
El automatizado, Sin código Pila de datos
Aprende cómo Astera Data Stack puede simplificar y agilizar la gestión de datos de su empresa.

Lectura y asignación de archivos controlados por sinónimo Astera Centerprise
Los datos son el elemento vital de la economía moderna, y cualquier empresa que tenga como objetivo obtener un valor tangible de sus activos de información debe aprender a administrar y maximizar las diversas entradas que llegan a través de sus funciones. Sin embargo, esta tarea se ha vuelto cada vez más desafiante en el mercado globalizado de hoy en día, donde la mayoría de las compañías operan dentro de redes dispersas que consisten en socios comerciales, revendedores, proveedores, preocupaciones hermanas y más. Estas redes a menudo están sujetas a diversos factores regulatorios, geopolíticos y económicos que afectan la forma en que cada parte prepara y presenta sus datos.
En este entorno, las grandes organizaciones deben asegurarse de contar con procesos efectivos para recopilar e integrar datos de fuentes de terceros dispares de manera oportuna y rentable. De lo contrario, se pueden perder por completo los riesgos y oportunidades potenciales que podrían haberse descubierto.
Con Astera CenterpriseCon la nueva funcionalidad de coincidencia inteligente, los clientes pueden automatizar cómo se tratan las inconsistencias de datos y las irregularidades de formato en sus canalizaciones ETL y ELT.
En este documento, proporcionaremos una descripción general rápida de algunas razones que hacen que la integración de aplicaciones de terceros sea compleja, junto con un caso de uso detallado sobre cómo se puede emplear la función de mapeo y lectura de archivos basada en sinónimos Astera Centerprise para abordar el desafío.
Gestión de datos externos: ventajas y desafíos
Del Washington Post que utiliza datos sobre los clics y el compromiso de los lectores para mejorar los flujos de trabajo de las salas de redacción de The Climate Corporation que utiliza datos geopolíticos, meteorológicos y de IoT para ayudar a los agricultores a predecir y optimizar el rendimiento de los cultivos, hay varios ejemplos disponibles que demuestran cómo la optimización de la integración de datos internos y externos crea ventajas competitivas. Desafortunadamente, la gran cantidad y variedad de datos que se generan externamente pueden hacer que este sea un proceso extremadamente intensivo en recursos.
Los desafíos que se enfrentan al tratar con datos externos se pueden clasificar en función de la fase del ciclo de vida de los datos en que se producen, es decir, extracción, transformación y carga / integración. Figura 1 y XNUMX contiene una descripción no exhaustiva de estos desafíos.
Figura 1: desafíos del uso de datos externos |
|
| Fase 1: extracción o adquisición de datos externos | Incapacidad para integrar fuentes de datos externas |
| Varios usuarios tienen acceso al mismo conjunto de datos (duplicación de datos) | |
| Diferentes versiones de un solo conjunto de datos | |
| Fase 2: transformación de datos externos | Inconsistencias entre datos externos e internos. |
| Manejo de imprecisiones en datos externos | |
| Fase 3: carga de datos en un repositorio de datos centralizado | Diseño de un almacén de datos para manejar flujos de datos estructurados y no estructurados |
|
Servir conjuntos de datos personalizados a usuarios comerciales a través de API |
|
Nos centraremos en el desafío de manejar la variación en los datos recopilados de aplicaciones de terceros y garantizar la coherencia entre los datos internos y externos utilizando la función de mapeo y lectura de archivos basada en sinónimos. Astera Centerprise.
Lograr consistencia de datos con lectura y mapeo de archivos impulsados por sinónimo
Las inconsistencias de los sinónimos de diseño se producen entre los sistemas de origen y las estructuras de informes tanto en repositorios únicos, como bases de datos, como en arquitecturas consolidadas como almacenes de datos y sistemas de bases de datos federadas. En el último caso, en el que se reúnen y combinan varias fuentes de datos para informes y análisis, es probable que haya muchas más variaciones en el nombre y el formato de los diseños de datos entrantes.
Una de las formas de lograr la consistencia del diseño es analizar las fuentes individuales e identificar y resolver todas las inconsistencias de encabezado manualmente, y luego reconstruir los flujos de datos relacionados en función de las entradas corregidas. Además, la coherencia de los datos no puede lograrse mediante un proceso que funcione de manera aislada y debe basarse en estándares integrales que se aplican en todos los conjuntos de datos que ingresan a la organización. Estos problemas solo serán más pronunciados a medida que aumente el número de fuentes externas.
La lectura y el mapeo de archivos basados en sinónimos proporcionan un método intuitivo y escalable para resolver los conflictos de nombres y las inconsistencias que surgen durante las integraciones de datos de gran volumen a través de sinónimos basados en datos. Con esta función basada en sinónimos, los usuarios pueden crear una biblioteca personalizada que contenga valores para valores actuales y alternativos que pueden aparecer en el campo de encabezado de una tabla de entrada. Centerprise luego emparejará automáticamente los encabezados irregulares con la columna correcta en tiempo de ejecución y extraerá datos de ellos de manera normal.
Los objetos de origen de variantes también se pueden integrar fácilmente en los flujos de datos existentes a través de una nueva característica de mapeo automático que permite que los campos anómalos coincidan con los valores correspondientes en las transformaciones y entidades de destino posteriores.
La característica SmartMatch: un caso de uso multicliente
Para comprender mejor cómo funciona la función en Astera Centerprise, consideremos el ejemplo de una compañía de seguros de automóviles con el nombre de XYZ que proporciona procesamiento de reclamos de seguros para sus compañías clientes, así como para clientes individuales. La empresa recibe datos de reclamos que deben extraerse, filtrarse, limpiarse y entregarse a los departamentos interesados.
El resto del proceso consiste en analizar los datos, imprimir los formularios apropiados y enviarlos por correo al reclamante. Un cuello de botella crítico que afecta la eficiencia de una organización de este tipo es la integración de los datos de reclamos recibidos de varias empresas clientes y clientes para su posterior procesamiento.
Muchos de los clientes más grandes aún dependen de la entrada manual de datos para recopilar datos de reclamos en hojas de cálculo antes de enviarlos por correo electrónico a la compañía de seguros. Como resultado, gran parte de la información de política recibida sigue un formato no estándar, con convenciones de nomenclatura que varían significativamente según el reclamante. Actualmente, los administradores de TI de XYZ se ven obligados a resolver estas discrepancias creando nuevas tuberías de flujo de datos para cada fuente individual.
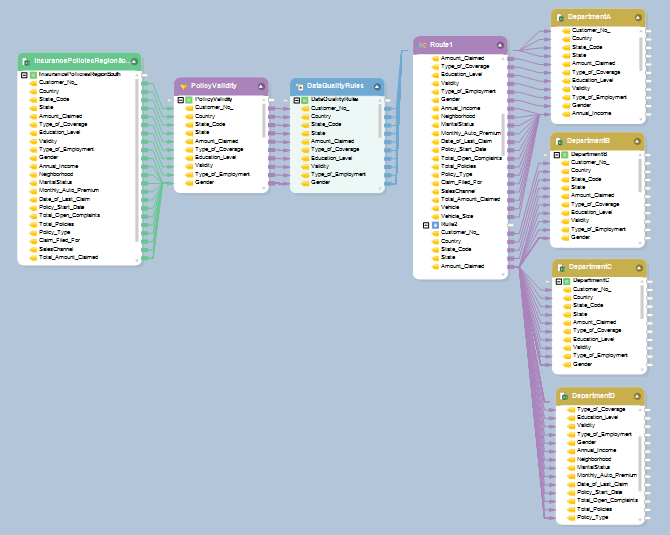
Flujo de datos de procesamiento de reclamaciones para grandes clientes: aseguradoras XYZ
Con la funcionalidad SmartMatch habilitada, se puede utilizar un único flujo de datos para procesar varios archivos de reclamantes a pesar de las diferentes convenciones de nomenclatura. Para hacerlo, simplemente crea un sinónimo para la industria de seguros en términos de diccionario de archivos que se puede implementar en todo su proyecto de procesamiento de reclamos.
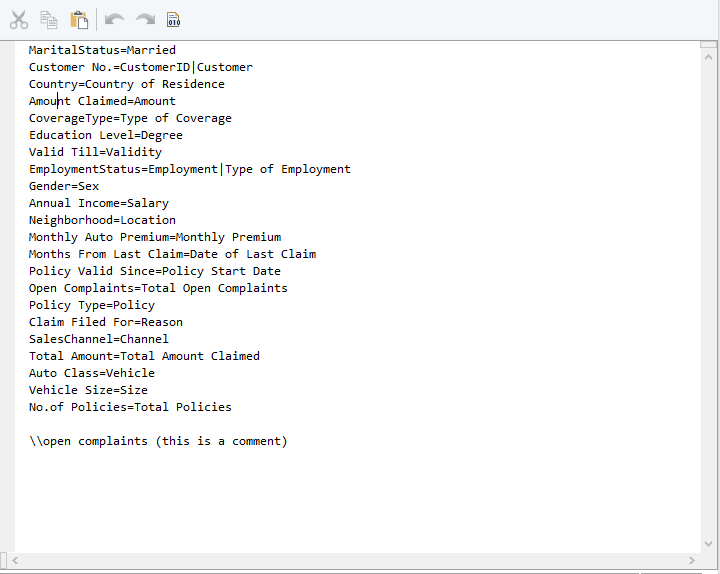
Diccionario de archivos de sinónimos para las aseguradoras XYZ
A continuación, crean un flujo de trabajo en bucle que está configurado para recoger archivos de Excel transmitidos por varios reclamantes y ejecutarlos a través del flujo de datos original de forma continua.
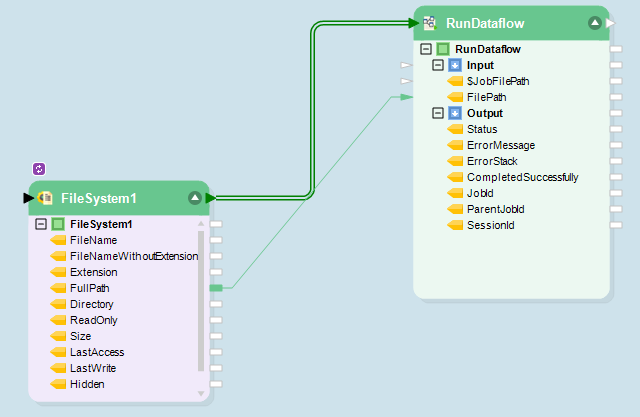
Flujo de trabajo de la aseguradora XYZ
Cuando se inicia el flujo de trabajo, el objeto de origen del flujo de datos primero buscará una coincidencia de encabezado exacta en las columnas del archivo de Excel entrante como se especifica en el diseño original. Si esto no se encuentra, entonces Centerprise buscará encabezados que coincidan exactamente con las definiciones alternativas proporcionadas en el diccionario de archivos de sinónimos anterior, es decir, "Ingreso anual = salario ”. Se crean definiciones adicionales utilizando el comando '' | '', es decir, "Cliente No. = CustomerID | Customer ”

SmartMatch también permite la coincidencia de tokens, lo que significa que se pueden configurar definiciones alternativas para valores parciales que pueden repetirse en varios encabezados en un objeto de origen de entrada. Por ejemplo "No. = Número | # " Si XYZ utilizó este token en su diccionario de sinónimos, cualquier fuente de entrada que utilizara las convenciones de nomenclatura alternativas proporcionadas para el valor No. podría integrarse en el flujo de datos existente sin ningún ajuste manual.
Si la función SmartMatch aún no puede resolver las inconsistencias de encabezado en los nuevos archivos de entrada, entonces Centerprise empleará una concordancia de cadena compacta. Esto significa que todos los signos de puntuación y espacios se eliminarán de los nombres de las columnas de entrada y luego se compararán con las definiciones en el diseño original y el diccionario. Por ejemplo, un reclamante puede definir su Política válida desde campo debajo del encabezado Política: Fecha de inicio - como puede ver, este valor no coincide con ninguna de las definiciones descritas anteriormente. Como resultado, la coincidencia de cuerda compacta eliminará los dos puntos e intentará conciliar las irregularidades.
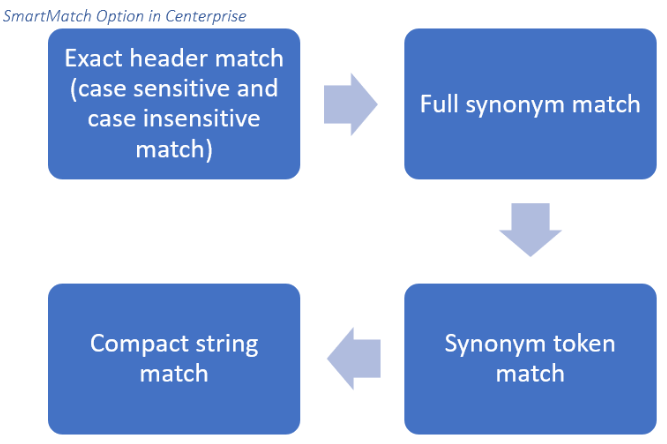
Proceso de emparejamiento inteligente
SmartMatch y Auto-Mapping
SmartMatch también es efectivo para conciliar cualquier irregularidad que ocurra entre dos objetos en un flujo de datos. Por ejemplo, si uno de los departamentos receptores de XYZ define ciertos campos de manera diferente al objeto fuente, entonces la opción de mapeo automático puede ayudar a aislar estas discrepancias. Una vez que se identifican, los usuarios pueden agregar la definición que falta a su diccionario de sinónimos y garantizar la ejecución ininterrumpida del flujo de datos.
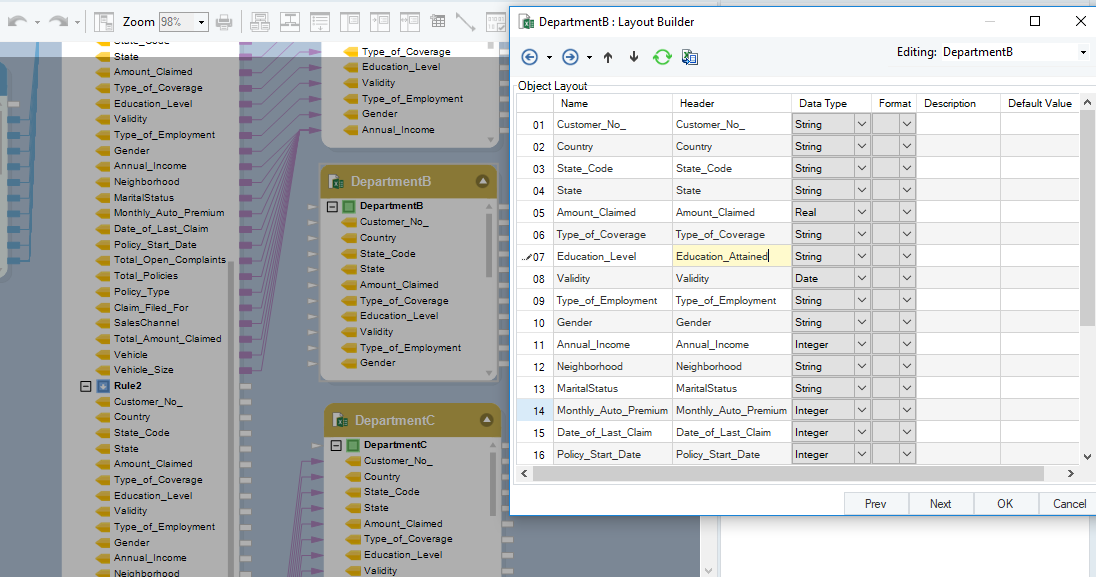
El mapeo automático muestra discrepancias
Como se puede ver, el Nivel de Educación el campo se define como Education_Attained en el diseño del Departamento B. Esta diferencia en las convenciones de nomenclatura se puede resolver en el archivo del diccionario a través de una definición de coincidencia exacta o simbólica. El mapeo automático se realiza simplemente nuevamente y el campo no mapeado se integrará en el flujo de datos.
La variedad de funciones de SmartMatch descritas en este blog puede ayudar a las organizaciones de cualquier industria a crear canalizaciones de datos más adaptables y escalables, mejor diseñadas para manejar una amplia variedad de fuentes externas e internas. Explore esta función de primera mano descargando la versión de prueba de Astera Centerprise 8.0.



