
L'automatisé, Pas de code Pile de données
Apprener comment Astera Data Stack peut simplifier et rationaliser la gestion des données de votre entreprise.

Architecture du pipeline de données : tout ce que vous devez savoir
Le summum du succès de toute organisation réside aujourd'hui dans la rapidité avec laquelle elle peut traiter les données, d'où la nécessité d'une solution hautement évolutive. pipelines de données devient de plus en plus critique pour les opérations d’une entreprise. Les pipelines de données sont la solution moderne pour automatiser, aème échelle répétitive données ingestion, transformation, et activités d'intégration. Une architecture de pipeline de données appropriée peut accélérer considérablement la disponibilité de données de haute qualité pour les systèmes et applications en aval.
Dans ce blog, nous expliquerons ce qu'est l'architecture du pipeline de données et pourquoi elle doit être planifiée avant une intégration de données projet. Ensuite, nous verrons les éléments et processus de base d’un pipeline de données. Nous explorerons également différents architecture de pipeline de donnéess et parle de l'un des meilleurs outils de gestion des données sur le marché.
Qu’est-ce que l’architecture du pipeline de données ?
Pour faire simple, un pipeline de données récupère les données de la source, les traite et les déplace vers la destination, comme n'importe quel autre pipeline dans le monde physique. Vous pouvez penser à l'architecture de pipeline de données comme ceci système organisé et interconnecté qui prend les données brutes, les affine, les stocke, les analyse, puis partage les précieux résultats, le tout de manière systématique et automatisée. L’objectif est de fournir aux applications en aval et aux utilisateurs finaux un flux constant de données propres et cohérentes.
Contrairement à un Pipeline ETL qui implique d'extraire des données d'une source, de les transformer, puis de les charger dans un système cible, un pipeline de données est une terminologie plutôt plus large et ETL (Extraire, Transformer, Charger) juste un sous-ensemble. La principale différence entre ETL et l'architecture de pipeline de données est que cette dernière utilise des outils de traitement de données pour déplacer les données d'un système à un autre, que les données soient transformées ou non.
modifier vos données
Composants de l'architecture du pipeline de données
Maintenant que vous avez une idée de l'architecture du pipeline de données, examinons le plan et abordons chaque composant d'un pipeline de données :
Les sources de données: Votre pipeline de données commence à partir des sources de données, où vos données sont générées. Vos sources de données Il peut s'agir de bases de données stockant des informations sur les clients, de fichiers journaux capturant les événements du système ou d'API externes fournissant des flux de données en temps réel. Ces sources génèrent la matière première de votre parcours de données. TLe type de source détermine la méthode d’ingestion des données.
Ingestion de données : Vient ensuite le composant d’ingestion de données qui collecte et importe les données des systèmes sources dans le pipeline de données. Cela peut être effectué par traitement par lots ou par streaming en temps réel, selon les besoins. Ingestion de données peut être effectué de deux manières principales : le traitement par lots, où les données sont collectées à intervalles planifiés, ou le streaming en temps réel, où les données circulent en continu au fur et à mesure de leur génération.
L'ingestion de données dépendra également du type de données que vous traitez. Par exemple, si vous disposez principalement de données non structurées telles que des PDF, vous aurez besoin d'un logiciel d'extraction de données spécialisé tel que Astera Rapport Mineur.
Traitement de l'information: Il s’agit de l’une des étapes les plus importantes de l’architecture car elle rend les données propres à la consommation. Les données brutes peuvent être incomplètes ou contenir des erreurs tels que des champs invalides comme une abréviation d'état ou un code postal qui n'existe plus. De même, les données peuvent également inclure des enregistrements corrompus qui doivent être effacés ou modifiés au cours d'un processus différent. Le nettoyage des données implique la normalisation des données, la suppression des doublons et le remplissage des valeurs nulles.
L’étape de traitement implique également la transformation des données. En fonction de vos données, vous devrez peut-être implémenter diverses transformations telles que la normalisation, la dénormalisation, le tri, la jointure d'arbre, etc. Le but de la transformation est de convertir les données en un format approprié pour l’analyse.
Stockage de données: Ensuite, les données traitées sont stockées dans des bases de données ou entrepôts de données. Une entreprise peut stocker des données à différentes fins telles que l'analyse historique, la redondance ou simplement les rendre accessibles aux utilisateurs dans un endroit central. Selon la finalité, les données peuvent être stockées dans différents endroits tels que des bases de données relationnelles. Par exemple, PostgreSQL, MySQL ou Oracle conviennent aux données structurées avec des schémas bien définis.
Bases de données NoSQL, telles que MongoDB, Cassandra sont conçus pour la flexibilité et l’évolutivité et sont bien adapté au traitement de données non structurées ou semi-structurées et peut évoluer horizontalement pour gérer de gros volumes.
Les données sont également stockées dans des entrepôts de données. Cependant, les entrepôts de données sont souvent associés à des plates-formes de stockage cloud telles que Google Cloud, Amazon S3 et Microsoft Blob Storage qui stockent des volumes de données élevés.
L'analyse des données: La composante d’analyse des données est l’endroit où la puissance brute des données prend vie. Cela implique l’interrogation, le traitement et l’obtention d’informations significatives à partir des données stockées. Les analystes de données et les scientifiques utilisent différents outils et technologies pour effectuer des analyses telles que des analyses descriptives, prédictives et statistiques afin de découvrir des modèles et des tendances dans les données.
Les langages et techniques les plus utilisés pour l'analyse des données incluent SQL, qui convient le mieux aux bases de données relationnelles. En dehors de cela, les utilisateurs utilisent également souvent la programmation Python ou R.
Visualisation de données: Un pipeline de données se termine par la visualisation des données, où les données sont transformées en tableaux et diagrammes circulaires, ce qui permet aux analystes de données de les comprendre plus facilement. Outils de visualisation comme PowerBI et Tableau fournir une interface intuitive pour explorer les données brutes. Les analystes et les data scientists peuvent naviguer de manière interactive dans les ensembles de données, identifier des modèles et acquérir une compréhension préliminaire des informations.
Lire la suite: 10 meilleurs outils de pipeline de données
Types de pipeline de données et leur architecture
Aucune architecture de pipeline de données n’est identique puisqu’il n’existe pas une seule façon de traiter les données. En fonction de la variété et du nombre de sources de données, les données peuvent devoir être transformées plusieurs fois avant d'atteindre leur destination.
Architecture de traitement par lots

Lot pipeline de données est une technique de traitement de données où les données sont collectées, traitées, puis les résultats sont obtenus à intervalles. Il est généralement utilisé pour de gros volumes de données pouvant être traitées sans nécessiter de résultats immédiats.
Habituellement, data est divisé en lots ou en morceaux. Cette division vise à gérer le traitement de grands ensembles de données de manière plus gérable. Chaque lot représente un sous-ensemble des données globalesa et est traité indépendamment. Le traitement peut impliquer diverses opérations, telles que le filtrage, l'agrégation, l'analyse statistique, etc. Les résultats de chaque étape de traitement par lots sont généralement stockés dans un système de stockage persistant.
Cas d'utilisation: Convient aux scénarios dans lesquels le traitement en temps réel n'est pas critique, comme les mises à jour de données quotidiennes ou horaires. Par exemple, il y a une entreprise de commerce électronique qui souhaite analyser ses données de vente pour obtenir des informations sur le comportement des clients, les performances des produits et les tendances commerciales globales permet à l'entreprise de commerce électronique d'effectuer une analyse approfondie de ses données de ventes sans avoir besoin de résultats en temps réel.
Composants:
- Source de données: D’où proviennent les données brutes.
- Moteur de traitement par lots : Traite les données à intervalles prédéfinis.
- Stockage: Contient les données traitées.
- Scheduler: Déclenche le traitement par lots à des heures spécifiées.
Pipeline de données en continu
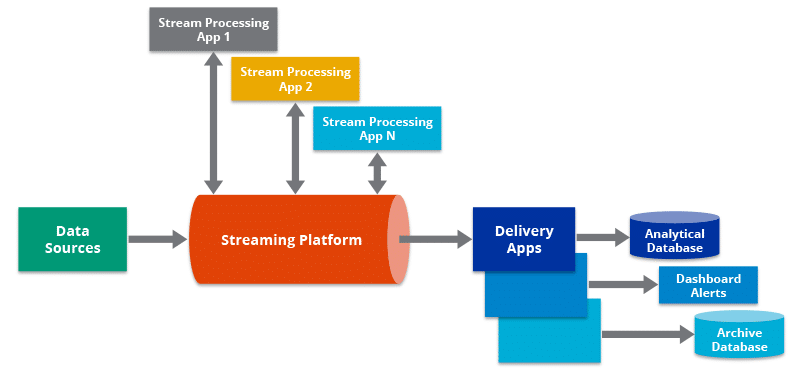
Le traitement de flux effectue des opérations sur des données en mouvement ou en temps réel. Il vous permet de détecter rapidement les conditions dans un délai plus court après l'obtention des données. En conséquence, vous pouvez saisir des données dans l'outil d'analyse dès leur création et obtenir des résultats rapides.
Le pipeline de données en streaming traite les données du système de point de vente au fur et à mesure de leur production. Le moteur de traitement de flux envoie les sorties du pipeline de données à référentiels de données, applications marketing, CRM et plusieurs autres applications, en plus de les renvoyer au système de point de vente lui-même.
Cas d'utilisation: Idéal pour les applications nécessitant un traitement de données à faible latence. Par exemple, jeDans le secteur financier, la détection des transactions frauduleuses est cruciale pour prévenir les pertes financières et assurer la sécurité des comptes des utilisateurs. Les systèmes de traitement par lots traditionnels peuvent ne pas suffire à identifier rapidement les activités frauduleuses. Un pipeline de données en streaming, en revanche, peut fournir une analyse en temps réel des transactions au fur et à mesure qu'elles se produisent. depuis les distributeurs automatiques, les cartes de crédit, etc.
Composantes du pipeline de données
- Source de données: Génère des flux continus de données.
- Moteur de traitement de flux : Traite les données en temps réel.
- Stockage: Stocke éventuellement les données traitées pour une analyse historique.
Lambda
L'architecture Lambda est une architecture de traitement de données conçue pour gérer à la fois le traitement des données par lots et par flux. Il a été introduit par Nathan Marz pour relever les défis du traitement du Big Data, où les exigences de faible latence pour l'analyse en temps réel coexistent avec la nécessité de traiter de gros volumes de données en mode batch. L'architecture Lambda y parvient en combinant le traitement par lots et le traitement par flux en un système unique, évolutif et tolérant aux pannes.
Voici les composants et couches clés de l'architecture Lambda :
Couche de lot :
- Fonction : Gère le traitement de grands volumes de données historiques de manière tolérante aux pannes et évolutive.
- Stockage de données : utilise généralement un système de fichiers distribué comme Apache Hadoop Système de fichiers distribués (HDFS) ou systèmes de stockage basés sur le cloud.
- Modèle de traitement : le traitement par lots implique l'exécution de calculs sur un ensemble de données complet, produisant des résultats qui sont généralement stockés dans une vue par lots ou dans une couche de service de couche par lots.
Couche de vitesse:
- Fonction : gère le traitement en temps réel des flux de données, fournissant des résultats à faible latence pour les données récentes.
- Stockage des données : repose généralement sur un système de stockage distribué et tolérant aux pannes qui prend en charge les écritures et les lectures rapides pour un traitement en temps réel.
- Modèle de traitement : le traitement des flux implique l'analyse des données en temps réel dès leur arrivée, fournissant ainsi des résultats actualisés.
Couche de service :
- Fonction : fusionne les résultats des couches de lots et de vitesse et fournit une vue unifiée des données.
- Stockage de données : utilise une base de données NoSQL ou une base de données distribuée capable de gérer à la fois des données par lots et en temps réel.
- Modèle de traitement : fournit des vues par lots précalculées et des vues en temps réel à l'application d'interrogation.
Couche de requête :
- Fonction : permet aux utilisateurs d'interroger et d'accéder aux données dans la couche de service.
- Stockage des données : les résultats de la requête sont récupérés à partir de la couche de service.
- Modèle de traitement : permet des requêtes ad hoc et l'exploration de vues par lots et en temps réel.
Pipeline ETL
Il y a une différence entre un Pipeline ETL et pipeline de données. Un pipeline ETL est une forme de pipeline de données qui est utilisé pour extraire des données de diverses sources, les transformer dans le format souhaité et les charger dans une base de données cible ou un entrepôt de données à des fins d'analyse, de reporting ou de business intelligence. L'objectif principal d'un pipeline ETL est de faciliter la mouvement des données provenant de diverses sources vers un référentiel central où ils peuvent être analysés et utilisés efficacement pour la prise de décision.
Pipeline ELT
An ELT Le pipeline (Extract, Load, Transform) est une alternative à l’approche ETL traditionnelle. Bien que l'objectif fondamental des deux ETL et ELT c'est bouger et préparer la journée. ta pour l'analyse, ils diffèrent par l'ordre dans lequel l'étape de transformation se produit. Dans un pipeline ETL, la transformation est effectuée avant le chargement des données dans le système cible, tandis que dans un pipeline ELT, la transformation est effectuée après le chargement des données dans le système cible..
Les pipelines ELT exploitent souvent la puissance de traitement des entrepôts de données modernes, conçus pour gérer des transformations de données à grande échelle..
On-Premises
Un pipeline de données sur site fait référence à un ensemble de processus et d'outils que les organisations utilisent pour collecter, traiter, transformer et analyser des données au sein de leur propre infrastructure physique ou centres de données, au lieu de s'appuyer sur des solutions basées sur le cloud. Cette approche est souvent choisie pour des raisons telles que la sécurité des données, les exigences de conformité ou la nécessité d'un contrôle plus direct sur l'infrastructure.
Les architectures sur site s’appuient sur des serveurs et du matériel physiquement situés dans le centre de données ou les installations d’une organisation. OLes organisations ont un contrôle total sur le matériel, les logiciels et les configurations réseau. Ils sont responsables de l’achat, de la maintenance et de la mise à niveau de tous les composants. Cependant, sLa mise en place de l'infrastructure implique souvent d'importants investissements en capital, et son expansion peut prendre du temps.
Cloud natif
Une architecture de pipeline de données cloud native est conçue pour tirer parti des avantages du cloud computing, offrant évolutivité, flexibilité et rentabilité. Cela implique généralement une combinaison de services gérés, de microservices et de conteneurisation..
Une architecture de pipeline de données cloud native est conçue pour être dynamique, évolutive et réactive aux besoins changeants en matière de traitement des données. Il optimise l'utilisation des ressources, améliore la flexibilité et aboutit souvent à des flux de travail de traitement de données plus rentables et plus efficaces par rapport aux solutions traditionnelles sur site.
C'est toitilisers le fonctions et services sans serveur pour réduire les frais opérationnels et faire évoluer les ressources en fonction de la demande.
Comment augmenter la vitesse du pipeline de données
Quelle que soit l’architecture de données que vous choisissez, en fin de compte, tout dépend de la rapidité et de l’efficacité de votre pipeline de données. Eh bien, il existe certaines mesures que vous pouvez mesurer o évaluer la vitesse d'un pipeline de données. Ces métriques fournissent des informations sur différents aspects des capacités de traitement du pipeline :
1. Débit
It mesure la vitesse à laquelle les données sont traitées avec succès par le pipeline sur une période spécifique.
Débit (enregistrements par seconde ou octets par seconde) = Total des enregistrements traités ou taille des données / Temps nécessaire au traitement
2. Latence
La latence est le temps nécessaire à une donnée pour parcourir l’ensemble du pipeline, de la source à la destination.
Latence = Temps de traitement de bout en bout pour un enregistrement de données
3. Délai de traitement
Il mesure le temps nécessaire pour transformer ou manipuler les données dans le pipeline.
Temps de traitement = Temps nécessaire à la transformation ou au traitement d'un enregistrement de données
4. Utilisation des ressources
L'utilisation des ressources mesure l'efficacité avec laquelle le pipeline utilise les ressources informatiques (CPU, mémoire, etc.) pendant le traitement des données.
Utilisation des ressources = (Utilisation réelle des ressources / Ressources maximales disponibles) * 100
Considérations clés en matière de conception
Lors de la définition d'une architecture de pipeline de données, il est important de garder à l'esprit certains facteurs et bonnes pratiques pour créer une architecture de pipeline de données robuste, évolutive et facile à gérer. Voici comment vous pouvez concevoir votre pipeline de données :
Modularité: La conception modulaire favorise la réutilisation du code, simplifie la maintenance et permet des mises à jour faciles des composants individuels. Décomposez le pipeline en modules ou services plus petits et indépendants. Chaque module doit avoir une responsabilité bien définie et la communication entre les modules doit être standardisée.
Tolérance aux pannes: L'intégration d'une tolérance aux pannes dans le pipeline garantit que le système peut récupérer facilement des erreurs et continuer à traiter les données. Mettre en œuvre le mécanismes de nouvelle tentative en cas de pannes transitoires, utilisation de points de contrôle pour suivre les progrès et configuration de la surveillance et des alertes en cas de conditions anormales.
orchestration: Les outils d'orchestration aident à planifier et à gérer le flux de données via le pipeline, garantissant que les tâches sont exécutées dans le bon ordre avec les dépendances appropriées. Vous pouvez utiliser des outils comme Astera Centerprise à dDéfinir des workflows qui représentent la séquence logique des activités du pipeline.
Traitement parallèle : Le traitement parallèle permet au pipeline de gérer plus efficacement de grands ensembles de données en répartissant les charges de travail sur plusieurs ressources. Astera Centerprise prend en charge un moteur ETL/ELT de traitement parallèle haute puissance que vous pouvez utiliser pour vos pipelines de données.
Partitionnement des données : Assurez-vous de choisir epartitionnement efficace des données comme ca améliore le parallélisme et les performances globales en répartissant les tâches de traitement des données sur plusieurs nœuds. Les techniques courantes incluent le partitionnement par plage, le partitionnement par hachage ou le partitionnement par liste.
Évolutivité: Gardez toujours à l’esprit l’évolutivité. Concevez le pipeline pour qu'il évolue horizontalement (en ajoutant plus d'instances) ou verticalement (en augmentant les ressources par instance). Tirez parti des services basés sur le cloud pour une mise à l'échelle automatique en fonction de la demande.
Contrôle de version: Utilisez des systèmes de contrôle de version comme Git pour le code du pipeline et les fichiers de configuration. Suivez les meilleures pratiques en matière de création de branches, de fusion et de documentation des modifications.
Test: Iimplémentez des tests unitaires pour les composants individuels, des tests d'intégration pour les flux de travail et des tests de bout en bout pour l'ensemble du pipeline. Inclure des tests pour qualité des données et les cas extrêmes. Tests rigoureux assurera que le pipeline fonctionne de manière fiable et répond toujours aux exigences de l'entreprise.
Améliorer continuellement l'architecture du pipeline de données
La définition de l'architecture du pipeline de données n'est pas un processus ponctuel ; tu dois garder identifier les domaines à améliorer, mettre en œuvre des changements et adapter l'architecture à l'évolution des besoins de l'entreprise et aux progrès technologiques. L'objectif est de garantir que le pipeline de données reste robuste, évolutif et capable de répondre aux exigences changeantes de l'organisation. Voici ce que vous pouvez faire:
- Surveiller régulièrement les performances et la santé du pipeline de données. Utilisez des outils de surveillance pour recueillir des mesures liées à l'utilisation des ressources, aux temps de traitement des données, aux taux d'erreur et à d'autres indicateurs pertinents. Analysez les données collectées pour identifier les goulots d'étranglement, les zones d'inefficacité ou les points de défaillance potentiels.
- Établissez des boucles de rétroaction qui permettent aux utilisateurs, aux ingénieurs de données et aux autres parties prenantes de fournir des informations et des commentaires sur les performances et les fonctionnalités du pipeline.
- Définir et examiner régulièrement les KPI pour le pipeline de données. Les mesures clés peuvent inclure le débit, la latence, les taux d'erreur et l'utilisation des ressources. Utilisez les KPI pour évaluer l’efficacité du pipeline de données et pour guider les efforts d’amélioration.
- Mettez en œuvre des améliorations progressives plutôt que de tenter des refontes majeures. Les petites améliorations ciblées sont plus faciles à gérer et peuvent être intégrées en permanence dans le pipeline existant. Priorisez les améliorations en fonction de leur impact sur les performances, la fiabilité et la satisfaction des utilisateurs.
Astera Centerprise-L'outil de pipeline de données automatisé sans code
Astera Centerprise est un outil de pipeline de données entièrement sans code doté d'une interface utilisateur visuelle et intuitive. L'outil a été conçu en gardant à l'esprit l'accessibilité des utilisateurs professionnels afin qu'ils puissent également créer des pipelines de données sans trop dépendre du service informatique. Vous souhaitez démarrer des pipelines de données auto-entretenus à volume élevé ? Essayez-le pour gratuit pendant 14 jours.



