
O Automatizado, Nenhum código Pilha de dados
Saiba como Astera O Data Stack pode simplificar e agilizar o gerenciamento de dados da sua empresa.

Modernize sua arquitetura de dados com uma abordagem de práticas recomendadas para modelagem de dados dimensional
A modelagem de dados dimensionais tem sido a base do projeto de data warehouse eficaz por décadas. A metodologia de Kimball promete desempenho de consulta otimizado e uma estrutura simplificada que é facilmente compreendida pelas partes interessadas em todos os níveis da empresa. Continue lendo para descobrir como nossa abordagem automatizada ajuda a implementar esse esquema para obter o máximo de eficácia em seu data warehouse.
Para construir uma arquitetura analítica verdadeiramente moderna que permite técnicas avançadas como aprendizado de máquina, análise preditiva, previsão e visualizações de dados, você precisa implementar a modelagem de dados dimensionais em seu data warehouse. Existem algumas marcas de verificação que um sistema de BI precisa atingir antes de se qualificar.
Primeiro, ele deve ser capaz de coletar e processar grandes volumes de dados de fontes transacionais distintas. Em segundo lugar, ele deve lidar com registros atuais e históricos. Terceiro, ele deve oferecer suporte a uma variedade de operações de consulta complexas e em constante mudança. Finalmente, ele precisa produzir dados atualizados e relevantes para seus usuários finais.
A chave para atender a essas expectativas está no estágio de design durante a modelagem de dados. As decisões que você tomar aqui afetarão diretamente a agilidade, o desempenho e a escalabilidade do seu data warehouse.
Mas por que modelagem de dados dimensionais?
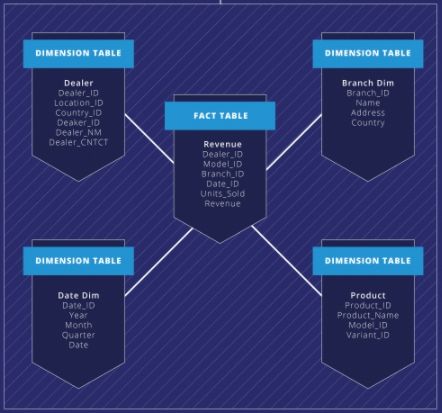
O esquema clássico em estrela
Digamos que você opte por um esquema 3NF, que minimiza a redundância de dados por meio da normalização. O número de armazenamento de tabelas aumentará substancialmente. Isso significa que qualquer consulta executada em um esquema 3NF envolveria muitas junções complexas.
Por comparação, modelagem dimensional As técnicas oferecem uma estrutura simplificada e desnormalizada que produz muito menos associações e, portanto, melhora o desempenho da consulta. Modelos de dados dimensionais também suportam dados mudando lentamente e dimensões específicas de data / hora, que facilitam a análise histórica. Esse esquema é mais facilmente compreendido pelos usuários finais, permitindo que eles colaborem com sua equipe de desenvolvimento usando uma linguagem comum. Como resultado, torna-se muito mais fácil construir um data warehouse em torno de processos de negócios reais e desenvolver o modelo de dados para abranger as necessidades em constante mudança de sua empresa.
Vejamos alguns fatores críticos que farão de seus modelos dimensionais um fator chave para o desenvolvimento de seu data warehouse.
Preste atenção ao grão

Encontrar o grão certo para sua tabela de fatos é essencial (dica: o trigo não funciona)
Encontrar o grão certo para sua linha da tabela de fatos é essencial (dica: o trigo não funcionará)
Normalmente, você desejará construir modelos dimensionais individuais para diferentes áreas de operação em sua empresa. Cada um desses processos terá um grão definido; este é o nível de detalhe no qual os dados são armazenados em tabelas de fatos e dimensões relacionadas. É essencial manter uma granulação consistente nos modelos de dados dimensionais para garantir o melhor desempenho e usabilidade durante a fase de consumo. Caso contrário, você pode acabar com relatórios e análises mal calculados.
Para um excelente exemplo disso, digamos que você esteja projetando um modelo de dados dimensional para seu processo de vendas. Você tem duas fontes diferentes nas quais os dados são registrados, uma rastreando faturas domésticas por transação e a outra rastreando pedidos gerados globalmente por mês. Uma tabela é muito mais adequada para fatiar e dividir dados posteriormente, enquanto a última fornece essencialmente uma visão resumida do processo de vendas, que só será útil em relatórios de alto nível e inteligência de negócios.
Em geral, quando os dados estão relacionados a diferentes processos de negócios, você pode supor que vários modelos precisarão ser construídos. Portanto, você precisa ser capaz de projetar esses esquemas com precisão com base nos relacionamentos de entidade identificados no sistema de origem. Os fatos e as tabelas de dimensão devem ser atribuídos corretamente no nível de detalhe apropriado.
Movendo-se para um processo que permite automatizar a modelagem de esquema inicial, você pode garantir que esses conceitos básicos sejam aplicados corretamente ao seu esquema. A partir daí, você pode trabalhar para moldá-lo mais de acordo com seus requisitos de BI. Mais importante, você pode atualizar facilmente seus modelos para refletir as mudanças no sistema de origem ou nos requisitos do usuário final e, em seguida, propagar essas mudanças em seus pipelines de dados sem um extenso retrabalho manual.
Outro detalhe crítico para obter sua abordagem certa é garantir que sua abordagem de modelagem dimensional inclua tabelas de dimensão de data. Essas tabelas fornecem vários tipos de medidas específicas de data, como diário, mensal, anual, trimestres fiscais ou feriados. Em última análise, isso ajudará os usuários finais a filtrar e agrupar seus dados com mais eficiência durante a fase de consumo.
Manipule automaticamente seus dados que mudam lentamente

Esses registros históricos podem ser úteis (https://xkcd.com/2075/)
Os processos de negócios estão em um estágio constante de mudança. Os funcionários ingressam na organização, são promovidos e, eventualmente, se aposentam. Os clientes mudam para um novo endereço ou alteram seus detalhes de contato. Em alguns casos, departamentos inteiros são absorvidos, renomeados ou reestruturados. Portanto, você deve garantir que seu modelo dimensional possa refletir este ambiente dinâmico com precisão.
Aplicando o técnica correta de manuseio de SCD para seus modelos de dados dimensionais, você pode levar em conta as alterações nos registros no sistema de origem e, se necessário, preservar os dados históricos para análise posterior. Agora, existem vários tipos de SCD disponíveis com base em seus requisitos. As técnicas variam de SCD Tipo 1 para sobrescrever valores anteriores até SCD Tipo 3 que atualiza o registro atual enquanto adiciona um novo campo para mostrar o valor anterior para o atributo.
A tabela de dimensão também pode conter campos adicionais para refletir quando uma determinada alteração entrou em vigor (Data de Vigência / Data de Expiração) ou a moeda de um registro específico (Versão), caso várias alterações tenham sido feitas nele ao longo dos anos. Você pode até ter um indicador de sinalizador ativo para denotar qual versão de um registro está em uso no momento do relatório.
Uma ressalva aqui é que é complicado facilitar essas inserções e atualizações durante o carregamento manual do data warehouse. Afinal, estamos falando sobre a implementação de processos para verificar automaticamente as alterações no registro do sistema de origem e, em seguida, identificar se os registros devem ser substituídos ou atualizados. No último caso, várias novas chaves substitutas podem precisar ser geradas, para não mencionar vários novos campos. Você também terá que criar mapeamento de dados para todas essas atividades.
Se você estiver desenvolvendo seu data warehouse com a ajuda de uma ferramenta de modelagem de dados dimensionais que segue uma abordagem orientada a metadados sem código, você pode simplesmente atribuir os tipos de SCD relevantes aos atributos no nível lógico. Em seguida, esses detalhes serão propagados para um mecanismo ETL que pode lidar automaticamente com inserções / atualizações subsequentes, junções e considerações de mapeamento de dados sem nenhum esforço manual.
Simplifique o carregamento da tabela de fatos

Todos os pipelines de dados levam a tabelas de fatos e dimensões
O carregamento da tabela de fatos é outra área que apresenta muitos esforços manuais adicionais durante o desenvolvimento do pipeline de dados. Este processo envolve a engenharia de múltiplas junções entre tabelas de dimensão. Considerando que as tabelas de fatos geralmente contêm milhões de registros, o alto custo de execução dessa operação é aparente.
Cada vez que a tabela de fatos é preenchida, as pesquisas no modelo de dados dimensionais fazem referência cruzada de cada chave comercial com a tabela de dimensão relevante e a convertem em uma chave substituta. Suponha que a tabela de dimensões seja particularmente grande ou várias alterações tenham sido feitas nos registros de origem (no caso de dimensões que mudam lentamente). Nesse caso, a pesquisa pode se tornar particularmente demorada e consumir muitos recursos. Obviamente, essa tarefa será repetida de forma consistente, pois os dados transacionais são atualizados constantemente.
Em muitos casos, pode ser necessário criar um mesa de palco entre o sistema de origem e o data warehouse para armazenar todos esses dados históricos e, assim, tornar mais fácil processá-los durante o carregamento.
Você também pode ter que executar mapeamentos de dados hierárquicos avançados de sistemas de origem para garantir que os dados na granulação correta estejam sendo carregados na tabela de fatos.
Agora, se voltarmos para o abordagem baseada em metadados descrito anteriormente, podemos encontrar uma maneira de acelerar esse processo radicalmente. Se, em vez disso, você configurar atributos de fato no modelo de dados dimensionais, então usar essas entidades no pipeline de dados, as junções e pesquisas necessárias para o preenchimento do data warehouse podem ser realizadas automaticamente pelo mecanismo ETL / ELT subjacente.
Implementar processos para lidar com fatos que chegam cedo

Às vezes, a realidade de seu ambiente de negócios pode não se ajustar perfeitamente aos requisitos de um esquema padrão.
Por exemplo, uma ID de funcionário pode ser gerada para um recruta antes que a organização tenha qualquer informação sobre quem ele é ou até mesmo uma data de ingresso específica para o candidato. Se você construiu um modelo de dados dimensionais para refletir seu processo de RH, este cenário resultará em um registro da tabela de fatos sem quaisquer atributos dimensionais relacionados. Essencialmente, uma pesquisa de chave estrangeira com falha.
Agora, neste caso, é uma questão de esperar que as informações desejadas cheguem, então a melhor abordagem é substituir os dados ausentes por uma dimensão de espaço reservado contendo valores padrão. Então, uma vez que os detalhes do funcionário são registrados em sua totalidade, os atributos podem ser atualizados na tabela relevante. Em outros casos, você pode não querer processar o registro, caso em que deseja que a entrada seja sinalizada ou omitida completamente durante o preenchimento do data warehouse.
Independentemente de como você lida com essas situações, seu modelo de dados dimensionais deve permitir configurações dinâmicas que refletem a natureza de seus negócios.
Modelos de dados dimensionais enriquecidos com metadados de engenheiro em velocidade com Astera Construtor de DW
Astera Construtor de DW é uma ferramenta de modelagem de dados dimensionais abrangente que permite a você projetar modelos dimensionais abrangentes de um sistema transacional em minutos.
Nosso mecanismo intuitivo pode desenvolver automaticamente um esquema de melhor ajuste atribuindo fatos e dimensões com base nos relacionamentos de entidade contidos no banco de dados de origem. Como alternativa, você pode usar a caixa de ferramentas rica em recursos do ADWB para criar seu próprio modelo dimensional do zero, completo com tabelas de dimensão de fatos, dimensões e datas. Em seguida, basta configurar cada entidade com os atributos necessários, incluindo tipos de SCD, chaves substitutas, chaves de negócios e outros metadados de identificação.
Também oferecemos várias funcionalidades para acelerar o processo de carregamento do data warehouse, incluindo carregadores de dados e dimensões dedicados para agilizar a transferência de dados para o seu destino. O ADWB também fornece um objeto de consulta de modelo de dados desenvolvido para um propósito que permite juntar várias tabelas de sistema de origem para criar uma entidade de origem hierárquica que você pode mapear facilmente para tabelas de data warehouse relevantes.
Para dar uma olhada mais de perto Astera Capacidades de modelagem dimensional e automação de data warehouse do DW Builder, entrar em contato conosco agora. Ou confira o produto para você.



