaboración (que hemos cubierto), priorizar el software funcional sobre la documentación precisa y la capacidad de trabajar rápidamente de acuerdo con los requisitos cambiantes en lugar de un plan establecido.
Los dos últimos puntos son fundamentales cuando se analiza cómo el enfoque basado en metadatos mejora el desarrollo del almacén de datos. Hicimos referencia a lo difícil que es crear documentación precisa que prediga perfectamente cuáles serán sus requisitos de BI dentro de un año o incluso más, así que ¿por qué no comenzar a trabajar de inmediato en una implementación más pequeña que responda a una necesidad empresarial actual?
Con Astera DW Builder, puede agregar este tipo de agilidad a su almacén de datos. Tan pronto como se identifique un requisito urgente, su equipo puede comenzar a trabajar creando un modelo de datos que refleje los sistemas operativos subyacentes que se necesitan analizar y un esquema para el almacén de datos utilizado para consultar esos sistemas. En total, el proceso se puede completar en cuestión de días o incluso horas. Al final, tiene una arquitectura funcional que puede comenzar a brindar información procesable a sus aplicaciones de front-end de inmediato.
Por supuesto, a medida que estos requisitos evolucionan, puede modificar sus modelos existentes agregando nuevas entidades o campos a su modelo de datos. O puede crear un modelo de datos completamente nuevo para un proceso comercial diferente que debe investigarse en profundidad. Con un enfoque ágil implementado, termina con un proceso de desarrollo iterativo que es ideal para un entorno empresarial que cambia rápidamente.
Diga adiós a la codificación manual

ETL es generalmente la parte más lenta del desarrollo del almacén de datos, ya que los desarrolladores deben asegurarse de que los datos cargados en el EDW estén libres de duplicaciones u otros problemas de calidad de datos y que los tiempos de carga se minimicen siempre que sea posible. Por lo general, el proceso requiere un esfuerzo manual significativo, y los desarrolladores escriben su código desde cero para adaptarse a los detalles de cada canal de datos.
ADWB viene completo con un componente de flujo de datos que le permite diseñar estas asignaciones de origen a almacén de datos a nivel de metadatos. Comenzando con la variedad de conectores listos para usar que le permitirán recuperar datos de sistemas de archivos planos y API a esquemas de sistemas de origen existentes creados con nuestro diseñador de modelos de datos con facilidad.
Esta última funcionalidad es esencial porque elimina la necesidad de extraer datos directamente de sus sistemas operativos, lo que consume valiosos recursos informáticos en servidores de bases de datos críticos. También crea una capa adicional de seguridad entre sus datos transaccionales y el usuario final, ya que puede construir sus modelos de datos para reflejar en tablas y registros listos para el análisis. Nuestro producto también viene con un generador de consultas de modelo de datos dedicado, que le permite crear una tabla de origen jerárquica que contiene múltiples entidades de modelo de datos basadas en relaciones existentes definidas en la etapa de modelado. Nuevamente, esta compleja construcción de consultas no requiere SQL real. Las entidades relevantes se seleccionan y configuran a nivel de metadatos.
El producto también lo tiene cubierto cuando se trata de preparar y enriquecer sus datos de origen. El generador de flujo de datos ofrece más de cien transformaciones integradas que lo ayudan a limpiar, filtrar, reemplazar, analizar y validar cualquier dato que se mueva a su almacén de datos. Por lo tanto, puede asegurarse de que solo los datos de alta calidad y listos para el análisis ingresen a su arquitectura de BI.
El mapeo de datos se acelera aún más mediante cargadores de hechos y dimensiones dedicados que truncan la puesta en escena que requiere mucho tiempo y las operaciones de búsqueda de dimensiones complejas (en registros históricos se mantienen) a un simple mapeo de arrastrar y soltar. Simplemente conecte la tabla de destino a la entidad relevante en su modelo dimensional y estará listo.
Una vez que haya terminado de diseñar asignaciones de datos de un extremo a otro, puede ejecutar el flujo de datos. Nuestro motor ETL leerá los metadatos y generará automáticamente el código necesario para llevar los datos del origen al destino. Incluso ofrecemos funciones de programación y orquestación del flujo de trabajo para ayudarlo a automatizar estas operaciones de acuerdo con sus necesidades.
Probar simultáneamente antes de la implementación

Con ADWB, hemos construido pruebas continuas en la propia arquitectura de la plataforma. Antes de implementar cualquiera de sus modelos de datos, deberá verificar el diseño para asegurarse de que cada entidad esté configurada correctamente y que no haya campos en blanco o valores inconsistentes. Con las pruebas simultáneas implementadas, puede identificar rápidamente los errores en su compilación y corregirlos antes de que causen problemas al usuario final.
De manera similar, hemos implementado notificaciones de errores y registros en tiempo real durante la ejecución del flujo de datos, por lo que cualquier problema en sus procesos ETL puede detectarse dentro de los metadatos. El resultado es una arquitectura sometida a pruebas de estrés construida para manejar incluso los casos de uso de BI más complejos con facilidad.
Replica tu esquema en cualquier base de datos líder.

Debido a que los modelos de datos se crean a nivel de metadatos, no están codificados para su integración con ninguna plataforma en particular. Básicamente, lo que ha creado es un esquema independiente de la plataforma que se puede replicar con facilidad en cualquier base de datos de destino. Para facilitar aún más las cosas, brindamos soporte para líderes locales y almacenes de datos en la nube, por lo que puede optar por construir su almacén de datos en la infraestructura que mejor se adapte a sus necesidades de BI.
Buscando aprovechar la escalabilidad y el rendimiento de Desplazamiento al rojo de Amazon, establezca una conexión a la base de datos y reenvíe el ingeniero. ¿Quiere mantener sus informes internos? Seleccione un proveedor local, como SQL Server u Oracle Database, la elección es suya.
Compare este proceso con las implementaciones de alto costo que se prefieren en cascada, donde cualquier actualización o modificación requiere otra ronda de desarrollo de un extremo a otro, y está claro qué método es más adecuado para el BI moderno.
Experimente el almacenamiento de datos basado en metadatos con Astera Constructor DW
¿Quiere aprovechar nuestra nueva y emocionante solución de almacenamiento de datos? Póngase en contacto con nuestros expertos para obtener más información sobre cómo nuestra arquitectura basada en metadatos puede ayudarlo a obtener los resultados que necesita o para un demo personalizada para su caso de uso específico.



