
El automatizado, Sin código Pila de datos
Aprende cómo Astera Data Stack puede simplificar y agilizar la gestión de datos de su empresa.

Ingredientes de la arquitectura de almacenamiento de datos basada en metadatos
Seamos realistas, construir una arquitectura de almacenamiento de datos que satisfaga todas sus necesidades requiere mucha planificación y experiencia. Una arquitectura de almacenamiento de datos moderna debe integrar los datos del sistema operativo con precisión con el formato correcto y las convenciones de nomenclatura vigentes, debe ser lo suficientemente flexible como para adaptarse a los cambios en la estructura de estas fuentes subyacentes y debe proporcionar un rendimiento optimizado para respaldar los informes oportunos.
In Astera Constructor DW (ADWB), una herramienta de almacenamiento de datos, proporcionamos una solución sin código que aporta escalabilidad, velocidad y agilidad al desarrollo del almacenamiento de datos. Desde el diseñador de modelos de datos unificados, puede acceder a una gama de funcionalidades detalladas que ahorran drásticamente el tiempo y los costos involucrados en el diseño, la configuración y la implementación de su arquitectura de BI. Echemos un vistazo a cómo se combinan estos ingredientes de una arquitectura de almacén de datos empresarial:
Controle el desarrollo de almacenamiento de datos de un extremo a otro

Desarrollo de almacén de datos
Con el diseñador del modelo de datos del almacén de datos, ADWB proporciona una interfaz unificada donde los datos del sistema de origen se pueden importar, alinear con el esquema de destino, desnormalizar y preparar aún más para la migración a un modelo dimensional que está optimizado para informes y análisis. ADWB facilita este proceso de integración a través de sus funciones de ingeniería inversa e ingeniería avanzada.
Cree modelos de datos DWH enriquecidos para sus sistemas fuente
Nuestra función de ingeniería inversa toma un esquema de base de datos de origen y lo replica en forma de un modelo entidad-relación. Este modelo muestra la estructura lógica de la base de datos subyacente y le brinda la capacidad de enriquecer este esquema de varias formas para facilitar la carga en el almacén de datos.
ADWB ofrece integraciones con una variedad de bases de datos líderes que incluyen SQL Server y Oracle Database, así como proveedores en la nube como Amazon y Microsoft Azure. También puede importar modelos de datos directamente desde un software de modelado como Erwin Data Modeler, utilizando la misma técnica.
Una vez que se han importado las entidades de la base de datos, los usuarios pueden comenzar a normalizar tablas basadas en relaciones de claves compartidas o establecer relaciones dentro del modelo si no se identifican automáticamente durante el proceso de ingeniería inversa.
También pueden editar tablas individuales para asegurarse de que los campos relevantes y las convenciones de nomenclatura se reflejen en el almacén de datos.
Diseñe y configure un esquema de almacenamiento de datos que se adapte a sus requisitos de informes
Con ADWB, puede crear un modelo dimensional utilizando su técnica preferida, desde esquemas de estrellas y copos de nieve hasta bóvedas de datos y almacenes de datos operativos, nuestra plataforma los permite todos. Una vez más, nuestro diseñador de modelos de datos permite a los usuarios gestionar todas estas tareas en el nivel lógico sin tener que sumergirse en el código.
Si la empresa tiene una base de datos existente en uso para fines de almacenamiento de datos, pueden realizar ingeniería inversa y comenzar a modelar o pueden construir el esquema desde cero usando tablas de arrastrar y soltar dentro del diseñador del modelo de datos.
Con cualquier enfoque, el proceso básico sigue siendo el mismo. Una vez que haya configurado todas las entidades en su esquema y se haya asegurado de que las relaciones se establezcan correctamente entre ellas, las defina como hechos o dimensiones. También hemos incluido una entidad de dimensión de fecha dedicada para que pueda agrupar las medidas comerciales según el período de tiempo más adecuado. Desde trimestres fiscales hasta temporadas de vacaciones, lo tenemos cubierto.
A continuación, las claves sustitutas (identifica de forma única cada versión de los registros) y las claves comerciales (un valor de identificación asignado en los sistemas transaccionales según la lógica comercial interna) se asignarán a los campos correspondientes en el generador de diseño para cada entidad.
También puede personalizar cómo se formatean los datos, si los campos específicos son obligatorios o no, y decidir los valores predeterminados que se mostrarán si no aparece un valor para un atributo en particular. ¿Llegó una medida empresarial a su tabla de hechos sin una dimensión asociada? No hay problema, simplemente configure una dimensión de marcador de posición en la entidad relevante para que siempre se mantenga la integridad referencial.
Nuevamente, todos estos cambios en el nivel de metadatos afectarán cómo se configura la arquitectura del almacén de datos después de la implementación.

Seguimiento automático de cambios en los datos del sistema de origen
Uno de los aspectos principales del mantenimiento del almacén de datos es el manejo continuo de actualizaciones, eliminaciones y adiciones en las tablas del sistema de origen. Después de todo, el EDW moderno está diseñado para proporcionar una vista actual e histórica de los datos de una organización. En DWB, automatizamos estos procesos mediante tipos de dimensión que cambian lentamente. Es compatible con múltiples Técnicas de manejo de SCD, incluidos SCD Tipo 1, Tipo 2, Tipo 3 y Tipo 6.
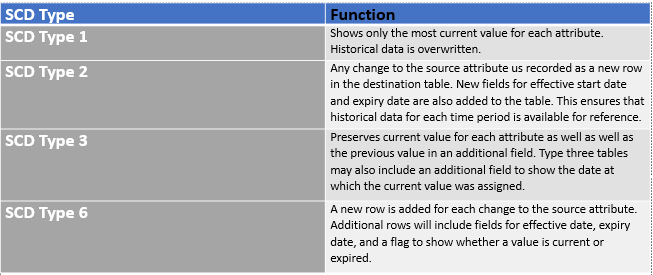
Tipos de dimensión que cambian lentamente
En el generador de diseño, los usuarios pueden elegir el tipo de dimensión de cambio lento (SCD) más eficaz para cada campo de dimensión.
Propague fácilmente los cambios del modelo de datos a su almacén de datos
Ahora que el esquema del almacén de datos está configurado a nivel de metadatos, solo debe asegurarse de que su base de datos esté lista para ser poblada. Esto se hace a través de la función de ingeniería avanzada, que aplica todos los cambios estructurales realizados en el modelo dimensional a su base de datos física.
En el futuro, puede utilizar esta opción para propagar rápidamente los cambios desde su modelo de datos a la base de datos de destino.
Verifique e implemente su modelo de datos con unos pocos clics
Con su modelo de datos configurado, ahora está listo para la implementación. Pero primero, querrá verificar la integridad de su modelo de datos utilizando nuestra práctica herramienta de verificación de datos y evitar horas de resolución de problemas manual.
Nuestra herramienta realiza comprobaciones exhaustivas de verificación de datos para reducir estas tareas repetitivas al resaltar cualquier error en su modelo de datos antes de pasar a la siguiente etapa de producción. Desde campos incompletos hasta errores de referencia, puede detectar y corregir problemas potenciales en la primera pasada utilizando esta función.
Acelere radicalmente la carga del almacén de datos
En ADWB, todo el ETL del almacén de datos se gestiona mediante objetos de carga de dimensiones y hechos dedicados. Ahora, en lugar de crear flujos de datos complejos, puede seleccionar un único objeto de origen o varias tablas de un modelo de datos de origen (se pueden seleccionar varias tablas mediante el objeto Consulta del modelo de datos en un flujo de datos) y asignarlas a un cargador. Luego, simplemente apunte su cargador hacia una tabla de hechos o dimensiones relevantes en su modelo dimensional implementado y su mapeo estará completo.
Si necesita aplicar agregados, filtros o reglas de validación adicionales a sus datos de hechos o dimensiones, solo necesita arrastrar y soltar la transformación deseada desde el conjunto de herramientas y configurarla en este flujo de datos.
Una vez que haya completado el mapeo desde la fuente hasta el almacén de datos, ADWB ejecutará los flujos. Los datos se toman de la fuente y se procesan mediante las transformaciones necesarias antes de cargarse en las tablas correspondientes del almacén. Aquí, se asignarán las claves de negocio y suplentes apropiadas, y las búsquedas se realizarán según lo definido durante la etapa de modelado. En ADWB, hemos agregado una transformación de búsqueda de dimensión dedicada que automáticamente hace una referencia cruzada de cada clave comercial con la tabla SCD relevante y la empareja con una clave sustituta adecuada.
Con una solución de almacenamiento de datos de metadatos, solo necesita crear el flujo de datos inicial. Nuestra plataforma genera automáticamente toda la codificación involucrada en el llenado del almacén de datos en modo pushdown dedicado (ELT) para garantizar que se coloque una carga mínima en su servidor durante estas operaciones de uso intensivo de recursos. En otras palabras, puede llenar su almacén de datos en minutos.
¡ADWB es compatible con plataformas!
ADWB ofrece conectores listos para usar para una variedad de destinos de bases de datos, por lo que puede configurar la arquitectura de su almacén de datos en la plataforma que elija sin preocuparse por problemas de compatibilidad. Actualmente, admitimos las siguientes bases de datos locales y en la nube líderes en la industria:
- Copo de nieve
- Amazon Redshift
- Análisis de Azure Synapse
- Almacén de datos autónomo de Oracle
- Teradata
- Almacén de datos de SAP
- Servidor SQL
- MariaDB
- vertical
- IBM DB2
Consulte y visualice los datos de su empresa desde cualquier aplicación autorizada
Todos los modelos de datos implementados también están disponibles como Servicios de OData. Nuestro motor de almacenamiento de datos de metadatos lleva estos servicios y, finalmente, a SQL para que las tablas se puedan ver o consultar desde aplicaciones y navegadores externos.
Todo lo que necesita es la dirección web de su implementación y un token de portador para autenticar la conexión, y los usuarios finales pueden acceder a los datos de su almacén a través de cualquier aplicación conectada.
También puede consumir su almacén de datos directamente a través de las principales herramientas de visualización y generación de informes, como Tableau, Power BI, Domo y más.
Organice fácilmente todas sus operaciones ETL
Una vez implementado su almacén de datos, nuestra funcionalidad de flujo de trabajo lo ayudará a administrar exactamente cómo se completan las diferentes tablas. Una vez que haya decidido cómo orquestar estas operaciones, cada flujo de datos recuperará datos del sistema de origen a través del área de preparación y los migrará al modelo de datos dimensional.
Automatice las actualizaciones y mantenga la puntualidad de sus datos empresariales
Los usuarios pueden establecer la frecuencia de las cargas de datos para cada dimensión en función de la frecuencia con la que se actualizan las tablas del sistema de origen relacionadas. Con la función Programador de trabajos, puede organizar estas operaciones para que se ejecuten de forma continua, en intervalos de tiempo específicos o de forma incremental cuando se realizan modificaciones en el sistema de origen.
Con un almacén de datos basado en metadatos, no necesita preocuparse por la calidad del código y cómo resistirá grandes volúmenes de datos. Nuestra solución genera todos los scripts ETL necesarios en el backend mediante el motor de metadatos, y está respaldada por un motor ETL de potencia industrial que está diseñado para adaptarse a sus requisitos. Agregue funciones de registro y monitoreo de trabajos en tiempo real y los errores de diseño más importantes se convertirán en cosa del pasado.
Ágil, escalable y accesible en cualquier lugar. Cree su almacén de datos en días con Astera Generador de almacenamiento de datos.
¿Interesado en probar nuestra solución? Le ofrecemos la oportunidad de participar en nuestra campaña de lanzamiento exclusiva ahora mismo. Click aquí para contáctanosy averigüe cómo puede subir a bordo.
A arquitectura basada en metadatos se centra en la gestión de metadatos y desempeña un papel fundamental para garantizar la eficacia de los sistemas de apoyo a la toma de decisiones. El almacenamiento de datos impulsado por meta también es un ETL de nueva generación y una plataforma unificada que permite a los usuarios diseñar el almacén de datos en el nivel lógico. Encapsula el diseño del esquema ETL y del almacén de datos.
En un almacén de datos, los metadatos pertenecen a una de estas tres categorías:
- Metadatos operativos: los datos del sistema de origen generalmente se filtran, transforman, combinan y mejoran aún más antes de integrarse al almacén de datos. Como resultado, puede resultar difícil determinar el origen de estos registros. Los metadatos operativos proporcionan el historial completo de un conjunto de datos, quién lo posee, las transformaciones específicas por las que pasó, así como su estado actual, es decir, si son de naturaleza actual o histórica.
- Metadatos ETL: estos metadatos se utilizan para guiar el proceso de transformación y carga de su almacén de datos. Abarca el esquema físico de las entidades migradas, incluidas las tablas y los nombres de las columnas, los tipos y valores de datos contenidos, así como el diseño prescrito para las tablas de destino. Los metadatos ETL también incluyen reglas de transformación aplicables, definiciones de hechos / dimensiones, frecuencias de carga y métodos de extracción.
- Metadatos del usuario final: este tipo de metadatos es particularmente útil para los consumidores que consultan y buscan en el almacén de datos a diario. Básicamente, funciona como un mapa del almacén de datos que proporciona detalles sobre los datos contenidos en la arquitectura, cómo se relacionan los conjuntos de datos entre sí (claves primarias / externas), cálculos necesarios para el mapeo desde el origen al destino, conjuntos de datos específicos sobre los que se debe informar y cómo.
Los beneficios clave de los metadatos en EDW son:
- Proporciona tejido conectivo para datos que de otro modo serían dispares en una arquitectura de datos compleja y de gran volumen.
- Facilita el mapeo desde los sistemas de origen hasta el almacén de datos.
- Optimiza las consultas categorizando y resumiendo conjuntos de datos.
- Se utiliza eficazmente en varias etapas del ciclo de vida del almacén de datos, incluida la generación de esquemas, la extracción, la carga en el almacén de datos, la transformación en la capa de preparación y durante el proceso de generación de informes.



