
O Automatizado, Nenhum código Pilha de dados
Saiba como Astera O Data Stack pode simplificar e agilizar o gerenciamento de dados da sua empresa.

Pipeline de dados versus pipeline de ETL: qual é a diferença?
Nos últimos anos, diversas características do Tubulações ETL passaram por alterações gigantescas. Devido ao surgimento de novas tecnologias, como aprendizado de máquina (ML) e tecnologias modernas pipelines de dados, os processos de gerenciamento de dados das empresas estão progredindo continuamente. A quantidade de dados acessíveis também cresce anualmente a passos largos.
Os engenheiros de dados se referem a essa rota de ponta a ponta como 'pipelines' de dados ETL, onde cada pipeline tem uma ou várias fontes e sistemas de destino para acessar e manipular os dados disponíveis. Esse processo de mover dados de uma origem para um destino é crucial em qualquer tipo de pipeline de dados.
Dentro de cada pipeline, os dados passam por transformação, validação, normalização e outros processos. Pipelines ETL e pipelines de dados podem envolver streaming de dados e processamento em lote. Um pipeline de dados pode incluir ETL e qualquer outra atividade ou processo que envolva a movimentação de dados de um lugar para outro.
Então, qual é a diferença entre um pipeline ETL e um pipeline de dados? Vamos explorar detalhadamente o pipeline de dados versus ETL e as principais diferenças entre os dois.
O que é um pipeline ETL?
ETL significa extrair, transformar e carregar. Então, por definição, umn Pipeline ETL é um conjunto de processos que inclui a extração de dados de uma variedade de fontes e sua transformação. Os dados são subseqüentemente carregado nos sistemas de destino, como uma nuvem armazém de dados, data mart, ou um banco de dados para análise ou outros propósitos.
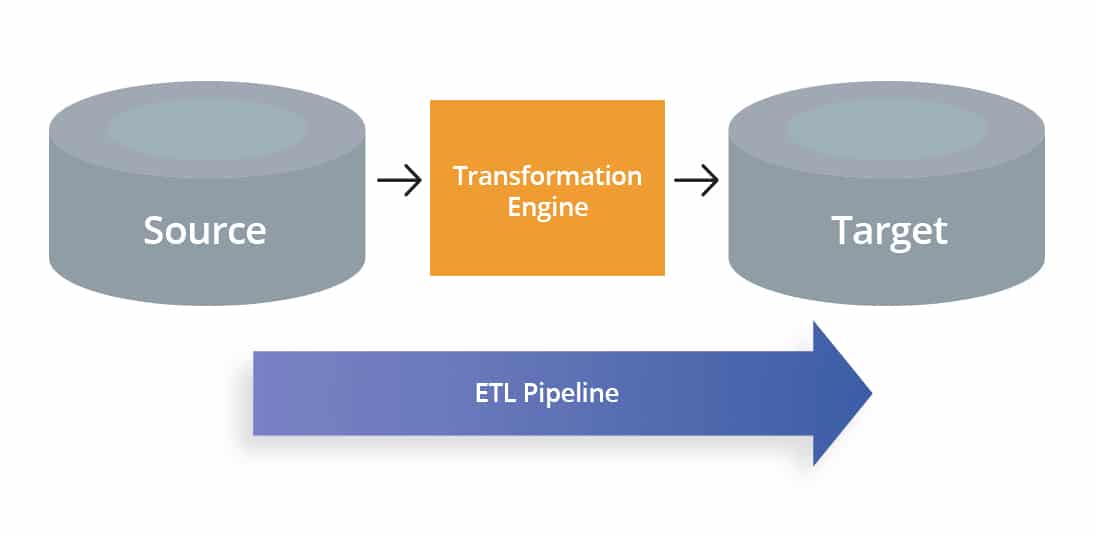
Durante a extração, o sistema ingere dados de várias fontes heterogêneas, como sistemas de negócios, aplicativos, sensores e bancos de dados. A próxima etapa envolve a transformação dos dados brutos em um formato exigido pelo aplicativo final.
Por fim, os dados transformados são carregados em um data warehouse ou banco de dados de destino. Adicionalmente, pode ser publicado como uma API para ser compartilhado com as partes interessadas.
O objetivo principal por trás da construção de um pipeline de ETL é adquirir os dados corretos, prepará-los para relatórios e salvá-los para acesso e análise rápidos e fáceis. Ferramentas ETL ajuda usuários corporativos e desenvolvedores a liberar tempo e se concentrar em outras atividades comerciais essenciais. As empresas podem construir pipelines de ETL usando estratégias diferentes com base em seus requisitos exclusivos.
Os pipelines ETL são usados em vários processos de dados, como:
Exemplos de pipeline ETL
Existem vários cenários de negócios onde os pipelines ETL podem ser usados para fornecer decisões mais rápidas e de qualidade superior. Os pipelines ETL são úteis para centralizar todas as fontes de dados, o que ajuda a empresa a visualizar uma versão consolidada de seus ativos de dados.
Por exemplo, o departamento de CRM pode usar um pipeline ETL para extrair dados dos clientes de vários pontos de contato na jornada do cliente. Isso pode permitir ainda mais que o departamento crie painéis detalhados que podem atuar como uma única fonte para todos Informação ao Cliente de diferentes plataformas.
Da mesma forma, muitas vezes há uma necessidade de mover e transformar dados entre vários armazenamentos de dados internamente, já que é difícil para um usuário de negócios analisar e dar sentido aos dados espalhados por diferentes sistemas de informação.
Benefícios de um pipeline ETL
Tomada de decisão eficiente: Com um pipeline ETL instalado, os usuários finais podem acessar rapidamente os dados de que precisam, permitindo tomadas de decisão mais rápidas e reduzindo o tempo necessário para preparação e processamento de dados.
Processamento de dados escalonável: Os pipelines ETL lidam com grandes volumes de dados com eficiência, permitindo que os usuários finais escalem seus recursos de processamento de dados sem sacrificar o desempenho.
Acessibilidade de dados aprimorada: Os pipelines ETL tornam os dados facilmente acessíveis aos usuários finais, integrando e centralizando dados de várias fontes, eliminando a recuperação e agregação manuais de dados.
O que é um pipeline de dados?
Um pipeline de dados se refere às etapas envolvidas na movimentação de dados do sistema de origem para o sistema de destino. Essas etapas incluem copiar dados, transferi-los de um local no local para a nuvem e combiná-los com outras fontes de dados. O objetivo principal de um pipeline de dados é garantir que todas essas etapas ocorram de forma consistente para todos os dados.
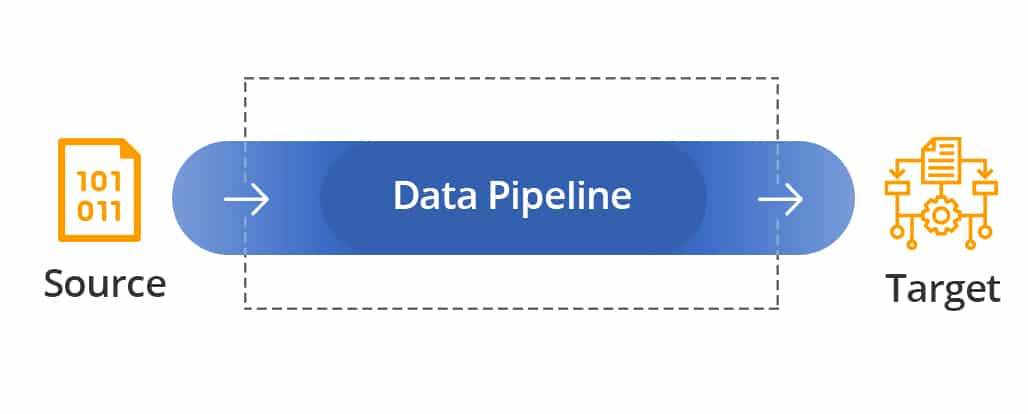
Se administrado astutamente com ferramentas de pipeline de dados, um pipeline de dados pode oferecer às empresas acesso a conjuntos de dados consistentes e bem estruturados para análise. Engenheiros de dados podem consolidar informação de numeroso fontes e usá-lo propositalmente, sistematizando a transferência e transformação de dados. Por exemplo, an AWS O pipeline de dados permite que os usuários movam dados livremente entre os dados locais da AWS e outros recursos de armazenamento.
Exemplos de pipeline de dados
Os pipelines de dados são úteis para buscar e analisar informações de dados com precisão. A tecnologia é útil para indivíduos que armazenam e dependem de várias fontes de dados em silos, exigem análise de dados em tempo real ou têm seus dados armazenados na nuvem.
Por exemplo, as ferramentas de pipeline de dados podem executar análise preditiva para compreender as tendências futuras potenciais. Um departamento de produção pode usar a análise preditiva para saber quando a matéria-prima provavelmente acabará. A análise preditiva também pode ajudar a prever qual fornecedor pode causar atrasos. O uso de ferramentas eficientes de pipeline de dados resulta em insights que podem ajudar o departamento de produção a otimizar suas operações.
Diferença entre ETL e pipelines de dados
Embora ETL e pipelines de dados estejam relacionados, eles são bastante diferentes um do outro. No entanto, as pessoas costumam usar os dois termos de forma intercambiável. Ambos os oleodutos são responsáveis por mover dados de um sistema para outro; a principal diferença está na aplicação.
ETL x Data Pipeline – entendendo a diferença
O pipeline ETL inclui uma série de processos que extrato dados de uma origem, transformá-los e carregá-los no sistema de destino. Por outro lado, um pipeline de dados é uma terminologia um pouco mais ampla que inclui um pipeline ETL como um subconjunto. Inclui um conjunto de ferramentas de processamento que transferir dados de um sistema para outro. No entanto, os dados podem ou não ser transformados.
Propósito
A finalidade de um pipeline de dados é transferir dados de fontes, como processos de negócios, sistemas de rastreamento de eventos e bancos de dados, para um data warehouse para inteligência de negócios e análise. Em contraste, o propósito do ETL é extrair, transformar e carregar dados em um sistema de destino.
A sequência é crítica. Depois de extrair os dados da fonte, você deve encaixá-los em um modelo de dados gerado de acordo com seus requisitos de inteligência de negócios. Isso envolve acumular, limpar e transformar os dados. Finalmente, você carrega os dados resultantes em seu data warehouse.
Como o pipeline funciona
Um pipeline ETL normalmente funciona em processamento em lote, o que significa que os dados se movem em um grande bloco em um determinado momento para o sistema de destino. Por exemplo, o pipeline pode ser executado uma vez a cada doze horas. Você pode até mesmo organizar os lotes para serem executados em um horário específico diariamente quando houver baixo tráfego no sistema.
Pelo contrário, um pipeline de dados também pode operar como um processo em tempo real, gerenciando cada evento à medida que ocorre, em vez de processá-lo em lotes. Durante o streaming de dados, ele lida com um fluxo contínuo adequado para dados que requerem atualização contínua. Por exemplo, para transferir dados coletados de um tráfego de rastreamento de sensor.
Além disso, o pipeline de dados não precisa terminar com o carregamento de dados em um banco de dados ou data warehouse. Você pode carregar dados em qualquer número de sistemas de destino, como um bucket da Amazon Web Services ou um data lake. Ele também pode iniciar processos de negócios ativando webhooks em outros sistemas.
Pipeline de dados versus pipeline ETL: qual você deve escolher?
Nem é preciso dizer que a escolha entre um pipeline de dados e um pipeline ETL depende muito de suas necessidades específicas de integração de dados. Os pipelines ETL, sendo a escolha tradicional para muitas empresas, são adequados para cenários onde atualizações regulares e programadas são suficientes. Por outro lado, um pipeline de dados é uma solução mais versátil, abrangendo não apenas ETL, mas também streaming e orquestração de dados em tempo real. Se você precisar de agilidade e adaptabilidade, especialmente no tratamento de diversas fontes de dados e necessidades de processamento dinâmico, um pipeline de dados pode ser mais adequado.
Veja como você pode decidir entre pipeline ETL e pipeline de dados:
Caso de uso
Considere a natureza dos seus dados e os requisitos dos seus processos de negócios. Os pipelines ETL são adequados para cenários onde os dados podem ser processados em lotes, tornando-os eficientes para lidar com grandes volumes de dados históricos. Por outro lado, os pipelines de dados são mais versáteis, acomodando streaming de dados em tempo real para casos de uso que exigem insights e ações imediatas com base nas atualizações de dados mais recentes.
Por exemplo, se você estiver lidando com transações financeiras ou monitorando tendências de mídia social em tempo real, um pipeline de dados pode ser a escolha preferida para garantir uma tomada de decisão oportuna.
Flexibilidade
Os pipelines ETL podem lidar com dados não estruturados ou semiestruturados durante a fase de transformação. Este processo envolve limpeza, enriquecimento e estruturação de dados para análise e armazenamento. Por outro lado, pipelines de dados simples, projetados para streaming contínuo, são mais adequados para fontes de dados homogêneas onde um formato consistente é mantido. Eles gerenciam com eficiência o fluxo constante de dados, mas podem não fornecer o mesmo nível de recursos de transformação complexos que os pipelines ETL para estruturas de dados complexas e variadas.
Complexidade
No que diz respeito à complexidade, os pipelines ETL envolvem mais esforços iniciais de design e desenvolvimento em comparação com pipelines de dados, especialmente devido ao processo de transformação de dados. No entanto, esses esforços são significativamente reduzidos, pois as ferramentas ETL modernas fazem a maior parte do trabalho pesado.
Ferramentas e ecossistema
Falando em ferramentas, as ferramentas e o ecossistema também desempenham um papel no processo de tomada de decisão. Os pipelines de ETL possuem um conjunto bem estabelecido de ferramentas e estruturas, muitas vezes fortemente integrados a data warehouses e sistemas tradicionais de business intelligence. Isso os torna uma escolha confiável para organizações com sistemas legados e um ambiente de dados estruturado.
Por outro lado, os pipelines de dados aproveitam um ecossistema mais amplo, incorporando tecnologias como Apache Kafka, Apache Flink ou Apache Spark para processamento de dados em tempo real. Eles se alinham bem com a tendência crescente de tecnologias de big data e soluções baseadas em nuvem, proporcionando escalabilidade e flexibilidade na escolha de ferramentas que melhor se adaptam a casos de uso específicos. Em última análise, a escolha entre um pipeline de dados e um pipeline ETL depende da natureza dos seus dados, dos requisitos de processamento e do nível de flexibilidade e recursos em tempo real que sua integração exige.
Pipeline de dados vs ETL: principal vantagem
Embora usados de forma intercambiável, ETL e pipelines de dados são dois termos diferentes. As ferramentas ETL extraem, transformam e carregam dados, enquanto as ferramentas de pipeline de dados podem ou não incorporar a transformação de dados.
Ambas as metodologias têm seus prós e contras. A transferência de dados de um local para outro significa que vários operadores podem responder a uma consulta de forma sistemática e correta, em vez de passar por diversas fontes de dados.
Um pipeline de dados bem estruturado e um pipeline de ETL melhoram a eficiência do gerenciamento de dados. Eles também tornam mais fácil para os gerentes de dados fazer iterações rapidamente para atender aos requisitos de dados em evolução do negócio.
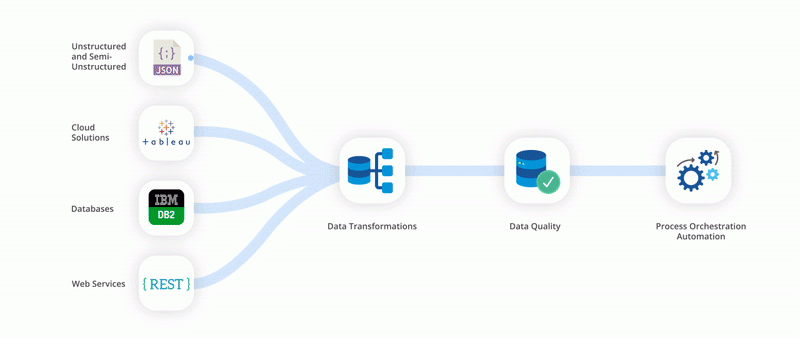
O importante a lembrar é que talvez você não precise escolher entre implementar um pipeline de dados ou um pipeline de ETL, pois eles podem ser usados juntos estrategicamente. Em muitos cenários do mundo real, é uma questão de aproveitá-los em conjunto para atender às necessidades específicas do negócio. Por exemplo, você pode usar pipelines ETL para lidar com dados estruturados e orientados em lote com transformações bem definidas. Isto pode ser particularmente útil ao lidar com dados históricos ou cenários onde atualizações periódicas são suficientes. Enquanto isso, o pipeline de dados mais amplo pode lidar com streaming de dados em tempo real, orquestração e outras tarefas que vão além do ETL tradicional.
Então, se você estiver comparando diferentes ferramentas de integração de dados para executar seu ETL ou pipelines de dados, forneça Astera uma tentativa! Você também pode se inscrever para uma demonstração ou falar com nosso representante de vendas para discutir seu caso de uso gratuitamente.



