

El automatizado, Sin código Pila de datos
Aprende cómo Astera Data Stack puede simplificar y agilizar la gestión de datos de su empresa.

¿Qué es la arquitectura del almacén de datos?
Durante las últimas décadas, la arquitectura del almacén de datos ha sido el pilar de los ecosistemas de datos corporativos. Y a pesar de los numerosos cambios ocurridos en los últimos cinco años en el ámbito del big data, la computación en la nube, el análisis predictivo y las tecnologías de la información, almacenes de datos sólo han adquirido más importancia.
Hoy en día, la importancia de almacenamiento de datos no se puede negar, y hay más posibilidades disponibles para almacenar, analizar e indexar datos que nunca.
Este artículo discutirá los diversos conceptos básicos de una arquitectura de almacenamiento de datos empresarial, diferentes modelos de almacenamiento de datos empresarial (EDW), sus características y componentes significativos, y explorará el propósito principal de un almacenamiento de datos en las industrias modernas.
Teorías de la arquitectura del almacén de datos
Para comprender la arquitectura del almacén de datos, es importante conocer a Ralph Kimball y Bill Inmon, las dos figuras destacadas en el campo del almacenamiento de datos. Estos dos propusieron diferentes enfoques para diseñar arquitecturas de almacenamiento de datos.
Enfoque Kimball
Ralph Kimball es conocido por su modelado dimensional enfoque, que se centra en entregar datos de una manera optimizada para consultas e informes del usuario final. El enfoque de Kimball se centra en la creación de almacenes de datos utilizando estructuras de esquemas en estrella, donde una tabla de hechos central contiene medidas cuantitativas y las tablas de dimensiones describen atributos relacionados. Es un enfoque de arriba hacia abajo, iterativo y ágil que enfatiza la entrega rápida de valor comercial mediante la creación de mercados de datos temáticos específicos para satisfacer las necesidades específicas de informes de los usuarios.
Enfoque Inmón
El enfoque de Bill Inmon, por otro lado, enfatiza un entorno de almacenamiento de datos más centralizado, integral y estructurado. Aboga por un modelo de datos normalizado donde los datos se organizan en tablas separadas para eliminar la redundancia y mantener integridad de los datos. Utiliza un concepto de "bus de almacén de datos" para crear componentes estandarizados y reutilizables y enfatiza integración de datos, transformación y gobernanza para garantizar la precisión y coherencia de los datos.
Componentes de la arquitectura DWH
Antes de pasar a los detalles de la arquitectura, comprendamos los conceptos básicos de lo que constituye un almacén de datos: el esqueleto detrás de esa estructura.
Las diferentes capas de un almacén de datos o los componentes de una arquitectura DWH son:
- Base de datos de almacenamiento de datos
El componente central de una arquitectura típica de almacenamiento de datos es una base de datos que almacena todos los datos de la empresa y los hace manejables para generar informes. Obviamente, esto significa que debe elegir qué tipo de base de datos usará para almacenar datos en su almacén.
Los siguientes son los cuatro tipos de bases de datos que puede utilizar:
- Bases de datos relacionales típicas son las bases de datos centradas en filas que quizás utilice a diario, por ejemplo, Microsoft SQL Server, SAP, Oracle e IBM DB2.
- Bases de datos analíticas se desarrollan con precisión para que el almacenamiento de datos mantenga y gestione los análisis, como Teradata y Greenplum.
- Aplicaciones de almacenamiento de datos No son exactamente bases de datos de almacenamiento, pero varios distribuidores ahora ofrecen aplicaciones que ofrecen software para la gestión de datos así como hardware para almacenar datos. Por ejemplo, SAP Hana, Oracle Exadata e IBM Netezza.
- Bases de datos basadas en la nube se puede alojar y recuperar en la nube para que no tenga que adquirir ningún hardware para configurar su almacén de datos, por ejemplo, Amazon Redshift, Google BigQuery y Microsoft Azure SQL.
2. Herramientas de extracción, transformación y carga (ETL)
Herramientas ETL son componentes centrales de una almacén de datos empresarial diseño. Estas herramientas ayudan a extraer datos de diferentes fuentes, transformarlos en una disposición adecuada y cargarlos en un almacén de datos.
La herramienta ETL que elija determinará lo siguiente:
- El tiempo empleado en la extracción de datos
- Aproximaciones a la extracción de datos.
- Tipo de transformaciones aplicadas y la sencillez de hacerlo
- Definición de regla de negocio para validación de datos y limpieza para mejorar el análisis del producto final
- Relleno de datos extraviados
- Esquema de la distribución de información desde el depósito fundamental a sus aplicaciones de BI

3. Metadatos
En una arquitectura de almacén de datos típica, los metadatos describen la base de datos del almacén de datos y ofrecen un marco para los datos. Ayuda a construir, preservar, manejar y hacer uso del almacén de datos.
Hay dos tipos de metadatos en el almacenamiento de datos:
- Los metadatos técnicos comprende información que los desarrolladores y gerentes pueden utilizar al ejecutar tareas de administración y desarrollo del almacén.
- Metadatos empresariales incluye información que ofrece un punto de vista fácilmente comprensible de los datos almacenados en el almacén.

Papel de los metadatos en un almacén de datos
Los metadatos juegan un papel importante para que las empresas y los equipos técnicos comprendan los datos presentes en el almacén y los conviertan en información.
Su almacén de datos no es un proyecto; es un proceso Para que su implementación sea lo más efectiva posible, debe adoptar un enfoque verdaderamente ágil, lo que requiere un arquitectura de almacenamiento de datos basada en metadatos.
Se trata de un enfoque visual del almacenamiento de datos que aprovecha los modelos de datos enriquecidos con metadatos para impulsar todos los aspectos del proceso de desarrollo, desde documentar los sistemas fuente hasta replicar esquemas en una base de datos física y facilitar mapeo de datos desde el origen hasta el destino.
El esquema del almacén de datos es configurado a nivel de metadatos, lo que significa que no tiene que preocuparse por la calidad del código y cómo resistirá grandes volúmenes de datos. De hecho, puede administrar y controlar sus datos sin entrar en el código.
También, usted puede Probar modelos de almacenamiento de datos al mismo tiempo. antes de la implementación y replicar su esquema en cualquier base de datos líder. Un enfoque basado en metadatos conduce a una cultura de desarrollo iterativo y prepara la implementación de su almacén de datos para el futuro, de modo que pueda actualizar la infraestructura existente con los nuevos requisitos sin interrumpir la integridad y usabilidad de su almacén de datos.
Junto con las capacidades de automatización, un diseño de almacén de datos basado en metadatos puede agilizar el diseño, el desarrollo y la implementación, lo que lleva a una implementación sólida de almacenamiento de datos.
4. Herramientas de acceso al almacén de datos
Un 0data warehouse utiliza una base de datos o un grupo de bases de datos como base. Las corporaciones de almacenamiento de datos generalmente no pueden trabajar con bases de datos sin el uso de herramientas a menos que tengan administradores de bases de datos disponibles. Sin embargo, ese no es el caso con todas las unidades de negocio.
Es por eso que utilizan la asistencia de varias herramientas de almacenamiento de datos sin código, como:
- Herramientas de consulta y reporte. Ayude a los usuarios a producir informes corporativos para análisis que pueden ser en forma de hojas de cálculo, cálculos o elementos visuales interactivos.
- Herramientas de desarrollo de aplicaciones ayudar a crear informes personalizados y presentarlos en interpretaciones destinadas a fines de informes.
- Herramientas de minería de datos para almacenamiento de datos sistematizar el procedimiento de identificación de matrices y enlaces en grandes cantidades de datos utilizando métodos de modelado estadístico de vanguardia.
- Herramientas OLAP ayudar a construir un almacén de datos multidimensional y permitir el análisis de datos empresariales desde numerosos puntos de vista.
5. Bus de almacenamiento de datos
Define el flujo de datos dentro de una arquitectura de bus de almacenamiento de datos e incluye una despensa de datos. Un data mart es un nivel de acceso que permite a los usuarios transferir datos. También se utiliza para particionar datos que se producen para un grupo de usuarios en particular.
6. Capa de informes del almacén de datos
La capa de informes en el almacén de datos permite a los usuarios finales acceder a la interfaz de BI o la arquitectura de la base de datos de BI. El propósito de la capa de informes en el almacén de datos es actuar como un tablero para la visualización de datos, crear informes y extraer cualquier información requerida.
Características del diseño del almacén de datos.
Las siguientes son las principales características del diseño, desarrollo y mejores prácticas de almacenamiento de datos:
Tema enfocado
Un diseño de almacén de datos utiliza un tema particular. Proporciona información sobre un tema en lugar de las operaciones de una empresa. Estos temas pueden estar relacionados con ventas, publicidad, marketing y más.
En lugar de centrarse en operaciones o transacciones comerciales, el almacenamiento de datos enfatiza la inteligencia comercial (BI), es decir, mostrar y analizar datos para la toma de decisiones. También ofrece una interpretación sencilla y concisa de un tema en particular al eliminar datos que pueden no ser útiles para los tomadores de decisiones.
unificada
Usando el modelado de almacenamiento de datos, un diseño de almacenamiento de datos unifica e integra datos de diferentes bases de datos de una manera colectivamente adecuada.
Incorpora datos de diversas fuentes, como bases de datos relacionales y no relacionales, archivos planos, mainframes y sistemas basados en la nube. Además, un almacén de datos debe mantener una clasificación, un diseño y una codificación coherentes para facilitar un análisis de datos eficiente.
Variación de tiempo
A diferencia de otros sistemas operativos, el almacén de datos almacena datos centralizados de un período de tiempo determinado. Por lo tanto, el almacén de datos identifica los datos recopilados dentro de un período de tiempo específico y proporciona información desde la perspectiva del pasado. Además, no permite la estructuración o alteración de los datos después de su ingreso al almacén.
No volatilidad
La no volatilidad es otra característica importante de un almacén de datos, lo que significa que no elimina los datos primarios cuando se carga nueva información. Además, solo permite la lectura de datos y la actualización intermitente para brindar una imagen completa y actualizada al usuario.
Tipos de arquitectura de almacenamiento de datos
La arquitectura de un almacén de datos típico define la disposición de los datos en diferentes bases de datos. Para extraer información valiosa de los datos sin procesar, una estructura de almacenamiento de datos moderna identifica la técnica más efectiva para organizar y limpiar los datos.
Usando un modelo dimensional, el almacén de datos extrae y convierte los datos sin procesar en el área de preparación en una estructura de almacenamiento de consumibles simple para brindar inteligencia comercial valiosa.
Además, a diferencia de un almacén de datos en la nube, un modelo de almacén de datos tradicional requiere servidores locales para que funcionen todos los componentes del almacén.
Al diseñar un almacén de datos corporativo, hay tres tipos diferentes de modelos a considerar:
Almacén de datos de un solo nivel
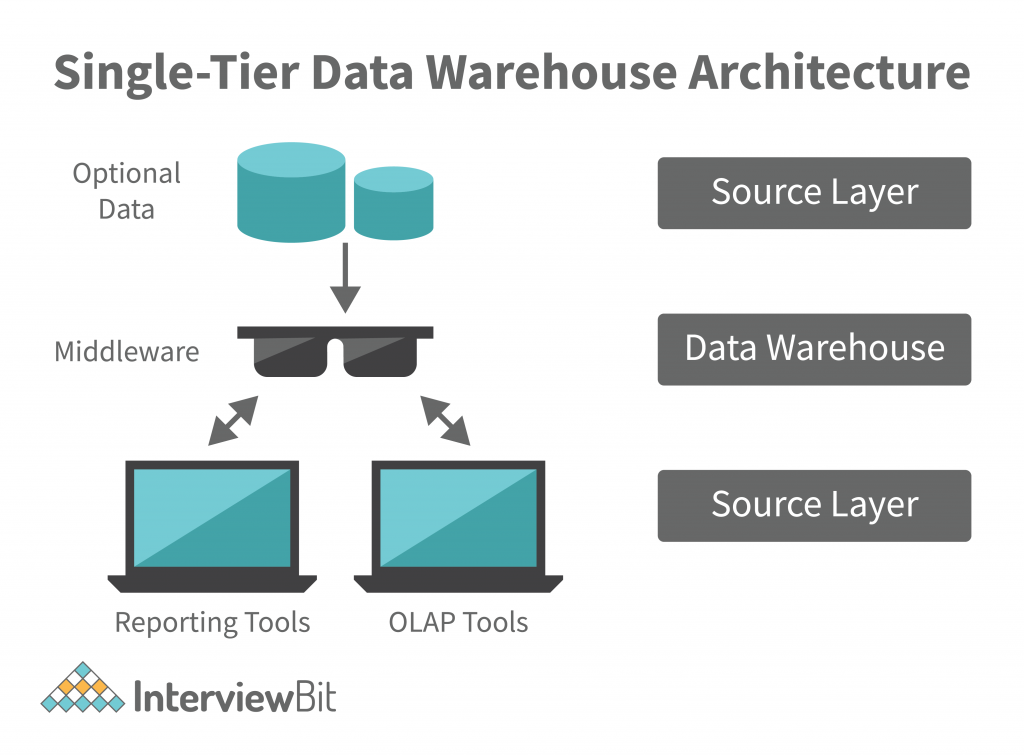
Fuente: EntrevistaBit
La estructura de una arquitectura de almacenamiento de datos de un solo nivel produce un conjunto denso de datos y reduce el volumen de los datos depositados.
Aunque es beneficioso para eliminar redundancias, este tipo de diseño de almacén no es adecuado para empresas con requisitos de datos complejos y numerosos flujos de datos. Aquí es donde entran en juego las arquitecturas de almacenamiento de datos de varios niveles, ya que se ocupan de flujos de datos más complejos.
Almacén de datos de dos niveles

Fuente: EntrevistaBit
En comparación, la estructura de datos de un modelo de almacén de datos de dos niveles divide las fuentes de datos tangibles del propio almacén. A diferencia de un nivel único, el diseño de dos niveles utiliza un sistema y un servidor de base de datos.
Las organizaciones pequeñas en las que un servidor se utiliza como data mart suelen utilizar este tipo de arquitectura de almacenamiento de datos. Aunque es más eficiente en el almacenamiento y la organización de datos, la estructura de dos niveles no es escalable. Además, solo admite un número nominal de usuarios.
Almacén de datos de tres niveles

El tipo de arquitectura de almacenamiento de datos de tres niveles es el tipo más común de diseño DWH moderno, ya que produce un flujo de datos bien organizado desde información sin procesar hasta información valiosa.
El nivel inferior en el modelo de almacén de datos generalmente comprende el servidor del banco de datos que crea una capa de abstracción en los datos de numerosas fuentes, como los bancos de datos transaccionales utilizados para usos de front-end.
El nivel medio incluye un Procesamiento analítico en línea (OLAP) servidor. Este nivel altera los datos en una disposición más adecuada para el análisis y el sondeo multifacético desde la perspectiva del usuario. Dado que incluye un servidor OLAP preconstruido en la arquitectura, también podemos llamarlo almacén de datos centrado en OLAP.
El tercer y más alto nivel es el nivel del cliente, que incluye las herramientas y la interfaz de programación de aplicaciones (API) que se utilizan para el análisis de datos, consultas e informes de alto nivel.
Sin embargo, las personas apenas incluyen el cuarto nivel en la arquitectura del almacén de datos, ya que a menudo no se considera tan integral como los otros tres tipos.
Ahora, aprendamos sobre los componentes principales de un almacén de datos (DWH) y cómo ayudan a construir y escalar un almacén de datos en detalle.

Arquitectura de almacén de datos basada en la nube
Una arquitectura de almacén de datos basada en la nube aprovecha los recursos de computación en la nube para almacenar, administrar y analizar datos para análisis e inteligencia empresarial. La base de este almacén de datos es la infraestructura en la nube proporcionada por proveedores de servicios en la nube como AWS (Amazon Web Services), Azure o Google Cloud. Estos proveedores ofrecen recursos bajo demanda, como potencia informática, almacenamiento y redes.
Estos son los componentes principales de la arquitectura de almacén de datos basada en la nube:
- Ingestión de datos: El primer componente es un mecanismo para ingerir datos de diversas fuentes, incluidos sistemas locales, bases de datos, aplicaciones de terceros y fuentes de datos externas.
- Almacenamiento de datos: Los datos se almacenan en el almacén de datos en la nube, que normalmente utiliza sistemas de almacenamiento distribuidos y escalables. La elección de la tecnología de almacenamiento puede variar según el proveedor de la nube y la arquitectura, con opciones como Amazon S3, Azure Data Lake Storage o Google Cloud Storage.
- Recursos informáticos: Los almacenes de datos basados en la nube proporcionan recursos informáticos flexibles y escalables para ejecutar consultas analíticas. Estos recursos se pueden aprovisionar bajo demanda, de modo que las empresas puedan ajustar la potencia de procesamiento en función de los requisitos de la carga de trabajo.
- Escalado automático: Los almacenes de datos basados en la nube a menudo admiten el escalamiento automático, lo que facilita que las empresas se ajusten dinámicamente para satisfacer las demandas de la carga de trabajo.
Modelos de arquitectura de almacén de datos tradicional versus en la nube
Si bien los almacenes de datos tradicionales ofrecen control total sobre el hardware y la ubicación de los datos, a menudo conllevan costos iniciales más altos, escalabilidad limitada y tiempos de implementación más lentos. Los almacenes de datos en la nube, por otro lado, ofrecen ventajas en términos de escalabilidad, rentabilidad, accesibilidad global y facilidad de mantenimiento, con la contrapartida de un control potencialmente reducido sobre la ubicación y residencia de los datos.
La elección entre las dos arquitecturas depende de las necesidades, el presupuesto y las preferencias específicas de una organización. Aquí hay una mirada más profunda a las diferencias entre los dos:
| Aspecto | Almacén de datos tradicional | Almacén de datos en la nube |
| Ubicación e Infraestructura | Local, con hardware dedicado | Basado en la nube, utilizando la infraestructura del proveedor de la nube |
| Escalabilidad | Escalabilidad limitada, se requieren actualizaciones de hardware para crecer | Altamente escalable, con recursos bajo demanda para ampliar o reducir |
| Gastos de capital | Altos costos de capital inicial para hardware e infraestructura. | Menores costos de capital iniciales, modelo de precios de pago por uso |
| Gastos operacionales | Costos operativos continuos para mantenimiento, actualizaciones y energía/refrigeración | Costos operativos reducidos ya que el proveedor de la nube se encarga del mantenimiento de la infraestructura. |
| Tiempo de implementación | Tiempos de implementación más prolongados para la adquisición y configuración de hardware | Implementación más rápida gracias a los recursos en la nube fácilmente disponibles |
| Accesibilidad Global | El acceso limitado a ubicaciones locales puede requerir configuraciones complejas para el acceso global | Fácilmente accesible desde cualquier parte del mundo, con la capacidad de distribuir datos globalmente |
| Escalabilidad | Escalabilidad limitada, se requieren actualizaciones de hardware para crecer | Altamente escalable, con recursos bajo demanda para ampliar o reducir |
| Integración de Datos | La integración con fuentes de datos externas puede ser compleja y consumir muchos recursos | Integración de datos optimizada con herramientas y servicios ETL basados en la nube |
| Seguridad de Datos | La seguridad y el cumplimiento se gestionan internamente, lo que es potencialmente complejo | Los proveedores de la nube ofrecen funciones de seguridad sólidas, con cifrado, controles de acceso y medidas de cumplimiento. |
| Copia de seguridad y recuperación ante desastres | Implica configurar y administrar soluciones de respaldo y recuperación ante desastres. | Los proveedores de la nube ofrecen opciones integradas de copia de seguridad y recuperación ante desastres |
| Aprovisionamiento de recursos | Aprovisionamiento manual y planificación de capacidad para recursos de hardware | Aprovisionamiento, escalamiento y gestión automáticos de recursos |
| Flexibilidad y Agilidad | Flexibilidad limitada, menos ágil para responder a las necesidades cambiantes del negocio. | Mayor flexibilidad y agilidad, con capacidad de escalar recursos bajo demanda. |
| Modelo de costo | Modelo de gasto de capital, donde los costos son iniciales y fijos. | Modelo de gastos operativos, con precios flexibles de pago por uso. |
| Mantenimiento y Actualizaciones | Responsabilidad interna del mantenimiento, actualizaciones y parches del hardware. | El proveedor de la nube se encarga del mantenimiento, las actualizaciones y los parches de la infraestructura |
| Integración con herramientas de BI | La integración con herramientas de BI puede requerir configuración y administración adicionales | Integración perfecta con una amplia gama de herramientas de análisis y BI |
| Gobierno de datos | Requiere procesos y herramientas de gobernanza internos | Los almacenes de datos basados en la nube a menudo proporcionan funciones y herramientas de gobernanza de datos. |
| Control de ubicación de datos | Control total sobre la ubicación y residencia de los datos | Los datos basados en la nube pueden distribuirse entre regiones, y la residencia de los datos está sujeta a las políticas del proveedor de la nube. |
| Monitoreo de recursos | Requiere la configuración de herramientas y sistemas de monitoreo. | Los proveedores de la nube ofrecen monitoreo y análisis integrados para el uso de recursos |
Personalización de la arquitectura DW con área de preparación y Data Marts
Puede personalizar la arquitectura de su almacén de datos con un área de preparación y mercados de datos. Con esta personalización, puede proporcionar los datos correctos a los usuarios correctos, lo que los hace más eficientes y efectivos para la inteligencia y el análisis empresarial.
Área de ensayo:
- Propósito: Un área de preparación es un espacio de almacenamiento intermedio dentro de la arquitectura del almacén de datos donde los datos sin procesar o mínimamente procesados se almacenan temporalmente antes de cargarse en el almacén de datos principal.
- Personalización: Puede personalizar el área de preparación según las necesidades de integración de datos de su organización. Por ejemplo, puede diseñar el área de preparación para acomodar procesos de transformación de datos, limpieza de datos y validación de datos que preparan los datos para el análisis.
Data marts:
- Finalidad: Los data marts son subconjuntos de un almacén de datos que están diseñados específicamente para satisfacer las necesidades analíticas de departamentos, funciones o grupos de usuarios comerciales. Contienen datos preagregados y personalizados para tipos de análisis específicos.
- Personalización: Para personalizar la arquitectura del almacén de datos con data marts, es necesario diseñar y completar estos data marts en función de los requisitos únicos de cada departamento o grupo de usuarios.

Mejores prácticas de arquitectura de almacenamiento de datos
- Crear modelos de almacenamiento de datos que están optimizados para la recuperación de información en enfoques dimensionales, desnormalizados o híbridos.
- Decidir entre un ETL o un ELT enfoque para la integración de datos.
- Seleccione un enfoque único para los diseños de almacenamiento de datos, como el enfoque de arriba hacia abajo o de abajo hacia arriba, y manténgalo.
- Si usa un ETL enfoque, siempre limpie y transforme los datos utilizando una herramienta ETL antes de cargarlos en el almacén de datos.

Foto tomada de medium.com/@vishwan/data-preparation-etl-in-business-performance-37de0e8ef632
- Cree un proceso de limpieza de datos automatizado en el que todos los datos se limpien uniformemente antes de cargarlos.
- Permita compartir metadatos entre diferentes componentes del almacén de datos para un proceso de extracción fluido.
- Adopte un enfoque ágil en lugar de un enfoque fijo para construir su almacén de datos.
- Asegúrese siempre de que los datos estén integrados correctamente y no solo consolidado al trasladarlo de los almacenes de datos al almacén de datos. Esto requeriría la normalización 3NF de los modelos de datos.
Automatización del diseño de almacenamiento de datos
La automatización del diseño del almacén de datos puede Impulse el desarrollo de su almacén de datos. Es esencial tener un enfoque correcto.
Primero, identifique dónde residen sus datos comerciales críticos y qué datos son relevantes para sus iniciativas de BI. Luego, cree un marco de metadatos estandarizado que proporcione un contexto crítico para estos datos en el modelado de datos etapa.
Dicho marco haría coincidir su modelo de almacén de datos con el sistema de origen, asegurando la construcción adecuada de relaciones entre entidades con claves primarias y externas correctamente definidas. También establecería combinaciones de tablas correctas y asignaría con precisión tipos de relación de entidad.
Además, debe contar con procesos que le permitan integrar nuevas fuentes y otras modificaciones en su modelo de datos de origen y volver a implementarlo. Adoptar un enfoque iterativo proporcionará una perspectiva más granular de los datos entregados para propósitos de BI y vistas materializadas.
Puede adoptar un 3NF o enfoque de modelado dimensional, según sus requisitos de BI. Este último es mejor, ya que lo ayudará a crear una estructura simplificada y desnormalizada para su modelo de almacén de datos.
Mientras lo hace, aquí hay algunos consejos esenciales que debe tener en cuenta:
- Mantenga un grano consistente en modelos de datos dimensionales
- Aplique la técnica correcta de manipulación de SCD a sus atributos dimensionales
- Optimice la carga de la tabla de hechos mediante un enfoque basado en metadatos
- Poner en marcha procesos para hacer frente a los hechos de llegada anticipada
Finalmente, los miembros del equipo pueden probar calidad de los datos y la integridad de los modelos de datos antes de que se implementen en la base de datos de destino. tener un verificación automatizada del modelo de datos La herramienta puede proporcionar importantes ahorros de tiempo.
Seguir estas mejores prácticas al automatizar el modelado de esquemas lo ayudará a actualizar sin problemas su modelo y propagar los cambios en sus canales de datos.
El siguiente paso en el proceso de diseño del almacén de datos es seleccionar la arquitectura de almacenamiento de datos adecuada.
Construya su almacén de datos con Astera Constructor DW

Astera Constructor DW es una solución integral de almacenamiento de datos que automatiza el diseño y la implementación de un almacenamiento de datos en un entorno sin códigos.
Utiliza un enfoque basado en metadatos que permite a los usuarios manipular datos mediante un conjunto completo de transformaciones integradas sin secuencias de comandos complejas de ETL o SQL.
Obtenga más información sobre la mejor arquitectura de almacenamiento de datos para informes.




