
El automatizado, Sin código Pila de datos
Aprende cómo Astera Data Stack puede simplificar y agilizar la gestión de datos de su empresa.

He aquí por qué necesita un extractor de PDF
Un software de extracción de PDF puede ayudarlo a convertir datos no estructurados en archivos PDF en datos limpios y estructurados que se pueden almacenar en un almacén de datos para informes e inteligencia comercial. los Archivos de formato de documento portátil (PDF) son fáciles de compartir y ver, y mantienen su integridad en todas las plataformas (Windows, macOS, Linux, etc.). Como resultado, constituyen la mayor parte de las facturas de ventas, documentos legales y otros documentos comerciales oficiales en el ámbito empresarial. .
A pesar del hecho de que los formatos de archivo PDF contienen excelentes conocimientos comerciales, no están configurados idealmente para informes y análisis, es decir, son archivos no estructurados, por lo que se necesitan herramientas de extracción de datos para convertir estos documentos en generadores de conocimientos.
Extracción de datos de archivos PDF
La extracción de datos de archivos PDF es una parte integral del flujo de trabajo de gestión de datos. Permite a las organizaciones convertir texto sin estructurar y sin formato en documentos en datos estructurados para mantener un depósito de datos centralizado para informes y análisis. Sin embargo, no es un paseo por el parque porque los datos en los archivos PDF no están estructurados, es decir, están bien ordenados en columnas y filas. Los extractores de PDF usan imágenes escaneadas de páginas del archivo y realizan reconocimiento óptico de caracteres para extraer texto de ellas.
Extracción de datos de archivos PDF: ¿Cuáles son sus opciones?
Cuando se trata de la extracción de datos de documentos PDF, el primer instinto es simplemente ingresar manualmente los datos en los sistemas. Eso está bien si tienes un par de documentos. Pero cuando se procesan cientos y miles de archivos todos los días, se convierte en una opción mucho menos viable incluso para las medianas empresas.
Comparemos la entrada manual de datos con algunas de las otras opciones disponibles para la extracción de datos de documentos PDF:
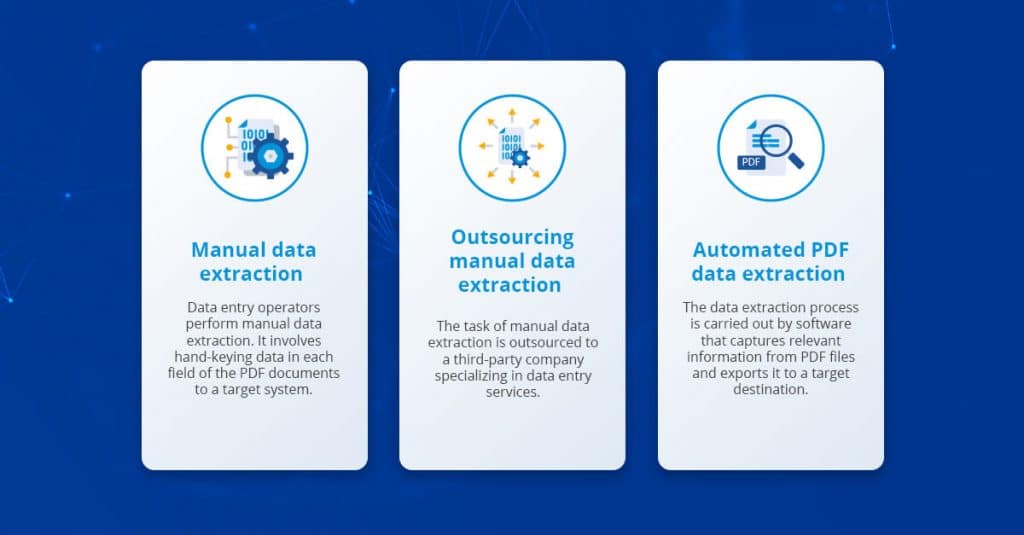
- La extracción manual de datos es costosa, repetitiva y requiere mucho tiempo. Es una opción poco práctica para procesar grandes volúmenes de datos. También es propenso a errores humanos, que afectan la calidad de los datos.
- La subcontratación puede minimizar los costos y la velocidad de extracción de datos hasta cierto punto; sin embargo, plantea serias preocupaciones sobre la seguridad de los datos y el control de calidad que contrarrestan estos beneficios.
- La extracción de datos automatizada es la forma más rápida y eficiente de capturar datos de archivos PDF. Los extractores de PDF modernos pueden procesar miles de documentos en segundos.
Extracción de datos centrada en IA frente a extracción de datos basada en plantillas
Básicamente, existen dos enfoques para la extracción de datos: extracción centrada en IA y extracción de datos basada en plantillas.
Extracción de datos centrada en IA
La extracción de datos centrada en IA es un enfoque novedoso en el que se utilizan algoritmos de aprendizaje automático y aprendizaje profundo para establecer relaciones entre conjuntos de datos y documentos escaneados. Los científicos de datos entrenan modelos para reconocer nombres clave para campos clave en datos comerciales en función de la entrada del usuario, etiquetarlos y luego capturar el texto relevante del documento no estructurado.
Este enfoque ofrece versatilidad y escalabilidad a las empresas y funciona muy bien para la IA conversacional, donde se requieren respuestas y comprensión en tiempo real. Por ejemplo, los chatbots capacitados pueden responder consultas anticipadas de los clientes muy rápidamente. Además, las empresas pueden minimizar el tiempo de respuesta con respuestas basadas en el contexto.
Sin embargo, el proceso de extracción de datos centrado en la IA requiere un considerable entrenamiento de conjuntos de datos y habilidades de aprendizaje automático, ya que los modelos deben entrenarse para comprender las ambigüedades, el contexto y varios aspectos complejos relacionados con la detección del idioma.
Un modelador de datos debe determinar el volumen correcto de datos requerido para entrenar cada modelo para garantizar que la precisión y la calidad de la salida algorítmica cumpla con los requisitos comerciales. Cuando está mal diseñado o implementado, este proceso puede generar datos de baja calidad de los archivos de texto.
Extracción de datos basada en plantillas
La extracción de datos basada en plantillas es un enfoque probado para procesar documentos PDF digitalizados a escala. Implica crear una plantilla de extracción de datos para aislar secciones de texto específicas en el documento. El patrón se especifica utilizando la posición y proximidad del texto en el documento.
Por ejemplo, un usuario puede especificar un patrón o varios patrones para extraer datos de una región específica de un documento PDF. La plantilla buscaría los patrones con una combinación específica de letras, palabras, caracteres numéricos o alfanuméricos especificados por el usuario para capturar información.
Requiere una capacidad computacional relativamente baja en comparación con su contraparte centrada en IA y ofrece una mayor precisión. Además, las plantillas se pueden reutilizar para documentos PDF estructurados de manera similar, lo que agiliza la extracción de datos. Esta escalabilidad es particularmente útil cuando se extraen datos de grandes volúmenes de archivos PDF.
Dicho esto, la extracción de datos basada en plantillas también presenta algunos desafíos. Por ejemplo, un documento PDF puede contener un campo flotante, es decir, la ubicación del campo de una sola fila es diferente del resto de las filas. En algunos casos, una columna está desalineada debido a la deformación de los datos.
Las soluciones modernas de extracción de datos basadas en plantillas están diseñadas para enfrentar estos desafíos y crear todos los patrones posibles para la captura de datos sin problemas desde PDF y otros archivos no estructurados.
Características clave que debe buscar en un extractor de PDF
Los requisitos de extracción de datos de las organizaciones difieren de un caso de uso a otro. Estas son algunas de las principales funciones imprescindibles en un extractor de PDF:
- Conectores a varias fuentes y destinos de datos
- Capacidades de automatización
- Orquestación del flujo de trabajo
- Entorno de código cero
- Interfaz de usuario intuitiva y fácil de aprender
Astera ReportMiner — El extractor de PDF automatizado y sin código
Astera ReportMiner es un extractor de PDF de nivel empresarial que automatiza y simplifica el procesamiento de documentos no estructurados. Su interfaz de usuario intuitiva y fácil de aprender permite a los usuarios comerciales extraer información valiosa de documentos PDF. Los usuarios pueden crear reglas de calidad de datos personalizadas para validar los datos extraídos de los archivos PDF.
Características clave de Astera ReportMiner

Extracción de datos automatizada: Casos de éxito por Astera Software
A través de los años, Astera ReportMiner ha ayudado a numerosas organizaciones a ahorrar tiempo al automatizar las actividades de extracción de datos. Aquí hay algunas historias de éxito de clientes que usan nuestro extractor de PDF:
Procesamiento más rápido de gestión de datos de reclamos en PDF para Aclaimant
Aclaimant, un proveedor avanzado de sistemas de gestión de incidentes y reducción de riesgos, utiliza Astera ReportMiner para extraer rápidamente páginas de archivos PDF. Usa ReportMiner para capturar datos de formularios de reclamo en formato PDF y escribirlos en informes de Excel y CSV. Dio como resultado una reducción del 50 por ciento en el tiempo y los recursos empleados en la transcripción manual de los formularios de reclamación.
Lea el caso de estudio completo esta página.
Extracción de datos PDF automatizada para un contratista de servicios de TI de una organización gubernamental
Astera ReportMiner permite que un contratista de servicios de TI que maneja la información del historial de trabajo del personal del gobierno simplifique la extracción de datos PDF y minimice los errores, ahorrando más de 1000 horas manuales por año.
Lea el caso de estudio completo esta página.
Extracción de datos de archivos PDF de pedidos de compra de clientes en cuestión de minutos para Ciena Corporation
Ciena Corporation, un proveedor de servicios de redes, software y equipos, utiliza Astera ReportMiner para extraer datos clave de los PDF de las órdenes de compra de los clientes en solo 2 minutos en lugar de horas. La empresa ahora puede cumplir con las solicitudes de los clientes 15 veces más rápido.
Lea el caso de estudio completo esta página.
Extraiga datos en unos pocos pasos simples
Astera ReportMiner es un PDF Extractor que viene con una interfaz de usuario intuitiva de código cero con funcionalidades avanzadas para capturar datos de archivos PDF.
1) Importar un archivo PDF
Cargue un PDF desde su directorio local o compartido. El texto de las páginas PDF se mostrará en el diseñador del modelo de informe.
*ReportMiner admite varios tipos de archivos, incluidos Excel, RTF, PRN, EDI, etc.
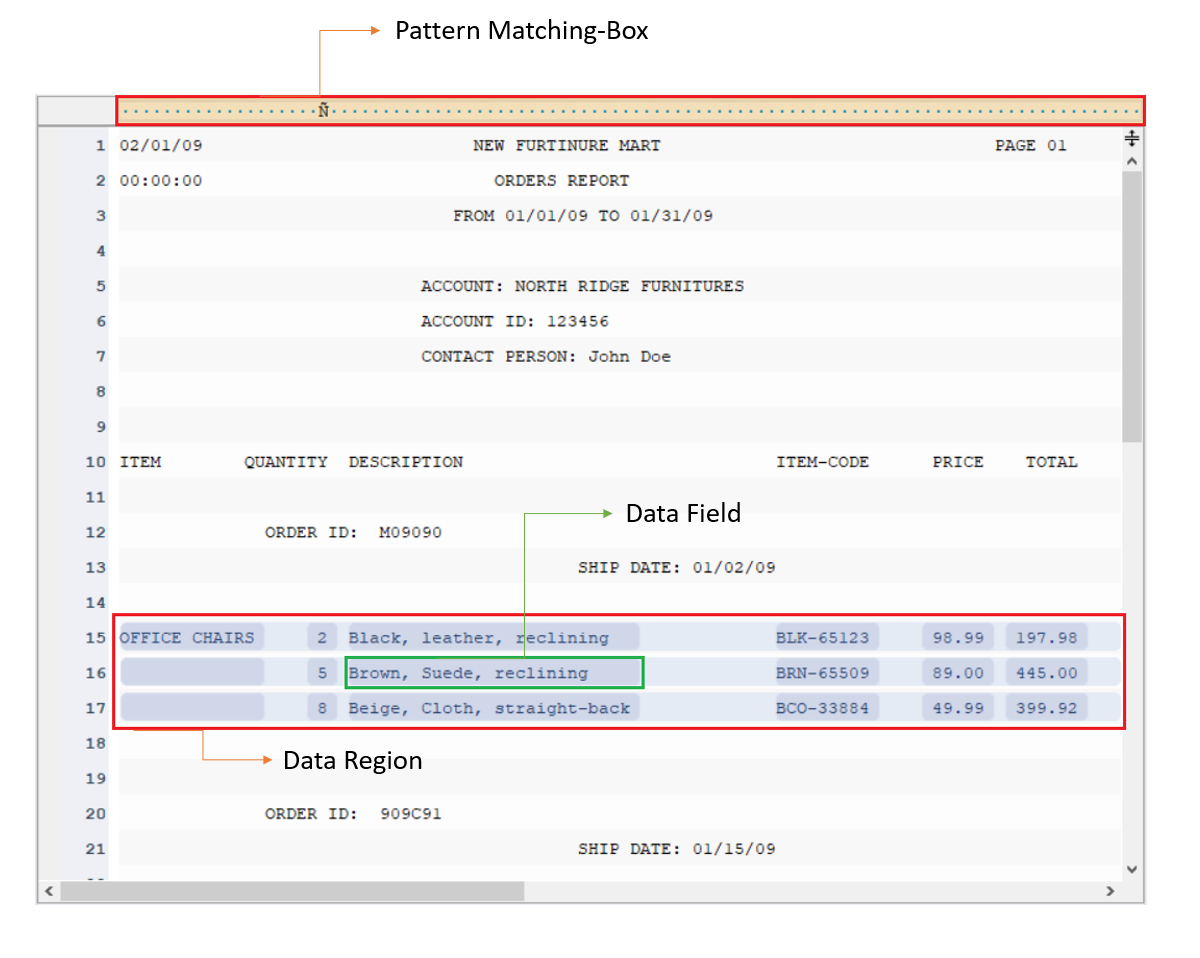
2) Crear un modelo de informe
Usando cuadros de patrón y paneles de propiedades de región, cree un modelo de informe seleccionando los conjuntos de datos y las páginas para extraer y especificar un patrón en un entorno intuitivo y sin código.

Especifique el patrón para las regiones coincidentes de los conjuntos de datos en las páginas que desea extraer del archivo PDF. Repita el proceso para crear más campos de datos para capturar toda la información relevante en el documento.
La plantilla de extracción le brinda un control completo sobre el proceso de extracción de datos. Incluso si tiene un documento de varias páginas, puede capturar información relevante de páginas específicas o de una parte de ellas.
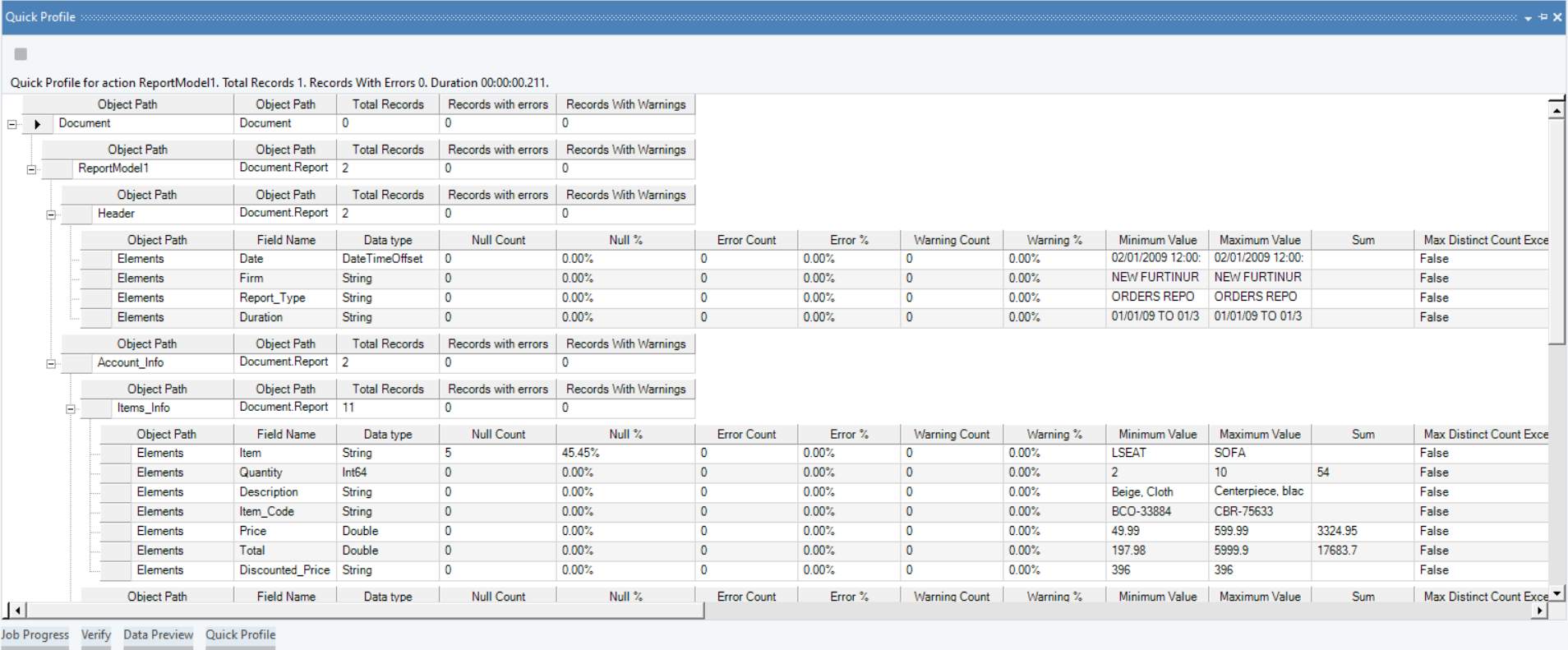
Una vez que se han extraído los datos, puede usar la función de vista previa de datos para garantizar la precisión y la integridad de la información.
3) Exportar datos a destino
solicite exportar los datos extraídos desde archivos PDF a un archivo de Excel, CSV o cualquier base de datos de su elección, ya sea local o en la nube. También puede abrir el modelo de informe en un flujo de datos para limpiar los datos y aplicar transformaciones antes de exportarlo a su destino de destino.
Y tu estas listo. En unos sencillos pasos, puede estructurar sin problemas los datos no estructurados atrapados en los documentos comerciales PDF.
Si está buscando una herramienta de extracción de datos PDF inteligente e intuitiva, descargar una prueba gratuita de 14 días de nuestra solución de extracción de datos automatizada hoy o llame al +1 888-77-ASTERA para discutir su caso de uso.



