
Автоматизированный, Без кода Стек данных
Научиться Astera Data Stack может упростить и оптимизировать управление данными вашего предприятия.

Анализ PDF-файлов: автоматизируйте извлечение данных из PDF-файлов и форм
PDF-файлы быстро стали предпочтительным форматом для обмена и распространения информации, благодаря своей читабельности. Однако отсутствие стандартизированной структуры данных может создать проблемы для извлечения данных. Эффективным решением этой проблемы является анализ PDF-файлов, который автоматизирует процесс извлечения, значительно устраняя необходимость ручного труда и оптимизируя извлечение данных.
Что такое парсинг PDF?
Анализ PDF-файлов, также известный как парсинг PDF-файлов или PDF извлечение данных, — это процесс извлечения неструктурированных данных из файлов PDF и преобразования информации в формат, который можно легко обрабатывать и анализировать. PDF-файлы, предназначенные для документов с фиксированным макетом, могут хранить различные типы данных и встречаются в разных типах, таких как PDF-файлы с возможностью поиска, сканированные PDF-файлы и заполняемые PDF-файлы. Анализ этих файлов необходим для раскрытия скрытой информации в документах.
Анализ PDF-файлов — незаменимый метод автоматизации извлечения данных, поскольку он позволяет предприятиям эффективно обрабатывать большие объемы деловых документов, не требуя ручного вмешательства. Автоматизируя процессы извлечения PDF-файлов, компании могут оптимизировать обработку документов, экономя значительное время и ресурсы и обеспечивая более быструю отчетность и аналитику.
Примеры использования PDF Parsing
Вот некоторые распространенные случаи использования анализа PDF:
Обработка страховых случаев
В страховом секторе клиенты подают формы претензий, часто в формате PDF. Эти формы содержат важную информацию, такую как сведения о клиенте, адрес, сумма претензии, тип полиса и номер полиса. Транскрипция этой информации вручную, особенно при большом объеме форм, требует много времени и подвержена ошибкам. Быстрая обработка этих претензий имеет важное значение для удовлетворенности клиентов и эффективности работы. Анализ PDF-файлов позволяет достичь этого за счет автоматизации всего процесса, обеспечивая точность и эффективность.
Отчеты пациентов
Анализ PDF-файлов облегчает извлечение сведений о пациенте, диагнозов и информации о лечении. Эти данные можно анализировать в исследовательских целях, интегрировать с другими системами или использовать для оптимизации медицинских рабочих процессов.
Прием на работу сотрудников
Анализ PDF собирает и извлекает данные из документов адаптации, что делает процесс адаптации сотрудников более эффективным. Эта автоматизация обеспечивает точный и оптимизированный ввод данных, позволяя HR-командам сосредоточиться на обеспечении беспрепятственной адаптации новых сотрудников.
Извлечение данных счета-фактуры
Предприятия ежедневно получают большое количество счетов-фактур, часто в форме PDF-файлов. Извлечение данных из этих счетов-фактур представляет собой серьезную проблему из-за их неструктурированного формата. Сбор данных о счетах-фактурах имеет решающее значение для бизнеса, поскольку он позволяет анализировать структуру расходов, выявлять возможности экономии и создавать точные финансовые отчеты. Кроме того, предприятия могут интегрировать полученные данные в системы бухгалтерского учета или использовать их для расширенной аналитики.
Распространенные проблемы синтаксического анализа PDF-файлов
Хотя анализ PDF-файлов чрезвычайно полезен, он имеет свои проблемы. Многие организации сталкиваются с трудностями при получении данных из файлов PDF, часто прибегая к ручному вводу данных в качестве решения по умолчанию, что может быть неэффективным и ресурсоемким.
Кроме того, управление значительным объемом PDF-файлов, обрабатываемых ежедневно, требует наличия значительной команды, занимающейся постоянным повторным вводом данных.
Альтернативный подход — разработка собственного программного обеспечения и решений для кодирования. Хотя этот подход имеет потенциал, он сопряжен с рядом проблем, таких как сбор данных из отсканированных PDF-файлов, поддержка различных форматов и преобразование данных в структуру, совместимую с системой хранения. Кроме того, изменчивость структуры PDF-файлов, например, различные макеты и шрифты, создает проблему для создания универсального решения для синтаксического анализа. Шифрование и защита паролем еще больше усложняют процесс, требуя расшифровки перед анализом и безопасной обработки паролей.
Решение этих проблем имеет решающее значение для разработки эффективных и действенных решений для анализа PDF-файлов в корпоративных условиях.

Необходимость автоматизации извлечения данных PDF
Вместо того, чтобы вводить данные вручную или создавать инструмент с нуля, мы рекомендуем выбрать решение для анализа PDF-файлов корпоративного уровня для автоматизации процесса. В исследовании показывает, что организации, использующие интеллектуальную автоматизацию, достигают экономии затрат от 40 до 75 процентов. Поэтому разумно инвестировать в инструменты автоматического анализа PDF-файлов, поскольку они могут предложить предприятиям конкурентное преимущество по сравнению с зависимостью от ручных процедур.
Преимущества использования решения для автоматического анализа PDF-файлов
- Сокращение времени и усилий: Устранение ручного вмешательства упрощает рабочие процессы извлечения данных, гарантируя эффективное и точное выполнение задач. Это также экономит драгоценное время сотрудников.
- Точность и согласованность: Использование сложных алгоритмов и машинного обучения сводит к минимуму риск человеческой ошибки, что приводит к созданию более надежного набора данных для анализа и принятия решений.
- Производительность и удовлетворенность сотрудников: Технология автоматизации освобождает сотрудников от бремени утомительных ручных задач, связанных с копированием и вставкой данных из PDF-файлов. Это заставляет сосредоточиться на более стратегических обязанностях и обязанностях, создающих добавленную стоимость.
- Масштабируемость: Независимо от того, работаете ли вы с несколькими сотнями или несколькими тысячами документов, технология автоматизации может эффективно обрабатывать различные объемы PDF-файлов. Такая масштабируемость особенно выгодна для организаций, работающих с большими объемами неструктурированных данных, таких как финансовые учреждения, поставщики медицинских услуг и государственные учреждения.
Как выбрать правильный парсер PDF?
При выборе парсера PDF крайне важно учитывать следующие аспекты:
Точность и надежность
Выберите решение с высокой точностью для извлечения данных из PDF-файлов. Синтаксический анализатор должен обрабатывать разнообразные макеты, шрифты и структуры PDF-файлов, чтобы обеспечить надежные результаты извлечения. Извлечение PDF-файлов на основе шаблонов обеспечивает 100% точность при правильной настройке, тогда как инструменты извлечения без шаблонов могут быть неточными, если модели не обучены правильно.
Гибкость и настройка
Оцените способность синтаксического анализатора адаптироваться к конкретным потребностям извлечения данных посредством настройки и конфигурации. Ищите функции, которые позволяют определять правила, шаблоны или шаблоны извлечения для согласованного извлечения данных. Также важна гибкость в работе с различным контентом.
Автоматизация и масштабируемость
Оцените уровень автоматизации, обеспечиваемый анализатором, и убедитесь, что он поддерживает пакетную обработку для извлечения данных из нескольких файлов PDF одновременно и в режиме реального времени (как только в системе появляются новые PDF-файлы). Для оптимизации процесса извлечения данных следует рассмотреть возможность интеграции с другими системами или возможностями автоматизации, включая оркестрацию и планирование рабочих процессов.
Интеграция и форматы вывода
Проверьте, поддерживает ли парсер экспорт извлеченных данных в различные форматы, такие как CSV, Excel, JSON или базы данных, для дальнейшей обработки и интеграции. Рассмотрите возможность использования облачных приложений организацией через свои API-интерфейсы для беспрепятственной интеграции данных.
Поддержка и обновления
Убедитесь, что парсер предлагает надежную техническую поддержку и регулярные обновления для быстрого решения любых проблем. Регулярные обновления обеспечивают совместимость анализатора с новейшими стандартами и технологиями PDF.
Дружественный интерфейс
Ищите синтаксический анализатор с удобным интерфейсом, который упростит настройку, мониторинг и управление задачами извлечения PDF-файлов. Хорошо спроектированный интерфейс может значительно улучшить общее впечатление от пользователя.
Astera ReportMiner для анализа PDF
Astera ReportMiner — это расширенное решение для анализа PDF-файлов, использующее искусственный интеллект для автоматического извлечения данных из PDF-файлов. Специально разработанное для PDF-документов с разнообразными макетами, это решение упрощает процесс извлечения и эффективно загружает данные в базы данных или файлы Excel. AsteraУдобный интерфейс без кода упрощает извлечение данных PDF, сводя к минимуму ручные усилия и ускоряя общий процесс извлечения.
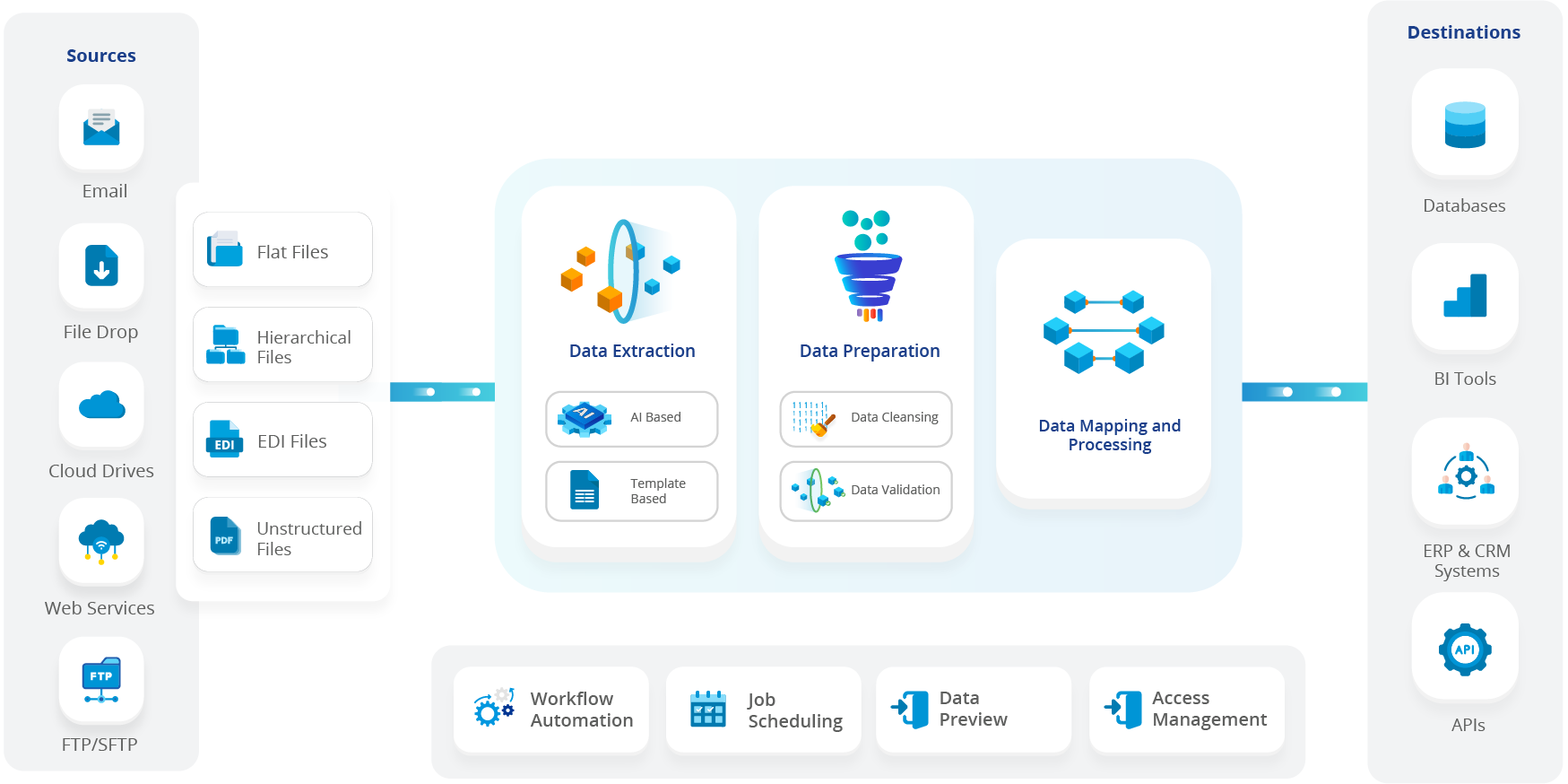
Основные характеристики Astera ReportMiner:
- Интеллектуальное извлечение данных: AsteraМеханизм на базе искусственного интеллекта эффективно извлекает данные из различных шаблонов, определяя нужные поля. Он умело управляет вариациями в разных шаблонах, обеспечивая быстрое и точное извлечение.
- Преобразование данных: Astera преобразует извлеченные данные в желаемый формат, облегчая фильтрацию, проверку, очистку или переформатирование в соответствии с конкретными требованиями.
- Пакетная обработка: Благодаря поддержке пакетной обработки инструмент позволяет одновременно извлекать данные из нескольких документов PDF для эффективной и запланированной обработки.
- Обработка в реальном времени: AsteraФункция удаления файлов в планировщике процессов извлекает информацию из файла, как только он появляется в папке, обеспечивая обработку в реальном времени.
- Интеграция с внешними системами: Astera ReportMiner легко интегрируется с внешними системами или базами данных, облегчая прямую загрузку извлеченных данных в предпочтительные места назначения.
- Обработка ошибок и протоколирование: Благодаря надежным механизмам обработки ошибок, ReportMiner управляет исключениями в процессе извлечения. Инструмент также предоставляет возможности ведения журнала для регистрации и отслеживания любых возникающих ошибок или проблем, обеспечивая беспрепятственное извлечение данных.
Расширьте возможности извлечения данных PDF с помощью Astera. Изучите наше решение с помощью 14-дневная бесплатная пробная версия или запланировать персонализированная демо с нашими экспертами, чтобы понять потенциал извлечения данных PDF с помощью искусственного интеллекта уже сегодня!



