
O Automatizado, Nenhum código Pilha de dados
Saiba como Astera O Data Stack pode simplificar e agilizar o gerenciamento de dados da sua empresa.

Ingredientes da arquitetura de data warehouse orientada por metadados
Sejamos realistas, construir uma arquitetura de data warehouse que atenda a todas as suas necessidades requer muito planejamento e especialização. Uma arquitetura de data warehouse moderna deve integrar os dados do sistema operacional com precisão com a formatação correta e convenções de nomenclatura em vigor, deve ser flexível o suficiente para se adaptar às mudanças na estrutura dessas fontes subjacentes e deve fornecer desempenho otimizado para oferecer suporte a relatórios oportunos.
In Astera Construtor de DW (ADWB), uma ferramenta de data warehouse, oferecemos uma solução livre de código que traz escalabilidade, velocidade e agilidade ao desenvolvimento de data warehouse. A partir do designer de modelo de dados unificado, você pode acessar uma gama de funcionalidades detalhadas que economizam drasticamente o tempo e os custos envolvidos no projeto, configuração e implantação de sua arquitetura de BI. Vamos dar uma olhada em como esses ingredientes de uma arquitetura de data warehouse empresarial se juntam:
Controle de desenvolvimento de data warehouse de ponta a ponta

Desenvolvimento de Data Warehouse
Com o designer do modelo de dados do data warehouse, o ADWB fornece uma interface unificada onde os dados do sistema de origem podem ser importados, alinhados com o esquema de destino, desnormalizados e preparados para a migração para um modelo dimensional que é otimizado para relatórios e análises. O ADWB facilita esse processo de integração por meio de suas funções de engenharia reversa e engenharia direta.
Crie modelos de dados DWH enriquecidos para seus sistemas de origem
Nosso recurso de engenharia reversa pega um esquema de banco de dados de origem e o replica na forma de um modelo de relacionamento entre entidades. Este modelo mostra a estrutura lógica do banco de dados subjacente e oferece a capacidade de enriquecer esse esquema de várias maneiras para facilitar o carregamento no data warehouse.
O ADWB oferece integrações com uma variedade de bancos de dados líderes, incluindo SQL Server e Oracle Database, bem como provedores de nuvem, como Amazon e Microsoft Azure. Você também pode importar modelos de dados diretamente do software de modelagem, como o Erwin Data Modeler, usando a mesma técnica.
Depois que as entidades de banco de dados foram importadas, os usuários podem começar a normalizar as tabelas com base em relacionamentos de chave compartilhada ou estabelecer relacionamentos dentro do modelo, se eles não forem identificados automaticamente durante o processo de engenharia reversa.
Eles também podem editar tabelas individuais para garantir que os campos relevantes e convenções de nomenclatura sejam refletidos no data warehouse.
Projetar e configurar um esquema de data warehouse que atenda aos seus requisitos de relatório
Com ADWB, você pode criar um modelo dimensional usando sua técnica preferida, de esquemas em estrela e floco de neve a cofres de dados e armazenamentos de dados operacionais, nossa plataforma permite todos eles. Novamente, nosso designer de modelo de dados permite que os usuários gerenciem todas essas tarefas no nível lógico, sem mergulhar em qualquer parte do código.
Se a empresa tiver um banco de dados existente em uso para fins de armazenamento de dados, eles podem fazer engenharia reversa e começar a modelar ou podem construir o esquema do zero usando tabelas de arrastar e soltar no designer de modelo de dados.
Com qualquer uma das abordagens, o processo básico permanece o mesmo. Depois de configurar todas as entidades em seu esquema e garantir que os relacionamentos sejam estabelecidos corretamente entre elas, você os define como fatos ou dimensões. Também incluímos uma entidade de dimensão de data dedicada para que você possa agrupar medidas de negócios de acordo com o período de tempo mais adequado. De trimestres fiscais a feriados, temos tudo o que você precisa.
Em seguida, surrogate keys (identifica exclusivamente cada versão de registros) e chaves de negócios (um valor de identificação atribuído em sistemas transacionais com base na lógica de negócios interna) serão atribuídas a campos apropriados no construtor de layout para cada entidade.
Você também pode personalizar a forma como os dados são formatados, se os campos específicos são obrigatórios ou não, e decidir quaisquer valores padrão a serem mostrados se um valor não aparecer para um determinado atributo. Uma medida de negócios chegou à sua tabela de fatos sem uma dimensão associada? Não há problema - basta configurar uma dimensão de espaço reservado na entidade relevante para que a integridade referencial seja sempre mantida.
Novamente, todas essas mudanças no nível de metadados afetarão como a arquitetura do data warehouse é configurada após a implantação.

Rastreie automaticamente as alterações nos dados do sistema de origem
Um dos principais aspectos da manutenção do data warehouse é o tratamento contínuo de atualizações, exclusões e adições nas tabelas do sistema de origem. Afinal, o EDW moderno é construído para fornecer uma visão atual e histórica dos dados de uma organização. No DWB, automatizamos esses processos por meio de tipos de dimensão que mudam lentamente. Suporta múltiplos Técnicas de manipulação de SCD, incluindo SCD Tipo 1, Tipo 2, Tipo 3 e Tipo 6.
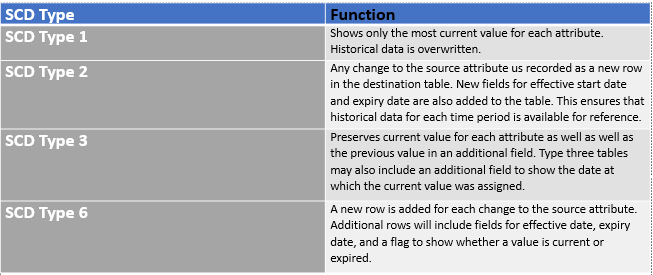
Tipos de dimensão que mudam lentamente
No construtor de layout, os usuários podem escolher o tipo de dimensão de alteração lenta (SCD) mais eficaz para cada campo de dimensão.
Propague facilmente as alterações do modelo de dados para seu data warehouse
Agora que o esquema do data warehouse está configurado no nível de metadados, você só precisa garantir que seu banco de dados esteja pronto para ser preenchido. Isso é feito por meio da função de engenharia direta, que aplica todas as mudanças estruturais feitas no modelo dimensional ao seu banco de dados físico.
Avançando, você pode usar esta opção para propagar rapidamente as alterações de seu modelo de dados para o banco de dados de destino.
Verifique e implante seu modelo de dados em alguns cliques
Com seu modelo de dados configurado, você agora está pronto para implantação. Mas primeiro, você vai querer verificar a integridade do seu modelo de dados usando nossa ferramenta de verificação de dados útil e evitar horas de solução de problemas manual.
Nossa ferramenta realiza verificações completas de dados para reduzir essas tarefas repetitivas, destacando quaisquer erros em seu modelo de dados antes de passar para o próximo estágio de produção. De campos incompletos a erros referenciais, você pode detectar e corrigir possíveis problemas na primeira passagem usando este recurso.
Acelere radicalmente o carregamento do data warehouse
No ADWB, todo ETL para o data warehouse é tratado por objetos de carregamento de dimensão e fato dedicados. Agora, em vez de construir fluxos de dados complexos, você pode selecionar um único objeto de origem ou várias tabelas de um modelo de dados de origem (várias tabelas podem ser selecionadas usando o objeto Consulta de modelo de dados em um fluxo de dados) e mapeá-los para um carregador. Em seguida, apenas aponte seu carregador para um fato relevante ou tabela de dimensão em seu modelo dimensional implementado e seu mapeamento estará completo.
Se você precisar aplicar agregados, filtros ou regras de validação adicionais aos seus dados de fato ou dimensão, você só precisa arrastar e soltar a transformação desejada do conjunto de ferramentas e configurá-la neste fluxo de dados.
Depois de concluir o mapeamento da origem ao data warehouse, o ADWB executará os fluxos. Os dados são retirados da origem e processados por meio das transformações necessárias antes de serem carregados nas tabelas relevantes do warehouse. Aqui, as chaves substitutas e de negócios apropriadas serão atribuídas e as pesquisas serão realizadas conforme definido durante o estágio de modelagem. No ADWB, adicionamos uma transformação de pesquisa de dimensão dedicada que faz referências cruzadas automaticamente a cada chave de negócios com a tabela SCD relevante e a combina com uma chave substituta apropriada.
Com uma solução de armazenamento de dados de metadados, você só precisa criar o fluxo de dados inicial. Toda a codificação envolvida no preenchimento do data warehouse é gerada automaticamente por nossa plataforma em modo pushdown dedicado (ELT) para garantir que a carga mínima seja colocada em seu servidor durante essas operações de uso intensivo de recursos. Em outras palavras, você pode preencher seu data warehouse em minutos.
ADWB é independente de plataforma!
O ADWB oferece conectores prontos para uso para uma variedade de destinos de banco de dados, para que você possa configurar sua arquitetura de data warehouse na plataforma de sua escolha sem se preocupar com problemas de compatibilidade. Atualmente, oferecemos suporte aos seguintes bancos de dados locais e na nuvem, líderes do setor:
- Floco de neve
- Amazon Redshift
- Azure Synapse Analytics
- Oracle Autonomous Data Warehouse
- Teradata
- SAP Data Warehouse
- SQL Server
- MariaDB
- vertical
- IBM DB2
Consulte e visualize os dados da sua empresa a partir de qualquer aplicativo autorizado
Todos os modelos de dados implantados também são disponibilizados como Serviços OData. Nosso mecanismo de data warehouse de metadados leva esses serviços e, finalmente, para SQL para que as tabelas possam ser visualizadas ou consultadas fora de aplicativos e navegadores.
Tudo que você precisa é o endereço da web de sua implantação e um token de portador para autenticar a conexão, e seus dados de warehouse estão acessíveis aos usuários finais por meio de qualquer aplicativo conectado.
Você também pode consumir seu data warehouse diretamente por meio de ferramentas líderes de relatório e visualização, como Tableau, Power BI, Domo e muito mais.
Orquestre facilmente todas as suas operações ETL
Depois que seu data warehouse for implantado, nossa funcionalidade de fluxo de trabalho o ajudará a gerenciar exatamente como as diferentes tabelas são preenchidas. Depois de decidir como orquestrar essas operações, cada fluxo de dados recuperará os dados do sistema de origem por meio da área de preparação e os migrará para o modelo de dados dimensionais.
Automatize atualizações e mantenha a oportunidade de seus dados corporativos
Os usuários podem definir a frequência de carregamentos de dados para cada dimensão com base na frequência com que as tabelas do sistema de origem relacionadas são atualizadas. Com o recurso Job Scheduler, você pode orquestrar essas operações para serem executadas continuamente, em intervalos de tempo específicos ou de forma incremental quando modificações são feitas no sistema de origem.
Com um data warehouse orientado por metadados, você não precisa se preocupar com a qualidade do código e como ele resistirá a grandes volumes de dados. Nossa solução gera todos os scripts de ETL necessários no back-end pelo mecanismo de metadados e é apoiada por um mecanismo de ETL de força industrial construído para escalar com seus requisitos. Adicione monitoramento de trabalho em tempo real e recursos de registro e os principais erros de projeto se tornarão uma coisa do passado.
Ágil, escalonável e acessível em qualquer lugar. Construa seu data warehouse em dias com Astera Construtor de Data Warehouse.
Interessado em experimentar nossa solução? Estamos oferecendo a você a oportunidade de participar de nossa campanha de lançamento exclusiva agora mesmo. Clique aqui para entrar em contatoe descubra como você pode embarcar.
A arquitetura orientada por metadados concentra-se no gerenciamento de metadados e desempenha um papel crítico em garantir a eficácia dos sistemas de apoio à decisão. O data warehouse orientado por meta também é um ETL de nova geração e uma plataforma unificada que permite aos usuários projetar o data warehouse no nível lógico. Ele engloba o design do esquema ETL e do Data Warehouse.
Em um data warehouse, os metadados se enquadram em uma das três categorias:
- Metadados operacionais: os dados do sistema de origem geralmente são filtrados, transformados, combinados e aprimorados antes de serem integrados ao data warehouse. Como resultado, pode ser difícil determinar a origem desses registros. Os metadados operacionais fornecem todo o histórico de um conjunto de dados, quem o possui, as transformações específicas pelas quais ele passou, bem como seu status atual, ou seja, se são atuais ou históricos por natureza.
- Metadados ETL: esses metadados são usados para orientar o processo de transformação e carregamento de seu data warehouse. Ele abrange o esquema físico de entidades migradas, incluindo tabelas e nomes de colunas, tipos e valores de dados contidos, bem como o layout prescrito para tabelas de destino. Os metadados ETL também incluem regras de transformação aplicáveis, definições de fatos / dimensões, frequências de carga e métodos de extração.
- Metadados do usuário final: este tipo de metadados é particularmente útil para consumidores que consultam e pesquisam o data warehouse diariamente. Ele funciona essencialmente como um mapa do data warehouse fornecendo detalhes sobre os dados contidos na arquitetura, como os conjuntos de dados se relacionam entre si (chaves primárias / estrangeiras), cálculos necessários para mapeamento da origem ao destino, conjuntos de dados específicos que precisam ser relatados e como.
Os principais benefícios dos metadados no EDW são:
- Fornece tecido conjuntivo para dados díspares em uma arquitetura de dados complexa e de alto volume.
- Facilita o mapeamento de sistemas de origem para o data warehouse.
- Otimiza a consulta categorizando e resumindo conjuntos de dados.
- É usado com eficácia em vários estágios do ciclo de vida do data warehouse, incluindo geração de esquema, extração, carregamento no data warehouse, transformação na camada de teste e durante o processo de relatório.



