The Automated, No-Code Data Stack
Learn how Astera Data Stack can simplify and streamline your enterprise’s data management.

3 Ways to Transfer Data from Amazon S3 to Redshift
With social media, sensors, and IoT devices breathing life in every appliance, we generate volumes of data every day. More data is always good news until your storage bill starts increasing and it becomes difficult to manage. Unstructured data is expected to increase to 175 billion zettabytes by 2025. While cloud services such as Amazon S3 have enabled organizations to manage these massive volumes of data when it comes to analysis, storage solutions do not suffice, and this is where data warehouse such as Amazon Redshift comes into the picture.
Companies often use both Amazon services in tandem to manage costs and data agility or they use Amazon S3 as a staging area while building a data warehouse on Amazon Redshift. However, you can only realize the true potential of both services if you can achieve a seamless connection from Amazon S3 to Redshift. Astera Centerprise is a code-free solution that can help you integrate both services without hassle. Let’s explore some benefits of AWS Redshift and Amazon S3 and how you can connect them with ease.
Upgrade Querying Speed with AWS Redshift
AWS Redshift is a fully managed cloud data warehouse deployed on AWS services. The data warehouse has been designed for complex, high-volume analysis, and can easily scale up to handle petabytes of data. It allows you to extract meaningful insights from your data, so you do not leave your decisions to your gut instinct.
There are several reasons why AWS Redshift can add real value to your data architecture:
- As a robust cloud data warehouse, it can query large data sets without a significant lag.
- With an interface like MYSQL, the data warehouse is easy-to-use, which makes it easier to add it to your data architecture
- Since it is on the cloud, you can scale it up and down easily without investing in hardware.
While AWS Redshift can handle your data analysis needs, it is not an ideal solution for storage, and it is mainly because of its pricing structure. AWS Redshift charges you on an hourly basis. So, while costs start small, they can quickly swell up.
Amazon S3 for Storage
If you are thinking of complementing Amazon S3 with Redshift, then the simple answer is that you should. Amazon S3 is a fast, scalable, and cost-efficient storage option for organizations. As object storage, it is especially a perfect solution for storing unstructured data and historical data.
The cloud storage offers 99.9999% durability, so your data is always available and secure. Your data is replicated across multiple regions for backup and its multi-region access points ensure that you don’t face any latency issues while accessing data. Moreover, S3 provides comprehensive storage management features to help you keep a tab on your data.
Techniques for Moving Data from Amazon S3 to Redshift
There are a few methods you can use to send data from Amazon S3 to Redshift. You can leverage built-in commands, send it through AWS services, or you can use a third-party tool such as Astera Centerprise.
- COPY command: The COPY command is a built-in in Redshift. You can use this to connect the data warehouse with other sources without the need for any other tools.
- AWS services: There are several AWS services, such as AWS Glue and AWS Data Pipeline that can help you transfer data.
- Astera Centerprise: It is an end-to-end data integration platform that allows you to send data from various sources to popular data warehouses and database destinations of your choice without writing a single line of code.
Copy Command to Move Data from Amazon S3 to Redshift
Amazon Redshift is equipped with an option that lets you copy data from Amazon S3 to Redshift with INSERT and COPY commands. INSERT command is better if you want to add a single row. COPY command leverages parallel processing, which makes it ideal for loading large volumes of data.
You can send data to Redshift through the COPY command in the following way. However, before doing so, there are a series of steps that you need to follow:
- If you already have a cluster available, download files to your computer.
- Create a bucket on Amazon S3 and then load data in it.
- Create tables.
- Run the COPY command.

Amazon Redshift COPY Command
The picture above shows a basic command. You have to give a table name, column list, data source, and credentials. The table name in the command is your target table. The column list specifies the columns that Redshift is going to map data onto. This is an optional parameter. Data source is the location of your source; this is a mandatory field. You also have to specify security credentials, data format, and conversion commands. The COPY command allows only some conversions such as EXPLICIT_IDS, FILLRECORD, NULL AS, TIME FORMAT, etc.
However, several limitations are associated with moving data from Amazon S3 to Redshift through this process. The COPY command is best for bulk insert. If you want to upload data one by one, this is not the best option.
The second limitation of this approach is that it doesn’t let you apply any transformations to the data sets. You have to be mindful of the data type conversions that happen in the background with the COPY command.
The COPY command also restricts the type of data sources that you can transfer. You can only transfer JSON, AVRO, and CSV.
Move Data from Amazon S3 to Redshift with AWS Glue
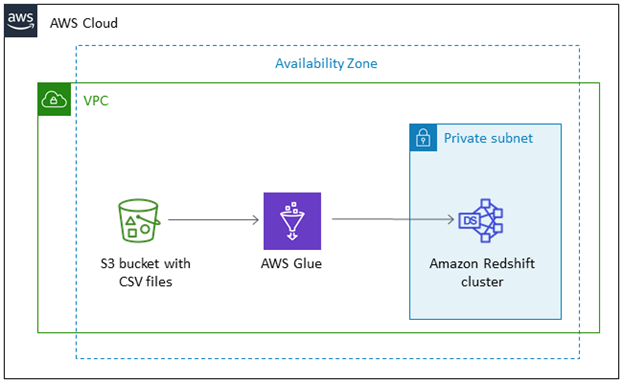
ETL Data with AWS Glue
AWS Glue is a server ETL tool introduced by Amazon Web Services to move data between Amazon services. You can use AWS Glue to shift data to and from AWS Redshift. The ETL tool uses COPY and UNLOAD commands to achieve maximum throughput. AWS Glue uses Amazon S3 as a staging stage before uploading it to Redshift.
While using AWS Glue, you need to keep in mind one thing. AWS Glue passes on temporary security credentials when you create a job. These credentials expire after an hour and stop your jobs mid-way. To address this issue, you need to create a separate IAM role that can be associated with the Redshift cluster.
You can transfer data with AWS Glue in the following way:
- Launch the AWS Redshift Cluster.
- Create a database user for migration.
- Create an IAM role and give it access to S3
- Attach the IAM role to the database target.
- Add a new database in AWS glue.
- Add new tables in the AWS Glue database.
- Give Amazon s3 source location and table column details.
- Create a job in AWS Glue.
- Specify the IAM role and Amazon S3 as data sources in parameters.
- Choose ‘create tables in your data target’ option and choose JDBC for datastore.
- Run AWS Glue job.
While AWS Glue can do the job for you, you need to keep in mind the limitations associated with it. AWS Glue is not a full-fledged ETL tool. Plus, you have to write transformations in Python or Scala. AWS Glue also does not allow you to test transformations without running them on real data. AWS Glue only supports JSBC connections and S3 (CSV).
Move Data from Amazon S3 to Redshift with AWS Data Pipeline
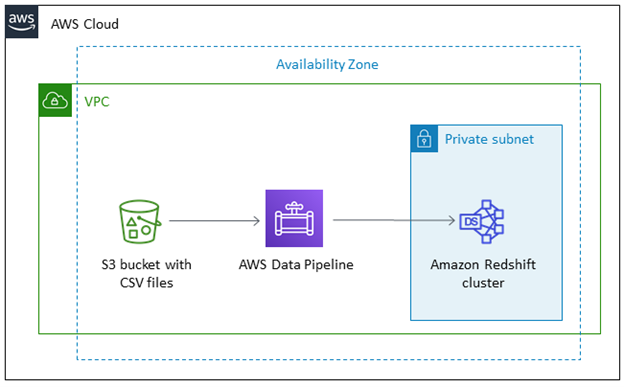
Send data to Amazon Redshift with AWS Data Pipeline
AWS Data Pipeline is a purpose-built Amazon service that you can use to transfer data between other Amazon sources as well as on-prem sources. With Data Pipeline, you can create highly reliable and fault-tolerant data pipelines.
The process contains data nodes where your data is stored, the activities, EMR jobs or SQL queries, and a schedule when you want to run the process. So, for example, if you want to send data from Amazon S3 to Redshift you need to:
- Define a pipeline with S3DataNode,
- A Hive Activity to convert your data into .csv,
- RedshiftCopyActivity to copy your data from S3 to Redshift.
Here is how you can create a data pipeline:
- Create a Pipeline. It uses Copy to Redshift template in the AWS Data Pipeline console.
- Save and validate your data pipeline. You can save it at any time during the process. The tool gives you warnings if there are any issues in your workload.
- Activate your pipeline and then monitor.
- You can delete your pipeline once the transfer is complete.
Move Data from Amazon S3 to Redshift with Astera Centerprise
Astera Centerprise gives you an easier way to sending data from Amazon S3 to Redshift. The code-free tool comes with native connectivity to popular databases and file formats. It lets you send data from any source to any destination without writing a single line of code. With Astera Centerprise, all you need to do is drag and drop the connectors in the data pipeline designer and you can start building data pipelines in no time. The platform also comes with visual data mapping and an intuitive user interface that gives you complete visibility into your data pipelines.
Using Amazon S3 as a Staging area for Amazon Redshift
If you are using Amazon S3 as a staging area to build your data warehouse in Amazon Redshift, then Astera Centerprise gives you a hassle-free way to send data in bulk. Here is how you can do that:
- Drag and drop the Database destination in the data pipeline designer and choose Amazon Redshift from the drop-down menu and then give your credentials to connect. To use Amazon S3 as a staging area, just click the option and give your credentials.
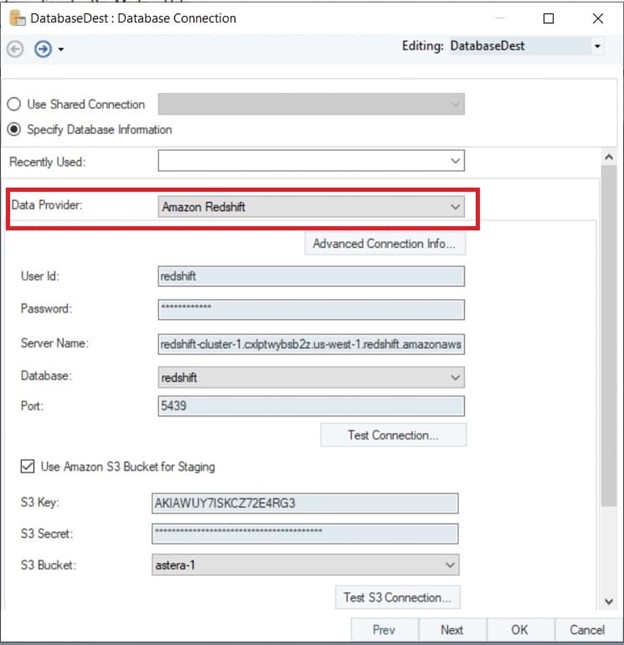
Connecting to Amazon Redshift in Astera Centerprise
- Once you have done that, you can also choose the size of the bulk insert. For example, if you have an Excel with one million records, you can send it to Amazon Redshift in batches of 10,000.
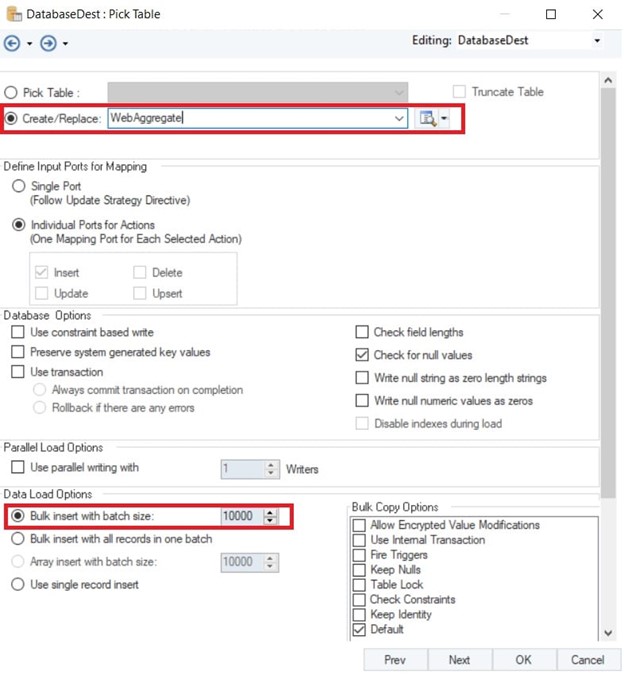
Selecting batch size for bulk insert in Amazon S3
Enrich Your Data before Sending it from Amazon S3 to Redshift
Unlike the COPY command, Astera Centerprise allows you to massage your data before sending it to Amazon Redshift, ensuring robust data quality management. Astera Centerprise comes with built-in sophisticated transformations that let you handle data any way you want. Whether you want to sort your data, filter it or apply data quality rules, you can do it with the extensive library of transformations.
What Makes Astera Centerprise the Right Choice?
While there are other alternatives including AWS tools that let you send data from Amazon S3 to Redshift, Astera Centerprise offers you the fastest and the easiest way for transfer. The code-free data integration tool is:
- Easy to use: It comes with a minimal learning curve, which allows even first-time users to start building data pipelines within minutes
- Automated: With its job scheduling features, you can automate entire workflows based on time or event-based triggers.
- Data quality: The tool comes with Several out-of-the-box options to clean, validate, and profile your data ensuring only qualified data makes it to the destination. You can use the custom expression builder to define your own rules as well.
Want to load data from Amazon S3 to Redshift? Get started with Astera Centerprise today!