
L'automatisé, Pas de code Pile de données
Apprener comment Astera Data Stack peut simplifier et rationaliser la gestion des données de votre entreprise.

Traitement par lots ETL : un guide complet
Saviez-vous que le monde crée plus de données que jamais ? Si vous souhaitez connaître les chiffres exacts, on estime que les données dépasseront un chiffre stupéfiant. Zettaoctets 180 par 2025! La gestion de toutes ces informations nécessite des processus robustes et efficaces. C'est là que ETL ETL (Extract, Transform, Load) est un mécanisme essentiel pour gérer de grandes quantités d'informations. Imaginez maintenant que vous preniez ce puissant processus ETL et que vous le répétiez afin de pouvoir traiter d'énormes quantités de données par lots. C'est le traitement par lots ETL. Explorons ce sujet plus en détail !
Qu'est-ce que l'ETL?
ETL fait référence à un processus utilisé dans intégration de données et l'entreposage. Il rassemble des données provenant de diverses sources, les transforme dans un format cohérent, puis les charge dans une base de données cible, entrepôt de donnéesou lac de données.
- Extrait: Rassemblez des données à partir de diverses sources telles que des bases de données, des fichiers ou des services Web.
- Transformer: Nettoyez, validez et reformatez les données pour en assurer la cohérence et la qualité.
- Charge: Transférez les données transformées dans une base de données ou un entrepôt cible pour analyse et reporting.
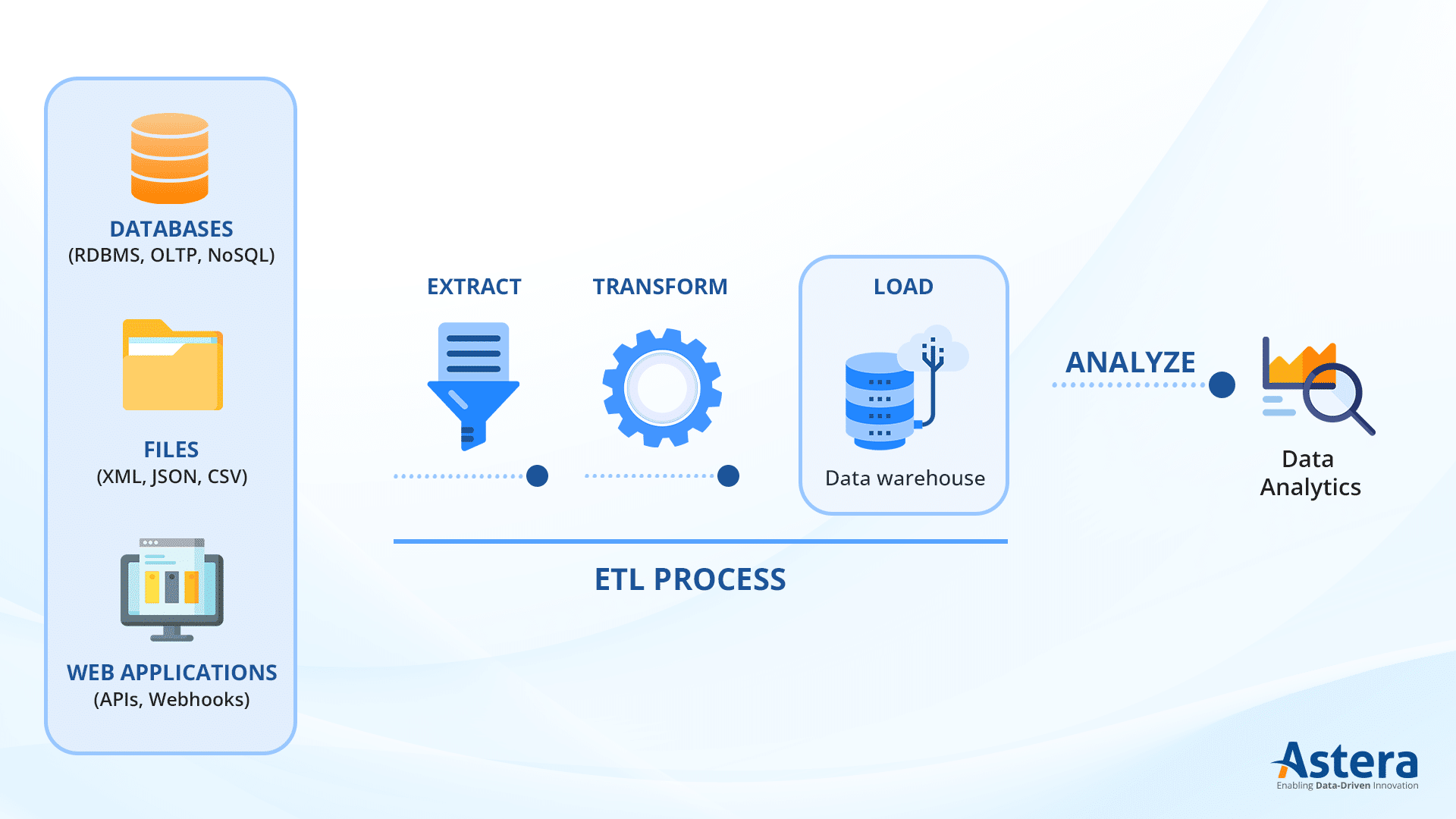
Qu’est-ce que le traitement par lots ETL ?
Le traitement par lots ETL implique la gestion des données en morceaux ou en lots prédéfinis plutôt qu'en temps réel. Il collecte des données sur des périodes spécifiques, comme des intervalles horaires ou quotidiens, puis les traite par lots. C'est particulièrement utile lorsque le traitement en temps réel n'est pas essentiel ou lorsque l'on traite de gros volumes de données qui nécessitent un temps de traitement important.
Le traitement par lots est efficace pour gérer de gros volumes de données car il laisse suffisamment de temps pour une transformation complète des données et des contrôles de qualité et garantit que seules des données propres et précises sont chargées dans le système cible. Puisqu'il ne nécessite pas de traitement immédiat dès l'arrivée des données, il peut être programmé pendant les heures creuses, réduisant ainsi la charge du système et optimisant l'utilisation des ressources.
Le traitement par lots est une stratégie idéale lorsque les charges de travail sont prévisibles et peuvent être prévues à l'avance. Il est également bien adapté à la génération de rapports et d’analyses périodiques, car il fournit des informations sur les tendances et modèles historiques plutôt que des mises à jour immédiates.
Comment fonctionne le traitement par lots ETL ?
Lorsqu'il s'agit de traitement par lots ETL, le flux de travail comprend généralement trois étapes ETL principales : l'extraction, la transformation et le chargement.
- extraction
Au cours de cette étape, les données sont extraites de diverses sources telles que des bases de données, des fichiers, des API ou des services Web, sur la base de critères prédéfinis, tels que des tables, des fichiers ou des délais spécifiques. Outils ETL tel que Astera extraire les informations requises des bases de données. Ces outils sans code peuvent simplifier l'extraction de données, qu'il s'agisse simplement de sélectionner toutes les lignes d'une table, ou aussi complexe que de joindre plusieurs tables et d'appliquer des filtres. Les données extraites sont ensuite récupérées et stockées dans la mémoire ou dans des fichiers temporaires, prêtes pour l'étape suivante. Lorsqu'il s'agit d'extraire des données de fichiers, les outils ETL prennent en charge un large éventail de formats, tels que CSV, Excel, XML, JSON, etc. Les outils analysent ces fichiers, extraient les données pertinentes et les convertissent dans un format structuré qui peut être facilement traité ultérieurement. De plus, les outils ETL peuvent également extraire des données de sources externes telles que des API ou des services Web. Ils effectuent des requêtes HTTP pour récupérer des données dans un format spécifique, tel que JSON ou XML, puis analysent et extraient les informations requises. - De La Carrosserie
Une fois les données extraites, elles passent par un processus de transformation, qui consiste à nettoyer les données, à valider leur intégrité et à les transformer dans un format standardisé afin qu'elles soient compatibles avec la base de données ou l'entrepôt de données cible. Le nettoyage des données est un aspect important du processus de transformation. Cela implique de supprimer toutes les incohérences, erreurs ou doublons des données extraites. Les outils ETL fournissent diverses fonctionnalités pour gérer le nettoyage des données, telles que la suppression des caractères spéciaux, la correction des fautes d'orthographe ou l'application de règles de validation des données. Il est important de garantir l’intégrité des données pendant le processus de transformation. Vous devez vérifier l'intégrité référentielle et la cohérence des types de données et vous assurer que les données respectent les règles ou contraintes métier. Vous pouvez automatiser le processus si vous utilisez un outil ETL. De plus, le processus de transformation implique souvent d'enrichir les données en les combinant avec des informations supplémentaires via des recherches dans des tables de référence, en fusionnant des données provenant de plusieurs sources ou en appliquant des calculs ou des agrégations complexes. - chargement
La dernière étape consiste à charger les données transformées dans le système cible, tel qu'un entrepôt de données, une base de données ou tout autre système de stockage permettant une analyse et un reporting efficaces. Lors du chargement de données dans un entrepôt de données, les outils ETL utilisent diverses techniques pour optimiser les performances. Ils utilisent des méthodes de chargement en masse, qui permettent une insertion plus rapide de gros volumes de données. De plus, ils utilisent des stratégies d'indexation pour améliorer les performances des requêtes et permettre une récupération efficace des données. Les outils ETL fournissent également des mécanismes pour gérer les mises à jour des données et le chargement incrémentiel. Cela signifie que seules les données modifiées ou nouvellement ajoutées sont chargées dans le système cible, minimisant ainsi le temps de traitement et réduisant l'impact sur les ressources système.
Traitement ETL en continu
Le traitement ETL en streaming, également appelé ETL en temps réel ou ETL continu, implique la gestion des données dans un flux continu plutôt que par lots. Il est conçu pour traiter et analyser les données dès leur arrivée, permettant des transformations et un chargement quasi instantanés dans le système cible. Le streaming ETL est utile dans les scénarios où des informations en temps réel ou quasi-réel sont essentielles, telles que :
- Détection de fraude: Analyser les transactions en temps réel pour détecter les activités frauduleuses.
- Traitement des données IoT: Traiter et analyser les données des capteurs ou des appareils connectés au fur et à mesure de leur arrivée.
- Analyse en temps réel: Prendre des décisions commerciales immédiates basées sur les données les plus récentes.
- Surveillance des journaux: Analyser les logs en temps réel pour identifier les problèmes ou anomalies.
En traitant les données au fur et à mesure de leur flux, les organisations peuvent obtenir des informations opportunes, réagir rapidement aux événements et prendre des décisions fondées sur les données et basées sur les informations les plus récentes.
Traitement par lots et traitement en streaming
Le choix du traitement par lots ou du traitement en streaming dépend de votre cas d'utilisation et de la capacité de votre processeur. Voici une liste de différences entre les deux pour vous aider à faire un choix éclairé :
Taille des données
Le traitement par lots traite de grands ensembles de données prédéfinis, tandis que le traitement par streaming gère des flux de données continus plus petits. La nature finie des données par lots facilite les opérations en masse, tandis que le traitement en continu s'adapte à des volumes de données potentiellement infinis et variables, exigeant une approche plus adaptable.
Temps d'exécution
Le traitement par lots ETL traite les données en masse à des intervalles programmés ou déclenchés manuellement, contrairement au streaming ETL, qui démarre instantanément le traitement lors de l'introduction de nouveaux enregistrements. Les opérations par lots sont discrètes et périodiques, tandis que les opérations de flux s'exécutent en continu à mesure que les données arrivent.
Délai de traitement
L'ETL par lots peut durer de quelques minutes à quelques heures, tandis que l'ETL en continu exécute des tâches en quelques millisecondes ou secondes. Le traitement par lots brille lorsqu'il s'agit de volumes de données massifs, tandis que les analyses en temps réel du streaming, comme dans la détection des fraudes, incitent à une action immédiate.
Ordre de traitement des données
Le traitement par lots manque de garanties de traitement séquentiel, ce qui peut potentiellement modifier la séquence de sortie. Stream ETL garantit le traitement des données en temps réel dans l'ordre de leur réception, ce qui est crucial pour maintenir l'exactitude des données, notamment dans les services financiers où l'ordre des transactions est important.
Voici un tableau comparatif résumant les principales différences entre le traitement par lots ETL et le traitement ETL en streaming :
| Traitement par lots ETL | Traitement ETL en continu | |
|---|---|---|
| Latence | Plus élevé (minutes à jours) | Inférieur (secondes à millisecondes) |
| Taille des données | Gère des ensembles de données volumineux et finis en masse | Gère des flux de données plus petits, continus et potentiellement infinis |
| Temps d'exécution | Traite les données en masse à intervalles planifiés | Commence instantanément le traitement à l'arrivée de nouveaux enregistrements |
| Délai de traitement | Plus long (minutes à heures) | Plus court (de quelques millisecondes à quelques secondes) |
| Ordre de traitement des données | Ne garantit pas la séquence de données d'origine | Traite les données en temps réel dans l'ordre dans lequel elles arrivent |
| Pertinence | Bien adapté à la gestion de quantités massives de données | Idéal pour des analyses en temps réel et des actions immédiates. |
Comment créer un pipeline ETL avec le traitement par lots
Construire un Pipeline ETL le traitement par lots implique plusieurs étapes. Voici un aperçu général du processus :
- Comprendre les exigences : Définissez les sources et les destinations de données et déterminez la fréquence d'exécution par lots pour établir le cadre ETL.
- Extraire les données : Récupérez des données de diverses sources, en garantissant l’intégrité et le respect des critères définis par lots.

- Transformer les données : Nettoyez, filtrez, agrégez et appliquez la logique métier tout en normalisant les formats si nécessaire.
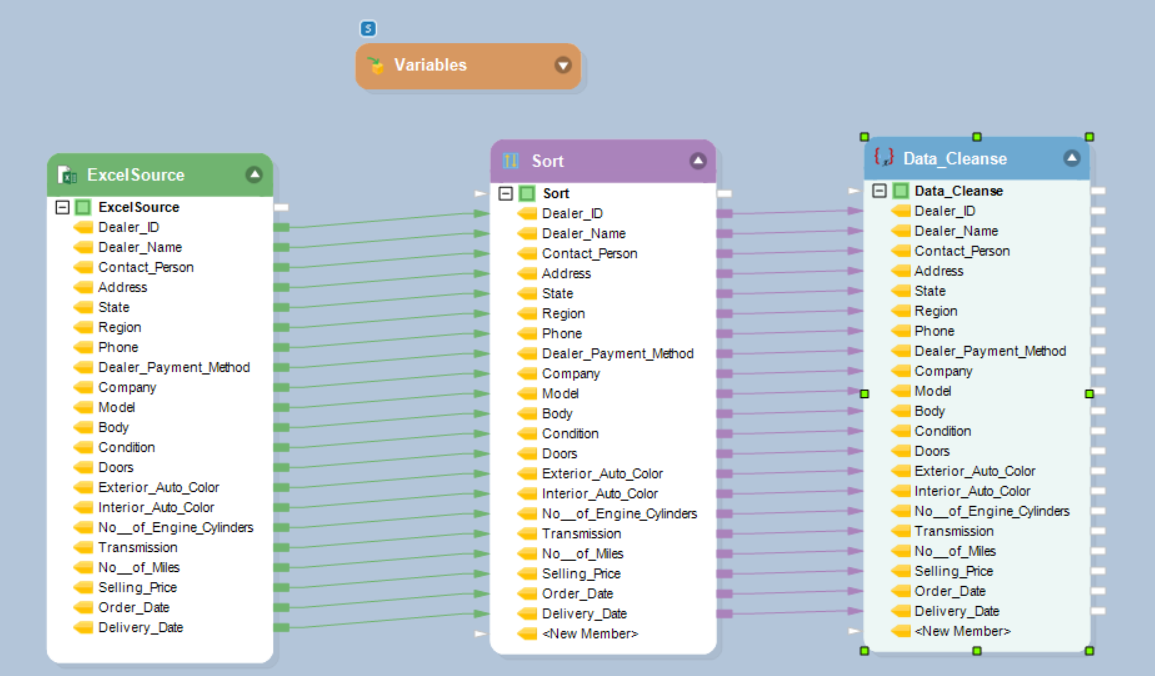
- Charger les données : Préparez et mettez à jour les schémas de destination, en chargeant les données transformées par lots dans le stockage.
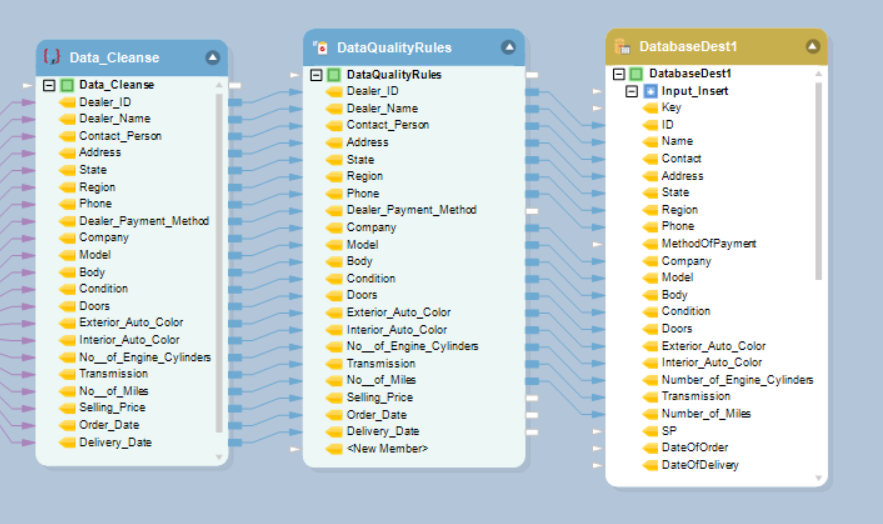
- orchestration: Utilisez des outils de flux de travail pour gérer et planifier les exécutions par lots et surveiller la qualité et les performances.
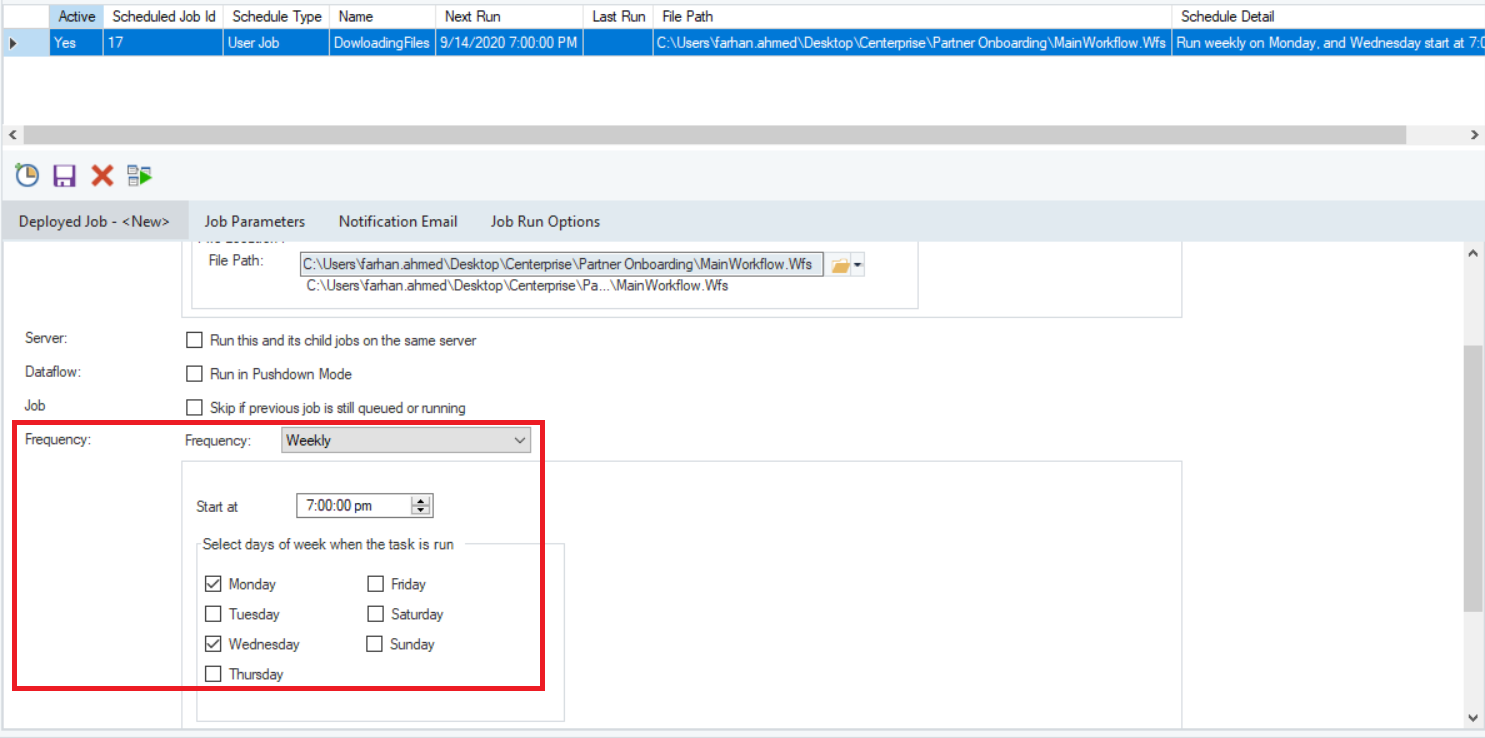
- Gestion et surveillance des erreurs : Mettez en œuvre des mécanismes pour résoudre les incohérences et les défaillances, surveiller les performances et générer des alertes en cas d'anomalies.
- Optimisation et évolutivité : Optimisez régulièrement pour de meilleures performances et évolutivité, en vous adaptant à des volumes de données plus importants ou à de nouvelles sources.
- Test et Validation : Complètement tester et valider le pipeline ETL pour garantir une sortie précise, complète et cohérente.
Pour plus de clarté, voici un étape par étape à l'aide de Astera pour créer et orchestrer un processus ETL pour l'intégration des partenaires avec des captures d'écran du produit.
Cas d'utilisation du traitement par lots ETL
Explorons quelques scénarios courants dans lesquels le traitement par lots ETL est largement utilisé.
Gestion des données de santé
Dans le domaine de la santé, le traitement par lots ETL est utilisé pour regrouper les dossiers des patients, les antécédents médicaux, les données de traitement et les diagnostics provenant de diverses sources. Cela prend en charge une analyse complète pour de meilleurs soins aux patients, la recherche et le respect des normes réglementaires telles que HIPAA. Le traitement par lots génère des rapports et des analyses périodiques qui fournissent des informations sur les tendances, les résultats et les performances sur des intervalles de temps spécifiques.
Logistique et Supply Chain Management
Le traitement par lots permet d'optimiser les opérations logistiques en analysant les données de la chaîne d'approvisionnement. Il prend en charge la mise à jour régulière des données d'inventaire, permettant aux organisations de rapprocher les niveaux de stock, d'identifier les écarts et d'ajuster les enregistrements d'inventaire de manière contrôlée et efficace. Il fournit également un moyen structuré et organisé d’échange de données entre les partenaires de la chaîne d’approvisionnement. Les fichiers batch peuvent être transmis à des intervalles convenus, ce qui améliore la collaboration tout en minimisant l'impact sur les opérations en temps réel.
Commerce électronique et vente au détail
Pour les entreprises de commerce électronique, ETL aide à analyser les données transactionnelles, le comportement des clients, les modèles d'achat et les préférences en matière de produits. Cela permet des stratégies marketing ciblées, des recommandations personnalisées et une gestion des stocks basées sur les tendances de consommation.
Analyse des médias sociaux et du marketing
Le traitement par lots ETL aide à analyser les données des réseaux sociaux pour évaluer le sentiment des clients, les mesures d'engagement et l'efficacité des campagnes marketing. Il consolide les données de plusieurs plates-formes pour obtenir des informations exploitables pour les stratégies marketing.
Traitement des données en temps réel augmenté par l'analyse par lots
Bien que le traitement par lots ETL fonctionne généralement à intervalles planifiés, il complète également le traitement des données en temps réel. L'analyse par lots des données collectées en temps réel offre des informations plus approfondies, permettant aux entreprises de dériver des tendances, des modèles et des modèles prédictifs pour les stratégies futures.
Rapports de conformité et réglementaires
Dans les secteurs soumis à des réglementations strictes comme la finance et la santé, le traitement par lots garantit la consolidation et la reporting précis des données requises pour la conformité. Cela inclut la génération de rapports, d'audits et de soumissions réglementaires à partir de diverses sources de données.
Établissements d’enseignement et systèmes de gestion de l’apprentissage
Pour les établissements d'enseignement et les plateformes d'apprentissage en ligne, ETL aide à consolider les dossiers des étudiants, les données de cours, les évaluations et les analyses d'apprentissage. Il prend en charge les expériences d'apprentissage personnalisées, le suivi des performances et l'amélioration des programmes.
Astera—la solution ETL automatisée pour toutes les entreprises

Astera est un 100 % sans code Solution ETL qui rationalise la création de programmes complets pipelines de données. La plateforme intègre de manière transparente des données provenant de diverses sources, que ce soit sur site ou dans le cloud, permettant un déplacement sans effort vers des destinations préférées telles qu'Amazon Redshift, Google BigQuery, Snowflake et Microsoft Azure. AsteraLes prouesses de résident dans sa capacité à construire des pipelines ETL entièrement automatisés, à accélérer le mappage des données grâce à AI Auto Mapper, à établir des connexions entre plusieurs sources et destinations, à améliorer la qualité des données pour une source unique de vérité fiable et à gérer sans effort de vastes volumes de données avec son système parallèle. moteur de traitement ETL. Voici quelques-unes des principales caractéristiques :
- Interface visuelle qui simplifie le processus de gestion des données de bout en bout, permettant une fonctionnalité glisser-déposer à chaque étape du cycle de vie ETL.
- Connecteurs étendus, garantissant une connectivité transparente à diverses sources et destinations de données, notamment les bases de données, les applications et les services cloud.
- Planificateur intégré, qui vous permet d'exécuter vos tâches une seule fois, en traitement par lots ou de manière répétitive selon le calendrier sélectionné. Parmi les programmes disponibles figurent : « Exécuter une fois », « Horaire », « Quotidien », « Hebdomadaire », « Mensuel » et « Lorsque le fichier est supprimé ».
- Des fonctionnalités avancées de validation des données qui garantissent l'exactitude et l'intégrité des données tout au long du processus d'intégration en permettant aux utilisateurs de définir et de mettre en œuvre des règles de validation complexes.
Prêt à créer des pipelines ETL de bout en bout avec un générateur de pipeline de données 100 % sans code ? Téléchargez un Essai gratuit 14-day ou inscrivez-vous à un demo.



