
The Automated, No-Code Data Stack
Learn how Astera Data Stack can simplify and streamline your enterprise’s data management.

What is ETL (Extract, Transform, Load)?
What Is ETL?
Extract, Transform, and Load (ETL) is a process to integrate data into a data warehouse. It provides a reliable single source of truth (SSOT) necessary for business intelligence (BI) and various other needs, such as storage, data analytics, and machine learning (ML).
With reliable data, you can make strategic decisions more confidently, whether it’s optimizing supply chains, tailoring marketing efforts, or enhancing customer experiences.
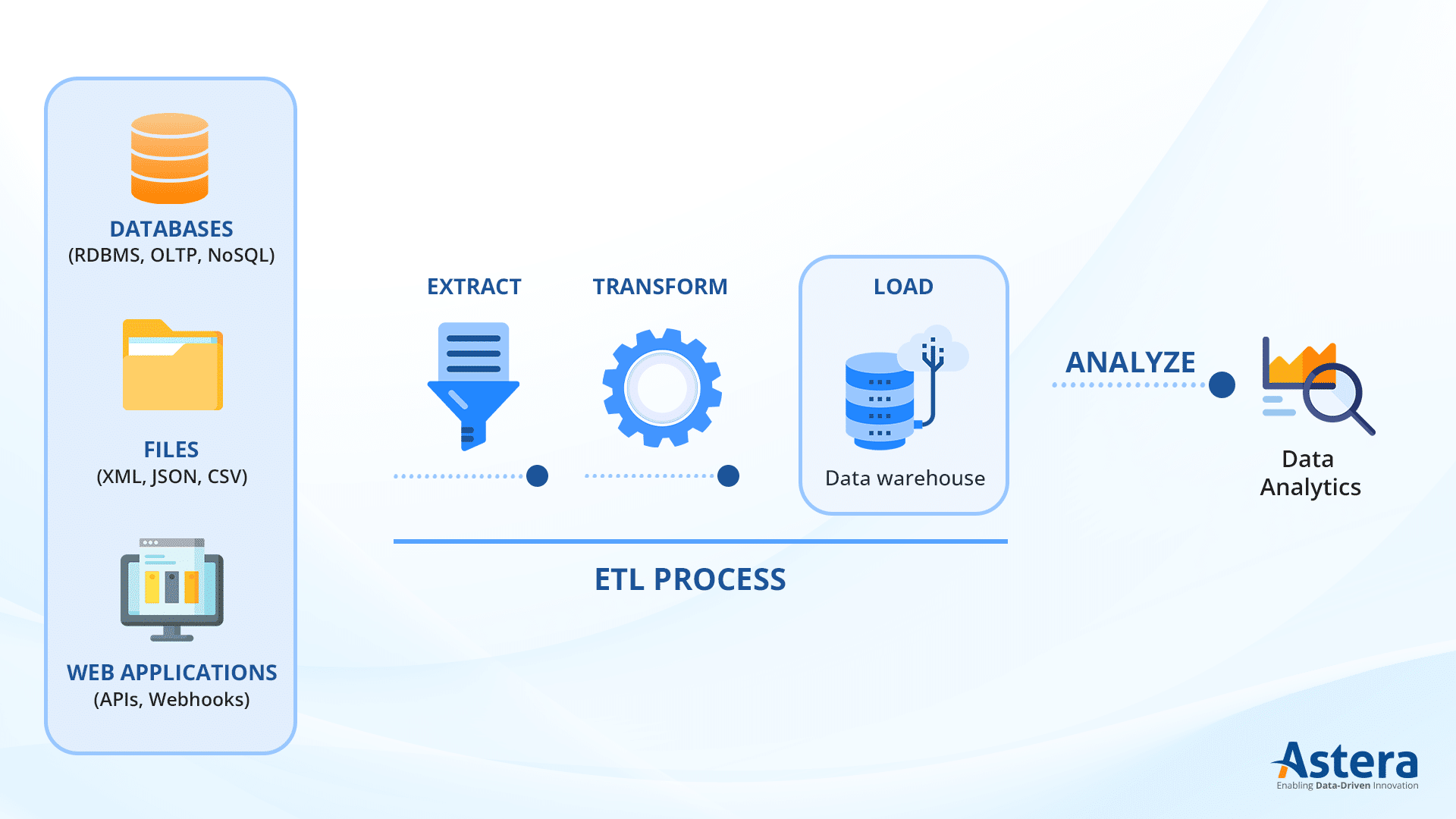
The ETL Process
The Evolution of ETL
Traditional ETL was primarily designed for batch processing and involved manual processes: data extraction, transformation, and loading being time-consuming and resource-intensive tasks. However, the explosion of real-time data generated by IoT devices, social media platforms, and other sources necessitated a shift towards handling continuous streams of data.
The rise of big data technologies and the emergence of Hadoop, Spark, and NoSQL databases have also had a profound impact on ETL practices, which have evolved to handle large volumes of data distributed across clusters. The advent of modern ETL tools—now powered by automation and AI—means greater efficiency and scalability for data integration processes. Sophisticated features for orchestrating, scheduling, monitoring, and managing workflows have become indispensable for organizations as they significantly reduce the need for manual intervention.
In addition to technological advancements, ETL processes have also evolved to address the growing importance of data quality and data governance. Organizations now prioritize ensuring data accuracy and compliance throughout the ETL pipeline.
Why Is ETL important?
Organizations store and use large amounts of structured and unstructured data to successfully run day-to-day operations. This data comes from multiple sources, and in different formats. For example, customer and marketing data from different channels and CRMs, partner and supply chain data from vendor systems, financial reporting and HR data from internal systems, and so on. The problem is further exacerbated by the fact that these data sets are often isolated, which makes accurate data analysis and effective decision-making a distant reality.
ETL enables you to extract data from all these sources, transform it so that every data set conforms to the requirements of the destination system, and load it into a repository where it is easily accessible for analysis. The importance of ETL lies not only in the sheer volume of data that it handles but also in the precision and efficiency with which it manages that data.
ETL Benefits
Unified View: Integrating data from disparate sources breaks down data silos and provides you with a unified view of your operations and customers. This holistic picture is critical for informed decision-making.
Enhanced Analytics: The transformation stage converts raw, unstructured data into structured, analyzable formats. The data readiness achieved empowers data professionals and business users to perform advanced analytics, generating actionable insights and driving strategic initiatives that fuel business growth and innovation.
Historical Analysis: You can store historical data, which is invaluable for trend analysis, identifying patterns, and making long-term strategic decisions. It allows you to learn from past experiences and adapt proactively. Tig
Operational Efficiency: ETL automation reduces manual effort and lowers operational costs. This newfound efficiency ensures that valuable human resources are allocated to more value-added tasks.
Data Quality: ETL facilitates data quality management, crucial for maintaining a high level of data integrity, which, in turn, is foundational for successful analytics and other data-driven initiatives.
How Does ETL Work?
Extract, transform, and load (ETL) works by extracting data from various sources, transforming it to suit the requirements of the destination system, and loading it into a data warehouse. ETL is a three-step process:
Data Extraction
The process starts by extracting raw data from relevant data sources, including databases, files, etc. The extracted data is stored in a landing zone, also called a staging area. A staging area is an intermediate storage where data is only stored temporarily. There are three common ways to extract data in ETL:
Incremental Extraction
Only new or changed data since the last extraction is pulled in this method. This approach is common when dealing with large data sets as it reduces the amount of data transferred. For instance, you might extract only the new customer records added since the last time you extracted data.
Full Extraction
This extracts all data from the source system in one go. For example, a full extraction would mean pulling all customer records if you’re extracting data from your customer database.
Update Notification
It focuses on monitoring changes in data and notifying relevant parties or systems about those changes before data extraction. You can use this method when you need to keep stakeholders informed about updates or events related to a data set.
Data Transformation
Data transformation is the second stage in the process of ETL. Data stored in the staging area is transformed to meet business requirements since the extracted data lacks standardization. The degree to which the data is transformed depends on factors such as data sources, data types, etc.
Any improvements to data quality are also finalized here. Data teams typically rely on the following data transformations to maintain data integrity during ETL:
Data Cleansing
It includes identifying and correcting errors or inconsistencies in data sets to ensure data accuracy and reliability. For example, in a customer database, data cleaning could involve removing records with missing email addresses, correcting typographical errors in customer names, etc.
Data Deduplication
Deduplication identifies and removes duplicate or redundant records within a data set. The process involves comparing data records based on specific criteria, such as unique identifiers or key attributes, and removing duplicate entries while retaining one representative record. It helps in reducing data storage requirements and improving data accuracy.
Joins and Tree Joins
Joins are operations in database management and data processing that combine data from two or more tables based on related columns. It allows you to retrieve and analyze data from multiple sources in a unified manner.
Tree joins are used in hierarchical data structures, such as organizational charts, to connect parent and child nodes. For instance, in a hierarchical employee database, a tree join would link employees to their respective supervisors, creating a hierarchy that reflects the organizational structure.
Normalization and De-normalization
Normalization involves organizing a database schema to minimize data redundancy and improve data integrity. You can achieve this by breaking down tables into smaller, related tables and defining relationships between them.
On the other hand, de-normalization involves intentionally introducing redundancy into a database schema to optimize query performance. This might entail merging tables, duplicating data, or using other techniques that make data retrieval faster at the expense of some data redundancy.
Merge
Merge transformation is commonly used in ETL to consolidate information from various sources. It is a data transformation operation that combines data from two or more data sets or sources into a single data set by aligning records based on common attributes or keys.
Data Loading
Loading data into the target system is the last step in the ETL process. The transformed data is moved from the staging area into a permanent storage system, such as a data warehouse.
The loaded data is well-structured, which data professionals and business users can use for their BI and analytics needs. Depending on your organization’s requirements, you can load data in a variety of ways. These include:
Full Load
As the name suggests, the entire data from the source systems is loaded into the data warehouse without considering incremental changes or updates. Full loads are often used when initially populating a data warehouse or starting a new data integration process. In such cases, you need to bring all the historical data from the source into the target system to establish a baseline.
It’s important to note that while a full load is suitable for initial data setup, it’s not practical for continuous, real-time, or frequent data updates. In such cases, incremental loading or other strategies should be employed to optimize resource utilization.
Batch Load
Batch loading in ETL refers to the practice of processing and loading data in discrete, predefined sets or batches. Each batch is processed and loaded sequentially. Batches are typically scheduled to run at specific intervals, such as nightly, weekly, or monthly.
Bulk Load
A bulk load refers to a data loading method that involves transferring a large volume of data in a single batch operation. It is not specific to whether all data is loaded or only a subset. Instead, bulk loading can be employed in various scenarios, including both full and incremental load. Think of it as a loading method to optimize the speed and efficiency of data transfer.
Incremental Load
Incremental load only loads the new or changed data since the last ETL run. It’s used in situations where it is necessary to minimize the data transfer and processing overhead when dealing with frequently changing data sets.
Streaming
In this case, data is loaded in near real-time or real-time as it becomes available. It is often used for streaming data sources and is ideal for applications requiring up-to-the-minute data for analytics or decision-making. Streaming user activity data into a real-time analytics dashboard is a common example.
ETL vs. ELT
Extract, transform, and load (ETL) and extract, load, and transform (ELT) are two of the most common approaches used to move and prepare data for analysis and reporting. So, how do they differ? The basic difference is in the sequence of the process. In ELT, data transformation occurs only after loading raw data directly into the target storage instead of a staging area. However, in ETL, you must transform your data before you can load it.
The table below summarizes ETL vs. ELT:
| ETL (extract, transform, load) | ELT (extract, load, transform) | |
|---|---|---|
| Sequence | Extracts data from the source first, then transforms it before finally loading it into the target system. | Extracts data from the source and loads it directly into the target system before transforming it. |
| Data Transformation | Data transformation occurs outside the destination system. | Data transformation occurs within the destination system. |
| Performance | Likely to have performance issues when dealing with large data sets. | Can benefit from parallelization during loading due to modern distributed processing frameworks. |
| Storage | Requires an intermediate storage location for staging and transforming data, called staging area. | May use direct storage in the destination data store. |
| Complexity | Typically involves complex transformation logic in ETL tools and a dedicated server. | Simplifies data movement and focuses on data transformation inside the destination. |
| Scalability | Requires additional resources for processing large data volumes. | Can scale horizontally and leverage cloud-based resources. |
| Examples | Traditional scenarios like data warehousing. | Modern data analytics platforms and cloud-based data lakes. |
What Is an ETL Pipeline?
ETL pipeline is the means through which an organization carries out the data extraction, transformation, and loading processes. It’s a combination of interconnected processes that execute the ETL workflow, facilitating data movement from source systems to the target system.
These pipelines ensure that the data aligns with predefined business rules and quality standards. You can automate your pipelines and accelerate the process using data integration tools to further your data-driven initiatives.
Data Pipeline vs. ETL Pipeline
At the most basic level, a data pipeline is a set of automated workflows that enable data movement from one system to another. Compared to ETL pipelines, data pipelines may or may not involve any data transformations. In this context, an ETL pipeline is a type of data pipeline that moves data by extracting it from one or more source systems, transforming it, and loading it into a target system.
Read more about the differences between data pipeline vs. ETL pipeline.
What is Reverse ETL?
Reverse ETL is a relatively new concept in the field of data engineering and analytics. It involves moving data from a data warehouse, data lake, or other analytical storage systems back into operational systems, applications, or databases that are used for day-to-day business operations. So, the data flows in the opposite direction.
While traditional ETL processes focus on extracting data from source systems, transforming it, and loading it into a data warehouse or other destinations for analysis, reverse ETL is geared towards operational use cases, where the goal is to drive actions, personalize customer experiences, or automate business processes.
This shift in data movement is designed to empower non-technical users, such as marketing teams or customer support, with access to enriched, up-to-date data to fuel real-time decision-making and actions.
Looking for the best ETL Tool? Here's what you need to know
With so many ETL Pipeline Tools to choose from, selecting the right solution can be overwhelming. Here's a list of the best ETL Pipeline Tools based on key criteria to help you make an informed decision.
Learn More
ETL Challenges to Be Aware Of
Data Quality and Consistency: ETL heavily depends on the quality of input data. Inconsistent, incomplete, or inaccurate data can lead to challenges during transformation and may result in flawed insights. Ensuring data quality and consistency across diverse sources can be a persistent challenge.
Scalability Issues: As data volumes grow, you may face scalability challenges. Ensuring that the infrastructure can handle increasing amounts of data while maintaining performance levels is a common concern, especially for rapidly growing businesses.
Complexity of Transformations: Complex business requirements often necessitate intricate data transformations. Designing and implementing these transformations can be challenging, especially when dealing with diverse data formats, structures, business rules, or using SQL to ETL data.
Data Security and Compliance: Handling sensitive information while moving data raises concerns about data security and compliance. Ensuring that data is handled and transferred securely poses a continuous challenge.
Real-time Data Integration: The demand for real-time analytics has grown, but achieving real-time data integration via ETL can be challenging. Ensuring that data is up-to-date and available for analysis in real-time requires sophisticated ETL solutions and can be resource intensive.
How Do ETL Tools Help?
Extract, transform, and load (ETL) tools help businesses organize and make sense of their data. They streamline data collection from various sources, transforming it into a more digestible and actionable format.
Here’s how you can benefit from ETL tools:
ETL Automation
ETL tools streamline ETL workflows by automatically extracting data from various sources, transforming it to your desired format, and loading it into a central data repository. This process operates autonomously and reduces the need for manual processes, such as coding for ETL (SQL for data extraction and transformation). You can efficiently handle vast data volumes without the expenditure of excessive time and human resources, leading to increased operational efficiency and cost savings for your organization.
Single Source of Truth (SSOT)
In the contemporary business landscape, data often resides in multiple systems and formats, leading to inconsistencies and discrepancies. ETL tools bridge these divides, harmonizing data into a unified format and location. This SSOT serves as a reliable foundation for decision-making, ensuring that all stakeholders access consistent and accurate information.
Real-Time Data Access
In the age of instant gratification and rapid decision-making, businesses require access to up-to-the-minute data insights to remain competitive. Modern ETL tools offer the capacity to integrate real-time data streams, enabling you to respond promptly to changing circumstances and trends. This real-time data access equips your business with a competitive edge, as you can make agile decisions based on the most current information available.
Better Compliance
Businesses today operate in a heavily regulated environment, necessitating compliance with regulations such as HIPAA and GDPR. Modern ETL tools offer features such as data lineage tracking and audit trails, which are critical for demonstrating adherence to data privacy, security, and other compliance mandates. This capability mitigates legal and reputational risks, safeguarding your organization’s standing in the market.
Better Productivity
These tools liberate human resources to focus on higher-value tasks by automating labor-intensive data integration and transformation processes. Employees can direct their efforts toward data analysis, interpretation, and strategy formulation rather than spending excessive hours on manual data wrangling or using SQL to ETL data. This shift in focus amplifies productivity, fosters innovation, and drives business growth.
ETL Best Practices to Know
Optimize company-wide data management processes by incorporating the following ETL best practices into your data warehouse strategy:
Understand Your Data Sources
Begin by identifying all the data sources that you need to extract data from. These sources can include databases, files, APIs, web services, and more. You should also understand the individual source’s structure, location, access methods, and any relevant metadata.
Prioritize Data Quality
Data profiling provides insights into the data’s characteristics and enables you to identify issues that might impact its reliability and usability. By identifying anomalies early in the process, you can address these issues before they propagate into downstream systems, ensuring data accuracy and reliability.
Use Error Logging
Establish a uniform logging format with details like timestamps, error codes, messages, impacted data, and the specific ETL step involved. Additionally, categorize errors with severity levels, for example, INFO for informational messages, WARNING for non-fatal issues, and ERROR for critical problems, to enable prioritization and efficient troubleshooting. This systematic error-logging practice empowers data professionals to swiftly identify and resolve issues that may arise during the process.
Use Incremental Loading for Efficiency
Use change data capture (CDC) for incremental loading if you want to update only the new or changed data. It reduces processing time and resource consumption. For example, a financial services company can significantly optimize the performance of its ETL pipelines by using the incremental loading technique to process the daily transactions’ data.
Use ETL Tools to Automate the Process
Use automated ETL tools to build your ETL pipeline and streamline company-wide data integration. Automated workflows follow predefined rules and minimize the risk of errors that are otherwise highly likely with manual processing. Leveraging tools that offer automation features can do wonders for your business as they offer a visual interface for designing workflows and scheduling ETL jobs.
ETL Use Cases
Here are some ETL use cases that are applicable to most organizations:
Data Warehousing
ETL is one of the most widely used methods for collecting data from various sources, making it clean and consistent, and loading it into a central data warehouse. It enables you to generate reports and make informed decisions. For instance, retail companies can combine sales data from stores and online sales platforms to gain insights into customer buying patterns and optimize their inventory accordingly.
Legacy System Modernization
In the context of legacy system migration and modernization, ETL can help your business transition from outdated systems to modern platforms. It can extract data from legacy databases, convert it to a format compatible with contemporary systems, and seamlessly integrate it.
This use case is crucial for sectors such as healthcare, where patient records must be migrated to modern electronic health record systems while preserving data accuracy and accessibility.
Real-Time Data Integration
Real-time data integration is another key application, especially beneficial if your business needs to respond instantly to changing data streams. You can optimize ETL to continuously extract, transform, and load data as it’s generated. For online retailers, this could mean leveraging real-time customer behavior data to personalize product recommendations and pricing strategies in the ever-changing e-commerce landscape.
Cloud Migration
ETL is indispensable when it comes to data migration and transitioning to cloud environments. It extracts data from on-premises systems, adapt it for compatibility with cloud platforms, and load it seamlessly into the cloud. Startups and enterprises alike benefit from it in their quest for rapid scaling, taking full advantage of cloud resources without compromising data consistency or availability.
Improving Data Quality
Businesses leverage ETL to enhance their data quality management efforts. You can utilize several techniques, such as data profiling, validation rules, and data cleansing, to detect and rectify anomalies in data sets. By ensuring data integrity at the extraction, transformation, and loading stages, you make decisions based on reliable and error-free data. This not only minimizes costly errors and operational risks but also cultivates trust in the data, enabling informed and precise decision-making across various business functions.
Astera—the Automated ETL Solution for All Businesses
Astera is an end-to-end data management solution powered by artificial intelligence (AI) and automation. From data extraction to transformation to loading, every step is a matter of drag-and-drop with Astera’s intuitive, visual UI.
Astera empowers you to:
- Connect to a range of data sources and destinations with built-in connectors
- Extract data from multiple sources, whether structured or unstructured
- Transform data according to business requirements with pre-built transformations
- Load healthy data into your data warehouse using embedded data quality features
- Build fully automated ETL pipelines without writing a single line of code
Want to learn more about our 100% no-code ETL platform? Sign up for a demo or contact us.



