
O Automatizado, Nenhum código Pilha de dados
Saiba como Astera O Data Stack pode simplificar e agilizar o gerenciamento de dados da sua empresa.

Leitura e mapeamento de arquivos acionados por sinônimo Astera Centerprise
Os dados são a força vital da economia moderna, e qualquer empresa que pretenda obter valor tangível de seus ativos de informação deve aprender a gerenciar e maximizar os vários insumos que chegam em suas funções. No entanto, essa tarefa tornou-se cada vez mais desafiadora no mercado globalizado de hoje, onde a maioria das empresas opera em redes dispersas, compostas por parceiros de negócios, revendedores, fornecedores, preocupações de irmãs e muito mais. Essas redes geralmente estão sujeitas a diversos fatores regulatórios, geopolíticos e econômicos que afetam a forma como cada parte prepara e apresenta seus dados.
Nesse ambiente, as grandes organizações devem garantir que eles tenham processos eficazes para coletar e integrar dados de fontes diferentes de terceiros de maneira oportuna e econômica. Caso contrário, os riscos e oportunidades potenciais que poderiam ter sido descobertos podem ser totalmente esquecidos.
Com o Astera CenterpriseCom a nova funcionalidade de correspondência inteligente, os clientes podem automatizar como as inconsistências de dados e as irregularidades de formatação são tratadas em seus pipelines ETL e ELT.
Neste documento, forneceremos uma rápida visão geral de alguns motivos que tornam a integração de aplicativos de terceiros complexa, além de um caso de uso detalhado de como o recurso de leitura e mapeamento de arquivos orientado por sinônimos pode ser empregado em Astera Centerprise para enfrentar o desafio.
Gerenciando dados externos: vantagens e desafios
Do Washington Post que usa dados sobre cliques e engajamento dos leitores para melhorar os fluxos de trabalho da redação para a The Climate Corporation, que usa dados geopolíticos, climáticos e de IoT para ajudar os agricultores a prever e otimizar o rendimento das colheitas, há vários exemplos disponíveis que demonstram como otimizar a integração de dados internos e externos cria vantagens competitivas. Infelizmente, a enorme quantidade e variedade de dados gerados externamente podem tornar esse processo extremamente intensivo em recursos.
Os desafios enfrentados ao lidar com dados externos podem ser categorizados com base na fase do ciclo de vida dos dados em que ocorrem, ou seja, extração, transformação e carregamento / integração. Figura 1 contém uma visão geral não exaustiva desses desafios.
Figura 1: Desafios do uso de dados externos |
|
| Fase 1: Extração ou aquisição de dados externos | Incapacidade de integrar fontes de dados externas |
| Vários usuários têm acesso ao mesmo conjunto de dados (duplicação de dados) | |
| Versões diferentes de um único conjunto de dados | |
| Fase 2: transformando dados externos | Inconsistências entre dados externos e internos |
| Tratamento de imprecisões em dados externos | |
| Fase 3: carregando dados em um repositório de dados centralizado | Projetando um data warehouse para lidar com fluxos de dados estruturados e não estruturados |
|
Servindo conjuntos de dados personalizados para usuários corporativos por meio de APIs |
|
Vamos nos concentrar no desafio de lidar com a variação nos dados coletados de aplicativos de terceiros e garantir a consistência entre dados internos e externos usando o recurso de leitura e mapeamento de arquivos orientado por sinônimos em Astera Centerprise.
Obtendo consistência de dados com leitura e mapeamento de arquivos acionados por sinônimo
Ocorrem inconsistências de sinônimos de layout entre sistemas de origem e estruturas de relatório em repositórios únicos, como bancos de dados, bem como arquiteturas consolidadas, como data warehouses e sistemas de banco de dados federados. No último caso, onde várias fontes de dados são reunidas e combinadas para relatórios e análises, é provável que haja muito mais variações na nomenclatura e formatação dos layouts de dados de entrada.
Uma das maneiras de obter consistência de layout é analisar fontes individuais, identificar e resolver todas as inconsistências de cabeçalho manualmente e, em seguida, reconstruir os fluxos de dados relacionados com base nas entradas corrigidas. Além disso, a consistência dos dados não pode ser alcançada por um processo que funciona isoladamente e deve basear-se em padrões abrangentes que são aplicados a todos os conjuntos de dados que entram na organização. Esses problemas só se tornarão mais pronunciados à medida que o número de fontes externas aumentar.
A leitura e o mapeamento de arquivos baseados em sinônimos fornecem um método intuitivo e escalonável de resolver conflitos e inconsistências de nomenclatura que surgem durante integrações de grande volume de dados por meio de sinônimos baseados em dados. Com esse recurso orientado por sinônimos, os usuários podem construir uma biblioteca personalizada que contém valores para valores atuais e alternativos que podem aparecer no campo de cabeçalho de uma tabela de entrada. Centerprise ele corresponderá automaticamente os cabeçalhos irregulares à coluna correta no tempo de execução e extrairá os dados deles normalmente.
Os objetos de origem variantes também podem ser facilmente integrados aos fluxos de dados existentes por meio de um novo recurso de automação automática que permite que os campos anômalos correspondam aos valores correspondentes nas transformações subseqüentes e nas entidades de destino.
O recurso SmartMatch: um caso de uso de vários clientes
Para entender melhor como o recurso funciona Astera Centerprise, vamos considerar o exemplo de uma empresa de seguro de carro com o nome XYZ que fornece processamento de solicitações de seguro para as empresas clientes e clientes individuais. A empresa recebe dados de reclamações que precisam ser extraídos, filtrados, limpos e entregues aos departamentos envolvidos.
O restante do processo consiste em analisar os dados, imprimir os formulários apropriados e enviá-los pelo remetente. Um gargalo crítico que afeta a eficiência de uma organização é a integração de dados de reclamações recebidos de várias empresas clientes e clientes para processamento adicional.
Muitos dos clientes maiores ainda dependem da entrada manual de dados para coletar dados de sinistros em planilhas antes de enviá-los à empresa de seguros. Como resultado, muitas das informações de política recebidas seguem um formato fora do padrão, com as convenções de nomenclatura variando significativamente com base no requerente. Atualmente, os administradores de TI da XYZ são forçados a resolver essas discrepâncias criando novos pipelines de fluxo de dados para cada fonte individual.
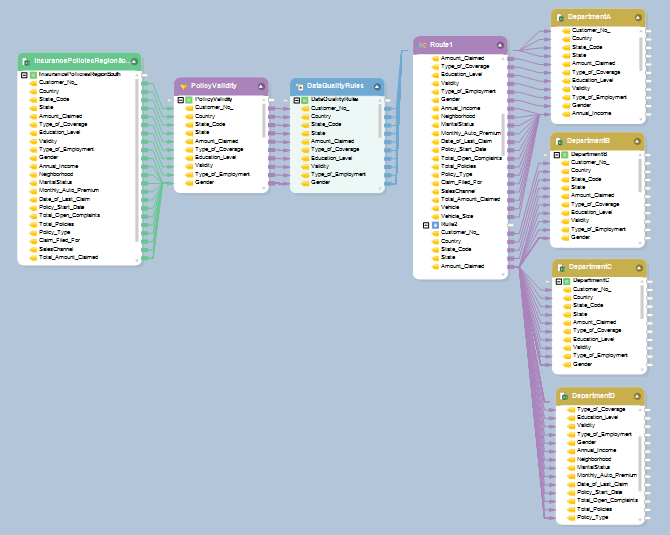
Fluxo de dados de processamento de reclamações para grandes clientes - seguradoras XYZ
Com a funcionalidade SmartMatch habilitada, um único fluxo de dados pode ser usado para processar vários arquivos de reclamante, apesar das diferentes convenções de nomenclatura. Para isso, ele simplesmente cria um sinônimo para o setor de seguros em termos de dicionário de arquivos que pode ser implementado em seu projeto de processamento de sinistros.
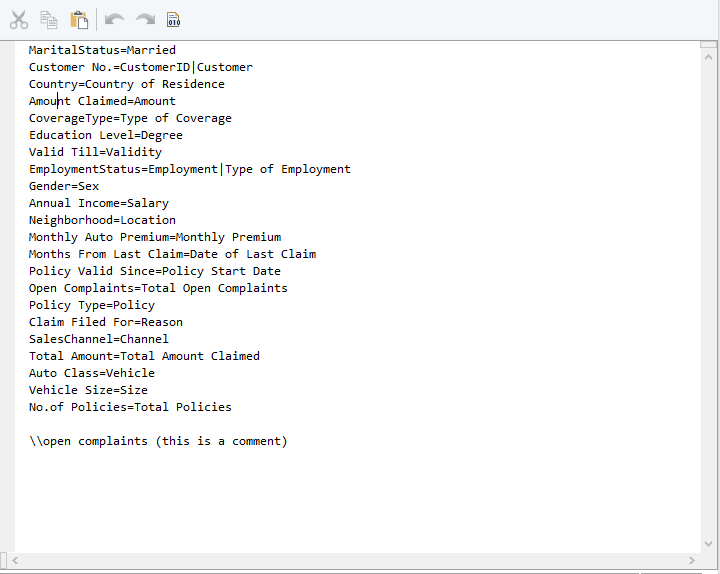
Dicionário de arquivos sinônimo para seguradoras XYZ
Em seguida, eles criam um fluxo de trabalho em loop configurado para coletar arquivos do Excel transmitidos de vários requerentes e executá-los no fluxo de dados original continuamente.
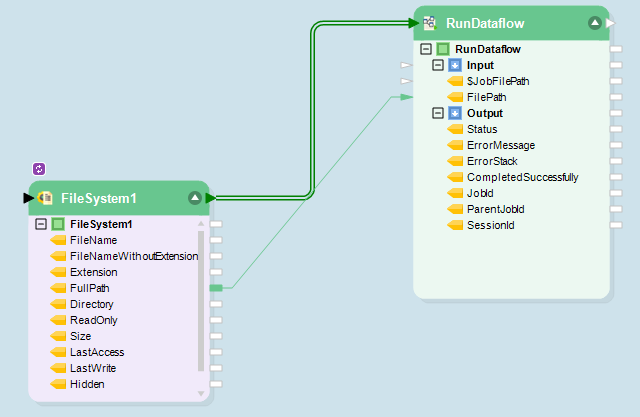
Fluxo de trabalho da seguradora XYZ
Quando o fluxo de trabalho é iniciado, o objeto de origem do fluxo de dados primeiro procura uma correspondência exata do cabeçalho nas colunas de arquivo do Excel de entrada, conforme especificado no layout original. Se isso não for encontrado, então Centerprise pesquisará cabeçalhos que correspondam exatamente às definições alternativas fornecidas no dicionário do arquivo sinônimo acima, ou seja, "Renda anual = salário ”. Definições adicionais são criadas usando o comando '' | '' - ou seja, "Nº do cliente = Identificação do cliente | Cliente ”

O SmartMatch também permite a correspondência de token, o que significa que definições alternativas podem ser configuradas para valores parciais que podem ser repetidos em vários cabeçalhos em um objeto de origem de entrada. Por exemplo "No. = Número | # ” Se o XYZ usou esse token em seu dicionário de sinônimos, todas as fontes de entrada que usaram as convenções de nomenclatura alternativas fornecidas para o valor Não. pode ser integrado ao fluxo de dados existente sem nenhum ajuste manual.
Se o recurso SmartMatch ainda não conseguir resolver inconsistências de cabeçalho em novos arquivos de entrada, Centerprise empregará correspondência de string compacta. Isso significa que todos os sinais de pontuação e espaços serão removidos dos nomes das colunas de entrada e comparados com as definições no layout e no dicionário originais. Por exemplo, um requerente pode definir sua Política válida desde campo sob o cabeçalho Política: Data de Início - como você pode ver, esse valor não corresponde a nenhuma das definições descritas acima. Como resultado, a correspondência de cadeia compacta removerá os dois pontos e tentará reconciliar as irregularidades.
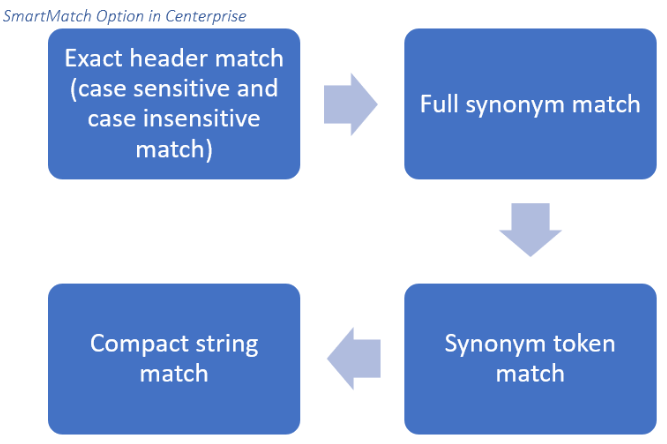
Processo de correspondência inteligente
SmartMatch e mapeamento automático
O SmartMatch também é eficaz na reconciliação de qualquer irregularidade que ocorra entre dois objetos em um fluxo de dados. Por exemplo, se um dos departamentos de recebimento da XYZ definir determinados campos de maneira diferente do objeto de origem, a opção de mapeamento automático poderá ajudar a isolar essas discrepâncias. Uma vez identificados, os usuários podem adicionar a definição ausente ao dicionário de sinônimos e garantir a execução ininterrupta do fluxo de dados.
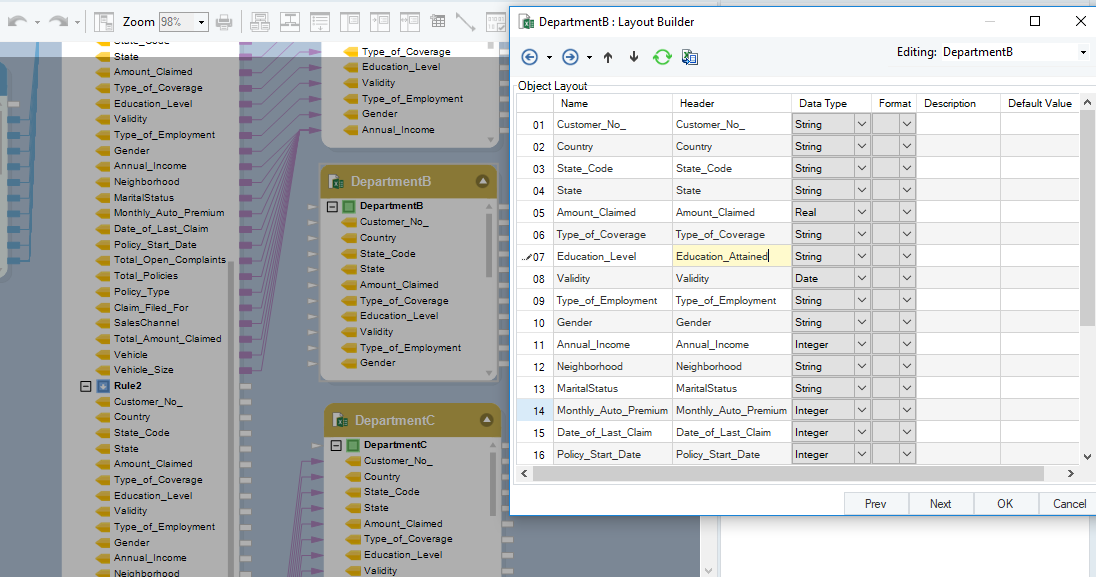
O mapeamento automático mostra discrepâncias
Como você pode ver, o Nível de educação campo é definido como Educação_ Atingido no layout do departamento B. Essa diferença nas convenções de nomenclatura pode ser resolvida no arquivo de dicionário por meio de uma definição exata ou de correspondência de token. O mapeamento automático é então simplesmente executado novamente e o campo não mapeado será integrado ao fluxo de dados.
A variedade de recursos do SmartMatch descritos neste blog podem ajudar organizações em qualquer setor a criar pipelines de dados mais adaptáveis e escaláveis, que são mais bem projetados para lidar com uma ampla variedade de fontes externas e internas. Explore este recurso em primeira mão baixando a versão de teste do Astera Centerprise 8.0.



