Table des matières

L'automatisé, Pas de code Pile de données
Apprener comment Astera Data Stack peut simplifier et rationaliser la gestion des données de votre entreprise.

Ingrédients de l'architecture d'entrepôt de données axée sur les métadonnées
Le 25 septembre 2023
Avouons-le, la construction d'une architecture d'entrepôt de données qui répond à tous vos besoins nécessite beaucoup de planification et d'expertise. Une architecture d'entrepôt de données moderne doit intégrer avec précision les données du système opérationnel avec des conventions de mise en forme et de dénomination correctes, elle doit être suffisamment flexible pour s'adapter aux changements dans la structure de ces sources sous-jacentes et doit fournir des performances optimisées pour prendre en charge des rapports en temps opportun.
In Astera Constructeur DW (ADWB), un outil d'entrepôt de données, nous fournissons une solution sans code qui apporte évolutivité, rapidité et agilité au développement de l'entrepôt de données. À partir du concepteur de modèle de données unifié, vous pouvez accéder à une gamme de fonctionnalités approfondies qui vous font considérablement gagner du temps et des coûts liés à la conception, à la configuration et au déploiement de votre architecture BI. Voyons comment ces ingrédients d'une architecture d'entrepôt de données d'entreprise se combinent:
Contrôlez le développement de l'entrepôt de données de bout en bout

Développement de l'entrepôt de données
Avec le concepteur de modèle de données de l'entrepôt de données, ADWB fournit une interface unifiée dans laquelle les données du système source peuvent être importées, alignées sur le schéma de destination, dénormalisées et préparées pour la migration vers un modèle dimensionnel optimisé pour les rapports et les analyses. ADWB facilite ce processus d'intégration grâce à ses fonctions d'ingénierie inverse et d'ingénierie aval.
Créez des modèles de données DWH enrichis pour vos systèmes source
Notre fonction de reverse engineering prend un schéma de base de données source et le réplique sous la forme d'un modèle de relation entité-relation. Ce modèle montre la structure logique de la base de données sous-jacente et vous donne la possibilité d'enrichir ce schéma de plusieurs manières pour faciliter le chargement dans l'entrepôt de données.
ADWB propose des intégrations avec une gamme de bases de données de premier plan, notamment SQL Server et Oracle Database, ainsi que des fournisseurs de cloud tels qu'Amazon et Microsoft Azure. Vous pouvez également importer des modèles de données directement à partir d'un logiciel de modélisation tel qu'Erwin Data Modeler, en utilisant la même technique.
Une fois les entités de base de données importées, les utilisateurs peuvent commencer à normaliser les tables en fonction des relations de clé partagées ou établir des relations au sein du modèle si celles-ci ne sont pas automatiquement identifiées pendant le processus de rétro-ingénierie.
Ils peuvent également modifier des tables individuelles pour s'assurer que les champs pertinents et les conventions de dénomination sont reflétés dans l'entrepôt de données.
Concevez et configurez un schéma d'entrepôt de données qui répond à vos besoins en matière de rapports
Avec ADWB, vous pouvez créer un modèle dimensionnel en utilisant votre technique préférée, des schémas en étoile et en flocon de neige aux coffres de données et aux magasins de données opérationnelles, notre plate-forme les permet tous. Encore une fois, notre concepteur de modèle de données permet aux utilisateurs de gérer toutes ces tâches au niveau logique sans se plonger dans le code eux-mêmes.
Si l'entreprise dispose d'une base de données existante utilisée à des fins d'entreposage de données, elle peut procéder à l'ingénierie inverse et commencer la modélisation ou créer le schéma à partir de zéro à l'aide de tables de glisser-déposer dans le concepteur de modèles de données.
Quelle que soit l'approche, le processus de base reste le même. Une fois que vous avez configuré toutes les entités de votre schéma et vous êtes assuré que les relations sont correctement établies entre elles, vous les définissez en tant que faits ou dimensions. Nous avons également inclus une entité de dimension de date dédiée afin que vous puissiez regrouper les mesures commerciales en fonction de la période la plus appropriée. Des trimestres fiscaux aux périodes de vacances, nous sommes là pour vous.
Ensuite, les clés de substitution (identifie de manière unique chaque version des enregistrements) et les clés métier (une valeur d'identification attribuée dans les systèmes transactionnels basés sur la logique métier interne) seront affectées aux champs appropriés dans le générateur de mise en page pour chaque entité.
Vous pouvez également personnaliser la mise en forme des données, si des champs spécifiques sont obligatoires ou non, et décider des valeurs par défaut à afficher si une valeur n'apparaît pas pour un attribut particulier. Une mesure commerciale est-elle arrivée dans votre table de faits sans dimension associée? Pas de problème - il suffit de configurer une dimension d'espace réservé dans l'entité appropriée afin que l'intégrité référentielle soit toujours maintenue.
Encore une fois, tous ces changements au niveau des métadonnées affecteront la configuration de l'architecture de l'entrepôt de données après le déploiement.

Suivez automatiquement les modifications de vos données système source
L'un des principaux aspects de la maintenance de l'entrepôt de données est la gestion continue des mises à jour, des suppressions et des ajouts dans les tables système source. Après tout, l'EDW moderne est conçu pour fournir une vue à la fois actuelle et historique des données d'une organisation. Dans DWB, nous automatisons ces processus grâce à des types de cotes qui changent lentement. Il prend en charge plusieurs Techniques de traitement SCD, y compris SCD Type 1, Type 2, Type 3 et Type 6.
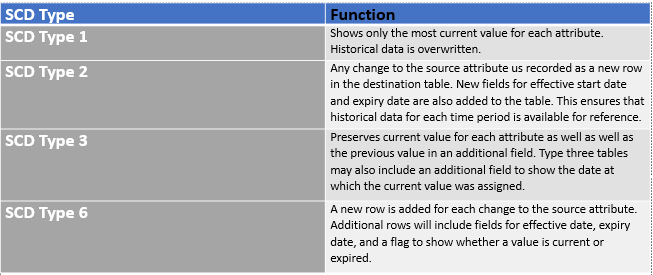
Changement lent des types de cotes
Dans le générateur de présentation, les utilisateurs peuvent choisir le type de cote à changement lent (SCD) le plus efficace pour chaque champ de dimension.
Propagez facilement les modifications du modèle de données vers votre entrepôt de données
Maintenant que le schéma de l'entrepôt de données est configuré au niveau des métadonnées, il vous suffit de vous assurer que votre base de données est prête à être remplie. Cela se fait via la fonction d'ingénierie avancée, qui applique toutes les modifications structurelles apportées au modèle dimensionnel à votre base de données physique.
À l'avenir, vous pouvez utiliser cette option pour propager rapidement les modifications de votre modèle de données vers la base de données de destination.
Vérifiez et déployez votre modèle de données en quelques clics
Une fois votre modèle de données configuré, vous êtes maintenant prêt pour le déploiement. Mais d'abord, vous voudrez vérifier l'intégrité de votre modèle de données à l'aide de notre outil pratique de vérification des données et éviter des heures de dépannage manuel.
Notre outil effectue des vérifications approfondies des données pour réduire ces tâches répétitives en mettant en évidence les erreurs dans votre modèle de données avant de passer à l'étape suivante de la production. Des champs incomplets aux erreurs de référence, vous pouvez détecter et corriger les problèmes potentiels dès le premier passage en utilisant cette fonctionnalité.
Accélérez radicalement le chargement de l'entrepôt de données
Dans ADWB, tous les ETL de l'entrepôt de données sont gérés par des objets de chargement de faits et de dimensions dédiés. Désormais, au lieu de créer des flux de données complexes, vous pouvez sélectionner un seul objet source ou plusieurs tables à partir d'un modèle de données source (plusieurs tables peuvent être sélectionnées à l'aide de l'objet Requête de modèle de données dans un flux de données) et les mapper à un chargeur. Ensuite, pointez simplement votre chargeur vers une table de faits ou de dimensions pertinente dans votre modèle dimensionnel déployé et votre cartographie est terminée.
Si vous devez appliquer des agrégats, des filtres ou des règles de validation supplémentaires à vos données de fait ou de dimension, il vous suffit de glisser-déposer la transformation souhaitée à partir de l'ensemble d'outils et de la configurer dans ce flux de données.
Une fois que vous avez terminé le mappage de la source vers l'entrepôt de données, ADWB exécutera les flux. Les données sont extraites de la source et traitées par les transformations nécessaires avant d'être chargées dans les tables appropriées de l'entrepôt. Ici, les clés de substitution et commerciales appropriées seront attribuées et les recherches seront effectuées comme défini lors de la phase de modélisation. Dans ADWB, nous avons ajouté une transformation de recherche de dimension dédiée qui croise automatiquement chaque clé métier avec la table SCD appropriée et la fait correspondre avec une clé de substitution appropriée.
Avec une solution d'entreposage de données de métadonnées, il vous suffit de créer le flux de données initial. Tout le codage impliqué dans le remplissage de l'entrepôt de données est généré automatiquement par notre plate-forme en mode pushdown dédié (ELT) pour garantir qu'une charge minimale est placée sur votre serveur pendant ces opérations gourmandes en ressources. En d'autres termes, vous pouvez peupler votre entrepôt de données en quelques minutes.
ADWB est indépendant de la plateforme!
ADWB propose des connecteurs prêts à l'emploi pour une gamme de destinations de bases de données, afin que vous puissiez configurer votre architecture d'entrepôt de données sur la plate-forme de votre choix sans vous soucier des problèmes de compatibilité. Actuellement, nous prenons en charge les bases de données cloud et sur site de pointe suivantes :
- Flocon de neige
- Amazon Redshift
- Azure Synapse Analytics
- Entrepôt de données autonome d'Oracle
- Teradata
- Entrepôt de données SAP
- Serveur SQL
- MariaDB
- Vertica
- IBM DB2
Interrogez et visualisez vos données d'entreprise à partir de toute application autorisée
Tous les modèles de données déployés sont également disponibles en tant que Services OData. Notre moteur d'entrepôt de données de métadonnées prend ces services, et enfin vers SQL afin que les tables puissent être consultées ou interrogées en dehors des applications et des navigateurs.
Tout ce dont vous avez besoin est l'adresse Web de votre déploiement et un jeton de support pour authentifier la connexion, et les données de votre entrepôt sont accessibles aux utilisateurs finaux via n'importe quelle application connectée.
Vous pouvez également utiliser votre entrepôt de données directement via les principaux outils de création de rapports et de visualisation tels que Tableau, Power BI, Domo, etc.
Orchestrez facilement toutes vos opérations ETL
Une fois votre entrepôt de données déployé, notre fonctionnalité de flux de travail vous aidera à gérer exactement la façon dont les différentes tables sont remplies. Une fois que vous avez décidé de la manière d'orchestrer ces opérations, chaque flux de données récupère les données du système source via la zone de transit et les migre dans le modèle de données dimensionnelles.
Automatisez les mises à jour et maintenez l'actualité de vos données d'entreprise
Les utilisateurs peuvent définir la fréquence de chargement des données pour chaque dimension en fonction de la fréquence à laquelle les tables du système source associées sont mises à jour. Avec la fonctionnalité Job Scheduler, vous pouvez orchestrer ces opérations pour qu'elles s'exécutent en continu, à des intervalles de temps spécifiques ou de manière incrémentielle lorsque des modifications sont apportées au système source.
Avec un entrepôt de données basé sur les métadonnées, vous n'avez pas à vous soucier de la qualité du code et de la façon dont il résistera à de gros volumes de données. Notre solution génère tous les scripts ETL nécessaires sur le backend par le moteur de métadonnées, et elle est soutenue par un moteur ETL de puissance industrielle conçu pour s'adapter à vos besoins. Ajoutez des fonctionnalités de surveillance et de journalisation des travaux en temps réel et les erreurs de conception majeures appartiennent au passé.
Agile, évolutif et accessible partout. Créez votre entrepôt de données en quelques jours avec Astera Constructeur d'entrepôt de données.
Vous souhaitez essayer notre solution? Nous vous offrons la possibilité de participer à notre campagne de lancement exclusive dès maintenant. Cliquez ici pour entrez en contact, et découvrez comment monter à bord.
FAQ
A architecture basée sur les métadonnées se concentre sur la gestion des métadonnées et joue un rôle essentiel pour garantir l'efficacité des systèmes d'aide à la décision. L'entreposage de données axé sur les méta est également un ETL de nouvelle génération et une plate-forme unifiée qui permet aux utilisateurs de concevoir l'entrepôt de données au niveau logique. Il encapsule la conception du schéma ETL et de l'entrepôt de données.
Dans un entrepôt de données, les métadonnées appartiennent à l'une des trois catégories suivantes :
- Métadonnées opérationnelles : les données du système source sont généralement filtrées, transformées, combinées et encore améliorées avant d'être intégrées dans l'entrepôt de données. Par conséquent, il peut être difficile de déterminer d'où proviennent ces documents. Les métadonnées opérationnelles fournissent l'historique complet d'un ensemble de données, à qui il appartient, les transformations spécifiques qu'il a subies, ainsi que son état actuel, c'est-à-dire qu'elles soient de nature actuelle ou historique.
- Métadonnées ETL : ces métadonnées sont utilisées pour guider le processus de transformation et de chargement de votre entrepôt de données. Il englobe le schéma physique des entités migrées, y compris les tables et les noms de colonnes, les types et valeurs de données contenus, ainsi que la disposition prescrite pour les tables de destination. Les métadonnées ETL incluent également les règles de transformation applicables, les définitions de faits/dimensions, les fréquences de chargement et les méthodes d'extraction.
- Métadonnées de l'utilisateur final : ce type de métadonnées est particulièrement utile pour les consommateurs qui interrogent et recherchent l'entrepôt de données au quotidien. Il fonctionne essentiellement comme une carte de l'entrepôt de données fournissant des détails sur les données contenues dans l'architecture, la manière dont les ensembles de données sont liés les uns aux autres (clés primaires/étrangères), les calculs nécessaires pour le mappage de la source à la destination, les ensembles de données spécifiques qui doivent être signalés sur et comment.
Les principaux avantages des métadonnées dans l'EDW sont :
- Fournit du tissu conjonctif pour des données autrement disparates dans une architecture de données complexe et à volume élevé.
- Facilite le mappage des systèmes sources vers l'entrepôt de données.
- Optimise les requêtes en catégorisant et en résumant les ensembles de données.
- Est utilisé efficacement à plusieurs étapes du cycle de vie de l'entrepôt de données, y compris la génération de schéma, l'extraction, le chargement dans l'entrepôt de données, la transformation dans la couche intermédiaire et pendant le processus de création de rapports.



