
The Automated, No-Code Data Stack
Learn how Astera Data Stack can simplify and streamline your enterprise’s data management.

Building a Data Warehouse: A Step-By-Step Guide
Building a data warehouse was long viewed as a complex procedure requiring significant expertise in diverse, yet related, areas within data management. From database management to building data models to implementing ETL processes, building a data warehouse would easily take months. However, advancements in technology have led to the availability of more and more tools and platforms that provide approachable and streamlined solutions to users of all kinds.
In this article, we are going to learn all about building a data warehouse. Specifically, the prerequisites of building a data warehouse, including a step-by-step guide, and the best practices.
Prerequisites for Building a Data Warehouse
The prerequisites of building a data warehouse can vary vastly, depending on your business requirements. Typically, though, you would need to consider the following criteria before you start building your data warehouse:
Planning for the Data Warehouse Blueprint
This is the foundational phase where you lay the groundwork for your data warehouse. The blueprint sets the direction for the project and is critical to ensuring that the final product is closely aligned with the needs and objectives of your business. Additionally, your strategic plan should also guide the scope and design of your data warehouse.
Cut Down Data Warehouse Development Time by up to 80%
Traditional data warehouse development requires significant investment in terms of time and resources. However, with Astera DW Builder, you can reduce the entire data warehouse design and development lifecycle by up to 80%. Learn more in this whitepaper.
Download Whitepaper
Start by developing clear business objectives. It’s essential to involve business leaders, end-users, IT staff, and other stakeholders early on as this is where you need to answer questions like: why do you need to build a data warehouse? Will it cover the entire organization or focus on specific departments or business functions? Which business processes will it support? How will it add value? Securing stakeholder buy-in and defining these objectives will influence all subsequent decisions—their support will ensure the project receives the necessary attention and resources.
A data warehousing strategy outlines how your organization collects, stores, manages, and uses the data. So, as part of this phase, you also need to establish data governance policies specific to your business. These policies define who is responsible for various data-related decisions and processes, how data quality is ensured, and how to handle data security and privacy concerns.
Assembling a Skilled Team
Building a data warehouse is a complex task that requires a diverse team of professionals. This step ensures that your project is well-equipped with the necessary talent to build, deploy, and maintain a data warehouse that serves your analytical needs.
While the team’s success largely depends on its members, it should collectively possess a mix of technical skills. You would typically need people with expertise in SQL, ETL processes, and data modeling, as well as someone with project management capabilities and a strong understanding of the business domain. In short, your team should ideally comprise of:
- data architects for designing the system
- data engineers to build and maintain it
- business analysts to ensure it meets user needs
- database administrators to manage data storage
- project managers to keep everything on track
Securing Essential Resources
Apart from a team of professionals, you will also need to budget for the initial setup and implementation and ongoing operations and maintenance of your data warehouse. This includes the infrastructure to host your data warehouse, the right tools to manage and process your data, and security measures to protect it.
The initial setup and implementation are typically the most resource-intensive phases, requiring investments in:
- hardware or cloud services
- software licenses
- and professional services for design and development
It is also important that you consider the costs associated with data integration and the potential need for custom development to ensure that you can account for all your data sources. Alternatively, you can opt for a no-code data integration tool that comes with built-in connectors for various sources and destinations.
Establishing a Technical Framework
Next in line is a comprehensive assessment plan that ensures technical and data readiness. The objective is to assess the performance and scalability of current systems and highlight their strengths and weaknesses, along with identifying opportunities for enhancements. Conduct an in-depth analysis of the current data infrastructure by evaluating the existing hardware, network configurations, and any cloud services.
The exercise involves cataloging all the data sources available to your organization, for example, internal systems like CRM and ERP, external data from partners, and streaming data sources such as IoT devices. Identifying data sources enables you to map out the data landscape and understand the nature and business relevance of each data source.
Acquiring the necessary technical components is also a key step in this preliminary phase of building a data warehouse. It includes selecting the tools and platforms that assist in implementing your organization’s data strategy. For ETL tools, consider factors such as the data sources, data transformation needs, integration with other systems, etc.
Similarly, determine the most suitable data storage options, considering the required capacity and access speed. Identify if there’s a need for a mix of on-premises, cloud-based, or hybrid storage solutions. Equip your data team with sophisticated data modeling tools that enable the construction of a solid data warehouse architecture.
Build a Custom Data Warehouse Within Days—Not Months
Building a data warehouse no longer requires coding. With Astera Data Warehouse Builder you can design a data warehouse and deploy it to the cloud without writing a single line of code.
Learn More
Building a Data Warehouse: Automating the Execution Phase
Once you have the prerequisites in order, the next step is to implement the plan and build your data warehouse.
Automated data warehouse building tools, such as Astera Data Warehouse Builder, cut down numerous standard and repetitive tasks involved in the data warehousing lifecycle to just a few simple steps.
Astera Data Warehouse Builder is an end-to-end platform that simplifies and accelerates the process of building a data warehouse. Its drag-and-drop interface enables you to design your data models and ETL processes without writing a single line of code. The built-in connectors allow for easy integration with a range of sources and destination systems, whether on-premises or in the cloud. Astera’s embedded data quality features ensure that only healthy data makes its way into your data warehouse for accurate BI, analytics, and reporting.
Let’s take a use case to illustrate the process of building a data warehouse using Astera’s no-code data warehouse builder.
The Use Case:
Shop-Stop is a fictitious online retail store that maintains its sales data in a SQL database. The company has recently decided to implement a data warehouse to gain a solid reporting architecture and improve BI and analytics. However, their IT team and technical experts argue that the capital and resources needed to execute and maintain the entire process can be reduced significantly using an automated data warehousing tool.
Shop-Stop decides to use Astera Data Warehouse Builder to design, build, deploy, and maintain their data warehouse. Let’s take a look at the how the process of building a data warehouse using Astera looks like.
Building a Data Warehouse Step 1: Creating a Source Data Model
The first step in building a data warehouse is to identify and model the source data. Once you add a new data model to the project, you can reverse engineer your database, in this case Shop-Stop’s sales database, to create a source data model using the Reverse Engineer icon on the data model toolbar with just a single click. Doing so creates the data model automatically. Each entity in this data model represents a table that contains Shop-Stop’s source data. Here’s how it looks like:
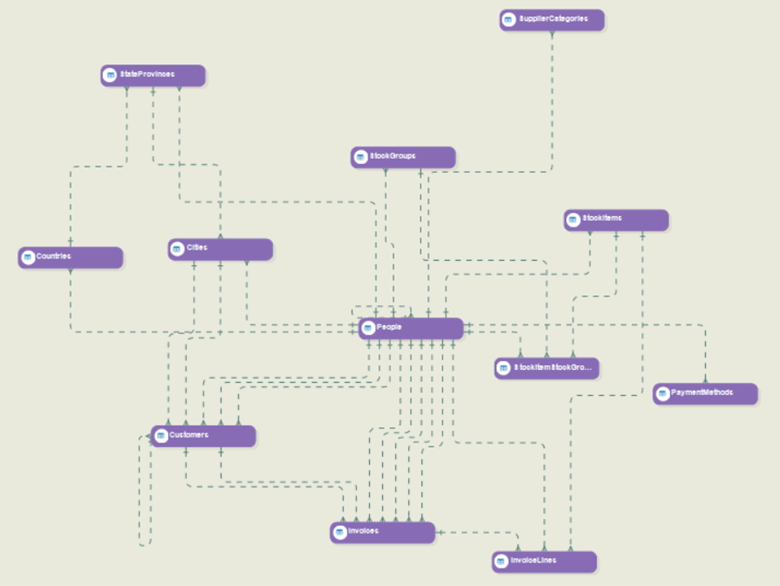
Once you have the data model, you can verify it to ensure that it’s free of errors and warnings. To do so, simply click on the Verify for Read and Write Deployment option in the main toolbar. Here’s a screenshot:

Upon verifying the model, you can deploy it to the server and make it available for use in ETL pipelines (as well as ELT) or for data analytics. Here’s how to do it. Now that you’ve created, verified, and deployed a source data model, let’s move on to the next step.
Building a Data Warehouse Step 2: Build and Deploy a Dimensional Model
The next step in the process is to design a dimensional model that will serve as the destination schema for Stop-Stop’s data warehouse. You can use the Entity object available in the data model toolbox, and the data modeler’s drag-and-drop interface to design a model from scratch.
Since Shop-Stop already has a data warehouse schema in a SQL database, you’ll have to reverse engineer the database. Again, each entity in the resulting data warehouse model represents a table in Shop-Stop’s final data warehouse.
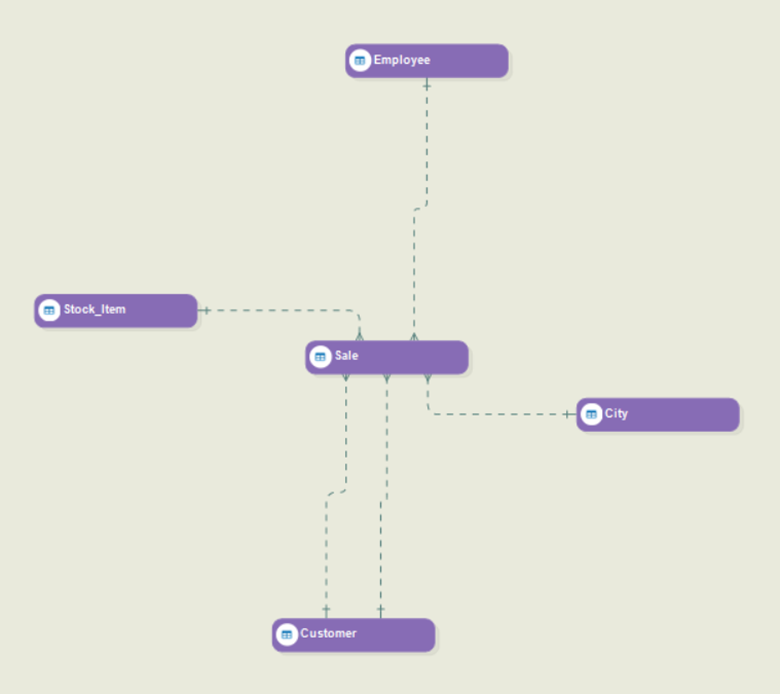
Next, you need to convert this model into a dimensional model by assigning facts and dimensions. The type for each entity is set as General by default when a database is reverse engineered. You can conveniently change the type to Fact or Dimension by right-clicking on the entity, hovering over Entity Type in the context menu, and selecting an appropriate type from the given options.
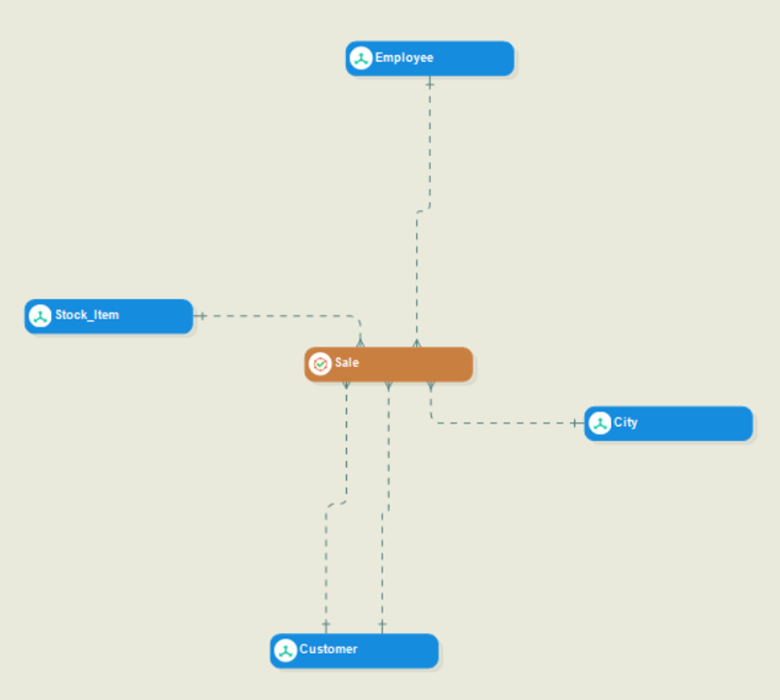
The Sale entity in the center is the fact entity, with the rest being dimension entities.
Once you have your facts and dimensions in place, you need to configure them for enhanced data storage and retrieval by assigning specified roles to the fields present in the layout of each entity.
For dimension entities, the Dimension Role column in the Layout Builder provides a comprehensive list of options. These include:
- Surrogate Key
- Business Key
- Slowly Changing Dimension types (SCD1, SCD2, SCD3, and SCD6)
- Record identifiers to keep track of historical data (Effective and Expiration dates, Current Record Designator, and Version Number)
- Placeholder Dimension to keep track of late and early arriving facts and dimensions
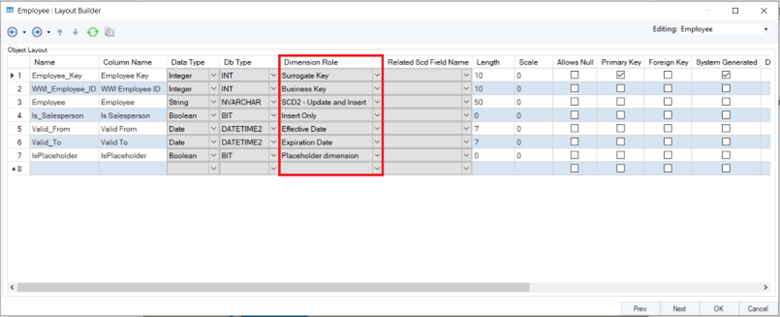
Similarly, the fact entity’s Layout Builder contains a Fact Role column that allows you to assign the Transaction Date Key role to one of the fields. Here is how the layout of the Sale entity will look like once you’ve assigned the Transaction Date Key role to a field:
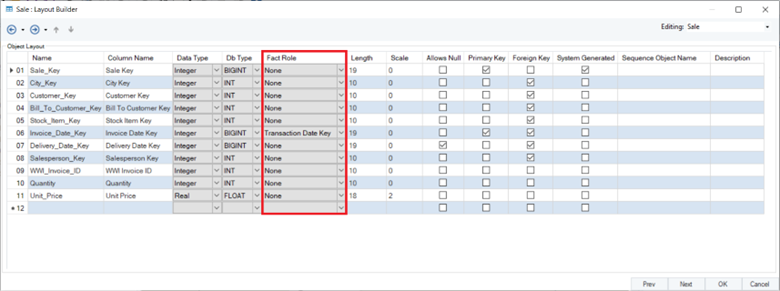
With your dimensional model ready, you can verify and deploy it for further usage.
Building a Data Warehouse Step 3: Populate the Data Warehouse
It’s now time to populate Shop-Stop’s data warehouse by loading relevant source data into the tables using ETL pipelines. Astera enables you to build ETL and ELT pipelines using its dataflow designer.
To do so, you’ll have to add a new dataflow to the data warehousing project. Use the extensive set of objects available in the dataflow toolbox to design the ETL process. Use the Fact Loader and Dimension Loader objects to load data into fact and dimension tables, respectively.
Here’s what the dataflow to load data into the Customer table looks like:
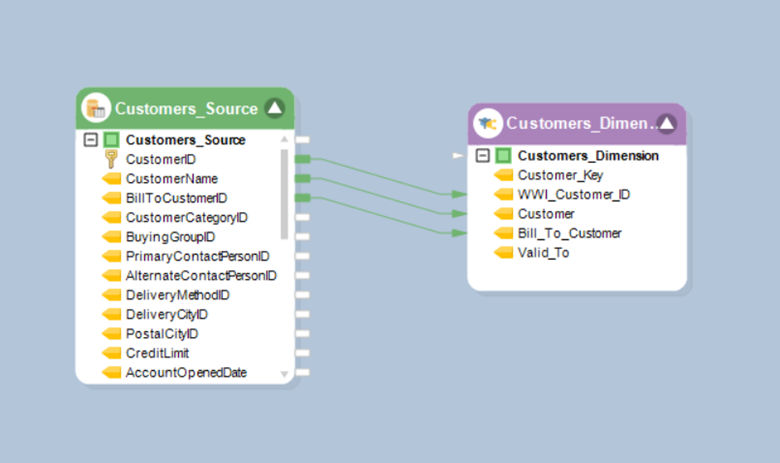
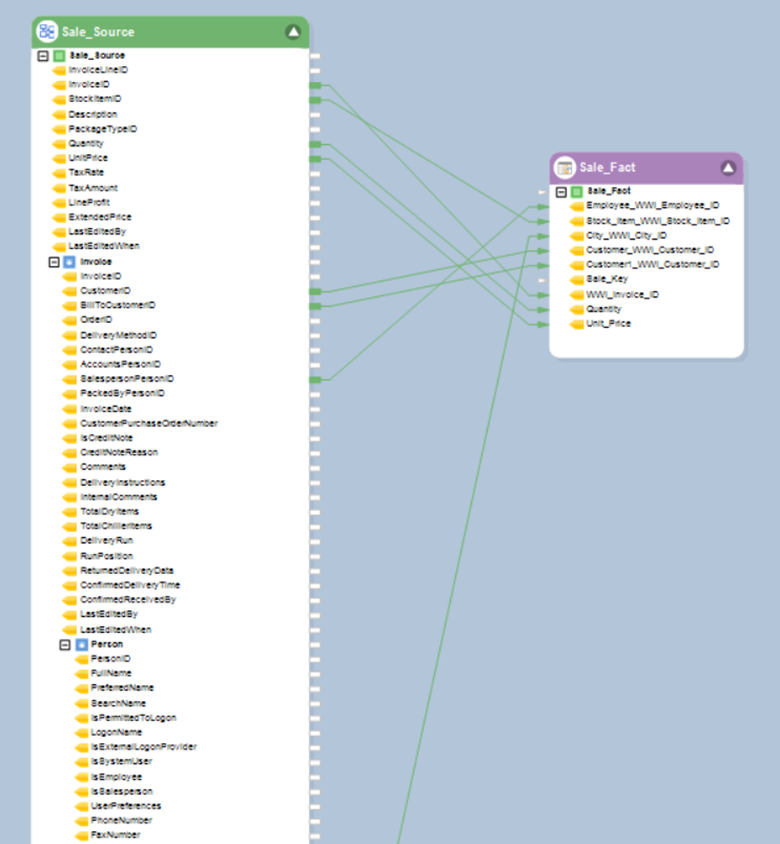
On the left is the Database Table Source object that fetches data from a table in the source table. On the right, the Dimension Loader object loads data into the relevant table in the destination dimensional model.
To connect each of these objects to their respective models, you will need to configure the source object with the source data model’s deployment:
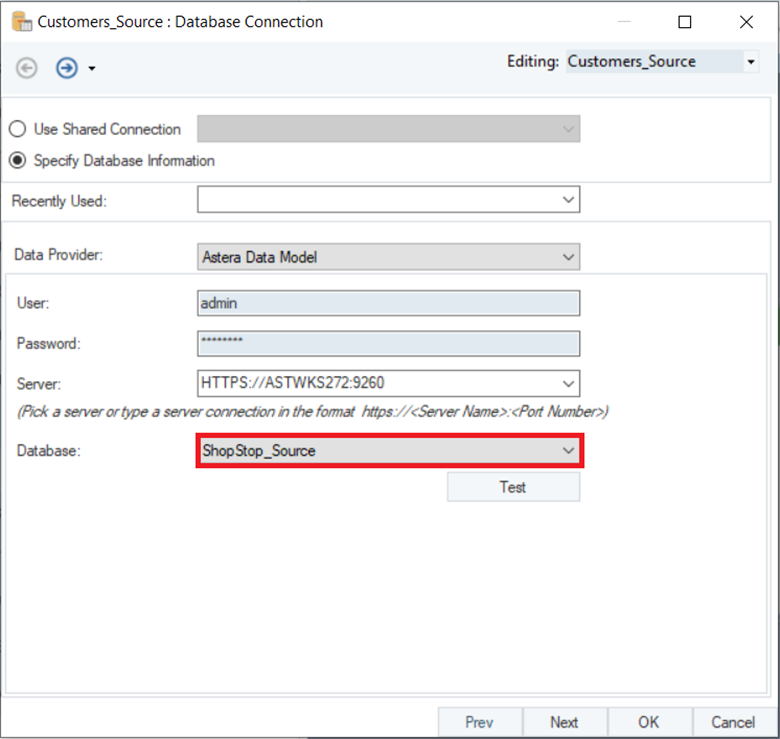
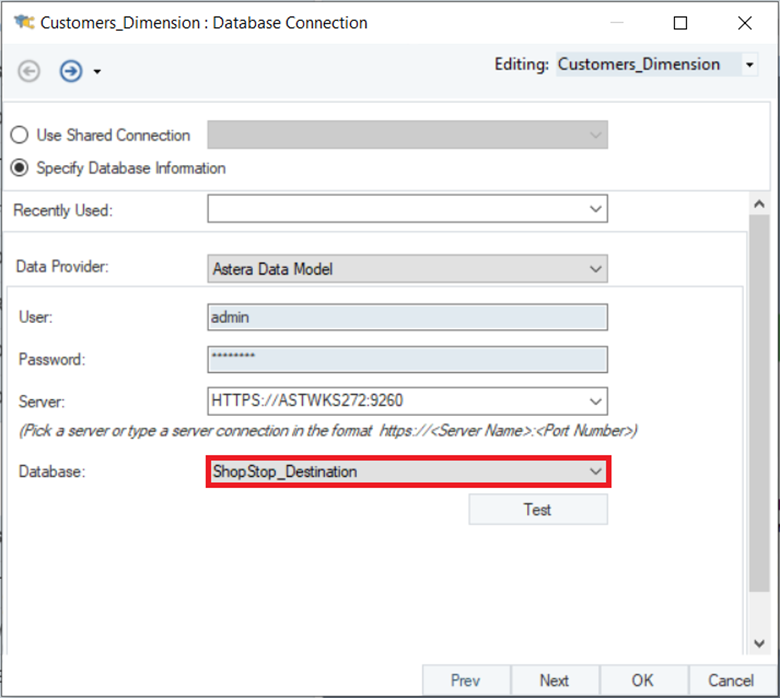
Similarly, configure the Dimensional Loader object with the destination dimensional model’s deployment, as shown in the image below:
Note that you’ll need to design the dataflow to load data into the fact table differently. This is because it contains fields from multiple source tables, but the Database Table Source object can only extract data from one source table at a time.
Instead, you can use the Data Model Query Source object, which allows you to extract multiple tables from the source model by selecting a root entity. This is shown in the screenshot below:
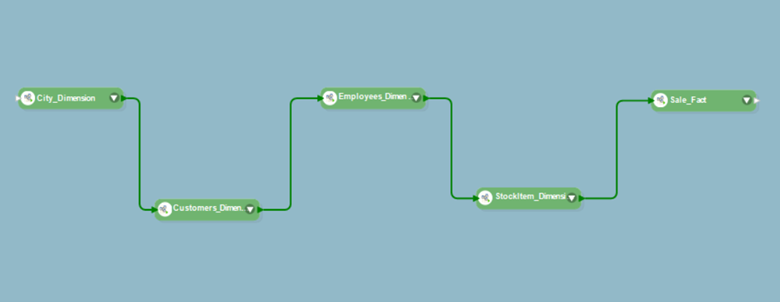
Now that you have designed all your dataflows, you can execute each of them to populate Shop-Stop’s data warehouse with their sales data. To avoid executing all of the dataflows individually, design a workflow to orchestrate the entire process.
Finally, automate the process of refreshing this data through the built-in Job Scheduler. To access the job scheduler, go to Server > Job Schedules in the main menu.
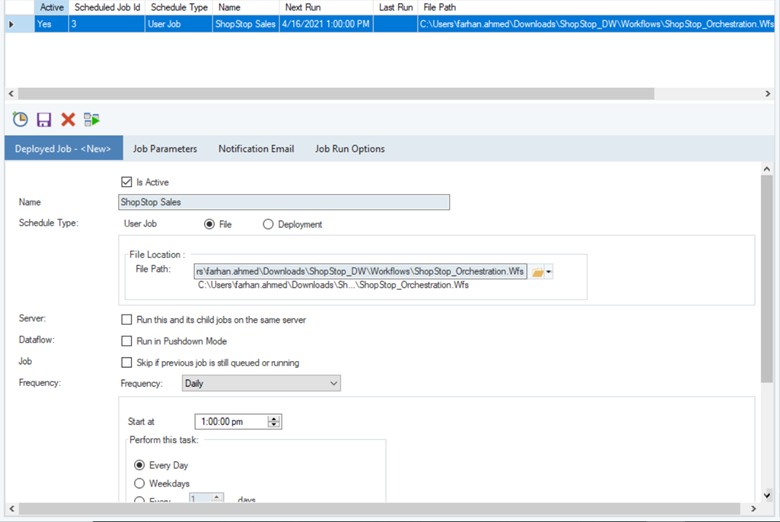
In the Scheduler tab, you can create a new schedule to automate the execution process at a given frequency.
Building a Data Warehouse Step 4: Visualize and Analyze
Once you have designed and deployed your data warehouse, you can integrate it with industry-leading visualization and analytics tools such as Power BI, Tableau, Domo, etc. through a built-in OData service.
Best Practices for Building a Data Warehouse
Building a data warehouse is one thing, doing it in a way that is efficient and delivers effective outcomes is an entirely different challenge—one that leverages the best practices.

Start with a Data Warehouse Strategy
Always start with a clear strategy that outlines the business objectives, the scope of your data, the architectural approach, and how your data warehouse will evolve over time. Your data warehouse strategy should align with the overall business strategy and address specific analytics and reporting needs.
Automate Everything You Can
While not much can be done to accelerate the initial planning phase, you can cut down time and resource requirements significantly when it comes to execution. Leverage tools such as data warehousing tools, data integration tools, etc. to automate and accelerate repetitive and laborious tasks.
Pay Attention to Data Quality
Your analytics and reporting will only be as good as the quality of the data you populate your data warehouse with. Ensure data quality management by implementing robust processes for data cleansing, de-duplication, and validation.
Adopt a Scalable Architecture
As data volumes grow and business needs change, your data warehouse should be able to adapt without requiring extensive redesigns. Using a modular architecture that allows for scalability and flexibility ensures that your data warehouse can integrate with newer technologies without a hefty investment.
Implement a Robust ETL Process
Design ETL pipelines that are robust enough to handle high-volume data in near real-time. Automate the ETL process as much as possible to minimize manual intervention and ensure data integrity.
Build Your Data Warehouse Effortlessly With a 100% No-Code Platform
Build a fully functional data warehouse within days. Deploy on premises or in the cloud. Leverage powerful ETL/ELT pipelines. Ensure data quality throughout. All without writing a single line of code.
Download Trial
Build your Data Warehouse with Astera
Building a data warehouse can easily become a resource-intensive and time-consuming process given the complexity of integrating and organizing large volumes of data from diverse sources—sources that continue to increase as your business grows. This is why modern organizations leverage automated data management solutions to fast-track the development of their data warehouses.
Are you on a tight timeline that requires you to build a data warehouse within days, not months? Contact one of our solutions experts at +1 888-77-ASTERA. Alternatively, you can download a 14-day free trial or view demo.



