
L'automatisé, Pas de code Pile de données
Apprener comment Astera Data Stack peut simplifier et rationaliser la gestion des données de votre entreprise.

Data Lake vs Data Warehouse : lequel vous convient le mieux ?
Pour comprendre la différence entre un lac de données et un entrepôt de données, il est important de comprendre l'évolution des technologies. Historiquement, les bases de données servaient de référentiels structurés excellant dans le stockage et la récupération de données organisées. Ils fonctionnaient selon des schémas bien définis, ce qui les rendait adaptés aux données transactionnelles et structurées. Cependant, à mesure que le volume, la variété et la vitesse des données ont explosé à l’ère numérique, les bases de données n’ont pas pu suivre le rythme.
Viennent ensuite les entrepôts de données qui ont aidé les entreprises en proposant une approche plus complète et intégrée de l'organisation et de l'analyse des données. Cependant, ils ont eu du mal à trouver l'agilité nécessaire pour gérer efficacement les données non structurées et semi-structurées, ce qui a conduit à l'introduction de lacs de données, solution flexible et évolutive conçue pour répondre aux défis modernes en matière de données.
Alors que les lacs de données constituent une mise à niveau vers entrepôts de données à certains égards, ils n'ont pas compromis l'utilité des entrepôts de données, qui jouent toujours un rôle central dans les organisations axées sur les données.
Dans ce blog, nous discuterons des différences entre les entrepôts de données et les lacs de données et des cas d'utilisation qui conviennent le mieux.
Qu'est-ce qu'un Data Lake?
Un lac de données est un système de stockage qui vous permet de stocker de grandes quantités de données structurées, semi-structurées et non structurées dans leur format brut natif. Contrairement aux bases de données traditionnelles qui exigent que les données soient conformes à un schéma prédéfini (schéma lors de l'écriture), les lacs de données utilisent une approche de « schéma lors de la lecture », ce qui signifie que dans un lac de données, les données sont stockées telles quelles, sans aucune modification. structure imposée. Cette absence de restriction de schéma rend les lacs de données idéaux pour stocker une grande variété de types de données, notamment du texte, des images, des vidéos, des fichiers journaux, des données de capteurs, des publications sur les réseaux sociaux, etc.
Les entreprises adoptent de plus en plus les lacs de données en raison de leur grande évolutivité, tant en termes de capacité de stockage que de puissance de traitement. Les organisations n'ont donc pas à se soucier d'ensembles de données volumineux et à croissance rapide, comme c'est le cas avec les systèmes traditionnels.
Quels sont les avantages d’un lac de données ?
Selon un sondage, 69% des répondants ont déclaré que leurs entreprises avaient déjà mis en place un lac de données. Voici les raisons de leur popularité croissante, outre l’évolutivité :
- Stockage économique: Le stockage des données dans des lacs de données est souvent plus rentable que les bases de données traditionnelles. Par exemple, la prévalence croissante de l’Internet des objets (IoT) a conduit à l’émergence de bases de données de séries chronologiques. Ces bases de données sont équipées de moteurs spécialisés, de modèles de données sur mesure et de langages de requête finement réglés pour gérer efficacement les données de séries chronologiques. Cependant, face à de vastes volumes de données de capteurs, les lacs de données offrent un substitut plus rentable aux bases de données de séries chronologiques.
- Divers types de données: L'un des facteurs les plus attrayants des lacs de données est qu'ils sont polyvalents dans le sens où ils peuvent stocker des données structurées, semi-structurées et non structurées, notamment du texte, des images, des vidéos et des données de capteurs.
- Flexibilité des données: Contrairement aux bases de données traditionnelles qui nécessitent que les données soient structurées à l'avance, les lacs de données vous permettent de stocker les données telles quelles et d'appliquer une structure si nécessaire.
- Ingestion de données en temps réel: Aujourd'hui, tout est question d'informations en temps réel et les lacs de données prennent en charge le streaming et l'ingestion de données en temps réel, ce qui les rend adaptés aux applications nécessitant un traitement et une analyse immédiats des données.
- Apprentissage automatique et IA: Les lacs de données sont bien adaptés aux applications d’apprentissage automatique et d’intelligence artificielle (IA), car ils donnent accès à des ensembles de données étendus et diversifiés.
- Archivage des données: Les lacs de données peuvent constituer une solution rentable pour l’archivage et la conservation des données à long terme.
- Schéma en lecture: Contrairement aux bases de données traditionnelles avec une approche de schéma en écriture, les lacs de données utilisent une approche de schéma en lecture, qui permet aux utilisateurs d'appliquer différents schémas ou structures selon les besoins de l'analyse.
- Catalogues de données et métadonnées: Les lacs de données incluent souvent des catalogues de données et des outils de gestion de métadonnées, qui aident les utilisateurs à découvrir, comprendre et gérer les données stockées dans le lac.
Qu'est-ce qu'un entrepôt de données?
Un entrepôt de données est un système de base de données spécialisé conçu pour stocker, gérer et analyser de grands volumes de données provenant de diverses sources afin de prendre en charge les activités de business intelligence et de reporting. Les entrepôts de données gèrent principalement des données structurées, organisées en tableaux avec des lignes et des colonnes. Ils stockent souvent des données historiques et sont optimisés pour fournir des performances de requête rapides. Ils prennent également en charge des complexes modélisation des données et l'analyse interactive, ce qui les rend essentiels à l'aide à la décision et à la planification stratégique.
L’avantage d’un entrepôt de données est qu’il permet aux entreprises de créer des data marts, des sous-ensembles de données spécialisés pour des départements ou des unités commerciales spécifiques. Datamarts améliorer la prise de décision à un niveau granulaire.
Lire la suite: Estimation du coût de l'entrepôt de données
Avantages d'un entrepôt de données
- Prise en charge des requêtes complexes: Les entrepôts de données sont optimisés pour les requêtes et analyses complexes, ce qui facilite la réponse à des questions complexes sur les données.
- Prise de décision améliorée: En fournissant une source de données unique et fiable, les entrepôts de données permettent une prise de décision meilleure et plus éclairée à tous les niveaux d'une organisation.
- La cohérence des données: Ils garantissent la cohérence et la qualité des données en intégrant des données provenant de diverses sources, réduisant ainsi les erreurs et les écarts.
- Analyse historique: Les entrepôts de données stockent des données historiques, permettant aux organisations d'analyser les tendances et de faire des prévisions basées sur les performances passées.
- Requêtes plus rapides: Leur structure et leur indexation optimisées permettent des performances de requête rapides, réduisant ainsi le temps nécessaire à la récupération et à l'analyse des données.
- Prise en charge de la veille économique: Les entrepôts de données servent de base aux outils de business intelligence, facilitant la visualisation et l'analyse des données pour la planification stratégique.
Data Lake contre entrepôt de données : architecture
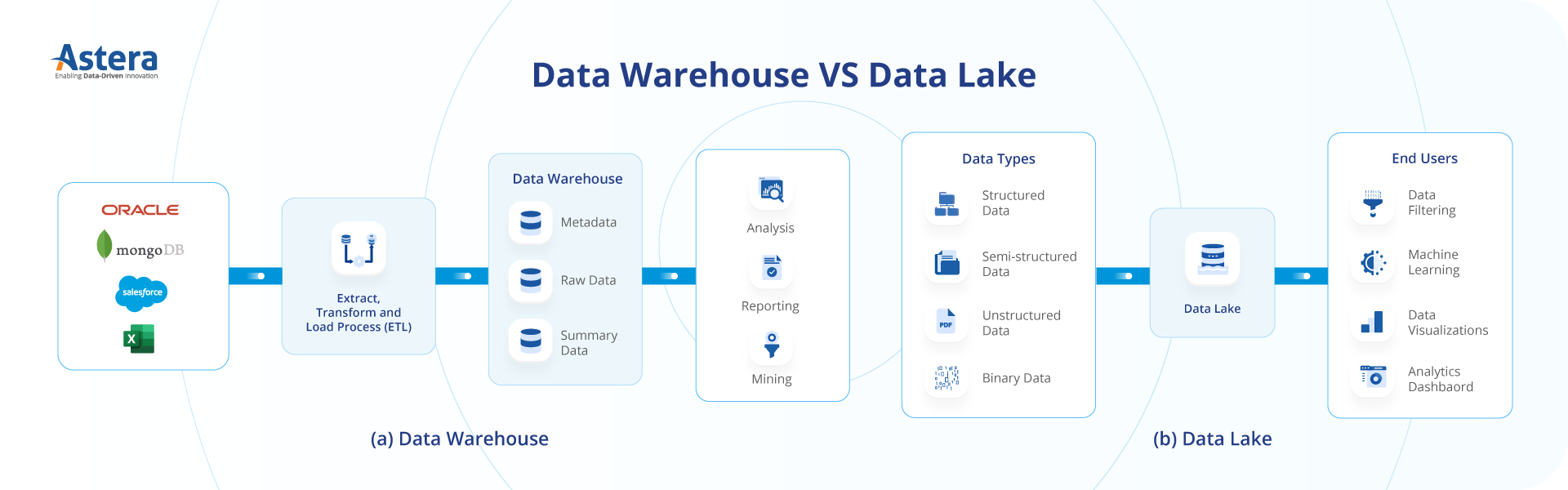
Si vous souhaitez comprendre la différence entre un lac de données et un entrepôt de données, vous devez d'abord comprendre la différence entre leur architecture. Une fois que vous aurez compris comment les deux sont organisés et comment ils fonctionnent, il vous deviendra plus facile de choisir entre les deux.
Architecture de lac de données
Couche d'ingestion de données
La première couche est la couche d'ingestion de données qui ingère les données provenant de diverses sources. Les lacs de données proposent généralement deux types d’ingestion de données :
- Ingestion par lots : avec les tâches par lots, vous pouvez planifier le transfert et le chargement de données dans le lac de données à des intervalles spécifiés.
- Ingestion en temps réel : pour les flux de données en temps réel, vous pouvez ingérer des données en continu et les traiter au fur et à mesure de leur arrivée.
Couche de stockage :
La deuxième couche est la couche de stockage.
- Stockage distribué : les lacs de données utilisent des systèmes de stockage distribués tels que Hadoop Distributed File System (HDFS) pour les environnements sur site ou des solutions de stockage basées sur le cloud telles qu'Amazon S3, Azure Data Lake Storage ou Google Cloud Storage. Avec ces systèmes, vous pouvez stocker des données à grande échelle.
- Partitionnement des données : les données sont généralement organisées en partitions ou en dossiers au sein du système de stockage, ce qui facilite la gestion et l'interrogation de sous-ensembles de données spécifiques.
Métadonnées et catalogue :
- Gestion des métadonnées : les métadonnées, qui fournissent des informations sur les données, sont cruciales dans un lac de données. Les métadonnées incluent des détails tels que la source de données, la structure des données, le lignage et la qualité. Les outils de gestion des métadonnées aident à organiser et à rendre les données visibles.
- Catalogue de données : un catalogue de données fournit une interface conviviale pour découvrir et comprendre les données du lac de données. Vous pouvez rechercher des ensembles de données et accéder aux métadonnées associées, les aidant ainsi à trouver les données dont ils ont besoin.
Couche de traitement des données :
- Transformation des données: Les lacs de données prévoient également le traitement et la transformation des données. Vous pouvez utiliser des frameworks tels qu'Apache Spark, Apache Hadoop ou des services ETL basés sur le cloud pour préparer les données à l'analyse.
- Intégration des données : vous pouvez également utiliser la couche de traitement des données pour intégrer et combiner des données provenant de diverses sources afin de créer une vue unifiée des données.
Couche d'accès et d'analyse :
- Outils d'accès aux données : Vous pouvez également accéder aux données et les analyser à l'aide de divers outils, notamment des moteurs de requête basés sur SQL, des langages de programmation comme Python et R, des outils de business intelligence et des plateformes d'analyse de données.
- Schéma à la lecture : Les lacs de données prennent en charge le schéma à la lecture, ce qui signifie que les données sont lues avec le schéma appliqué au moment de l'analyse. Ainsi, différents utilisateurs peuvent appliquer différents schémas aux mêmes données.
Couche de sécurité et de gouvernance :
- Contrôle d'Accès : Des contrôles d’accès robustes sont essentiels pour protéger les données sensibles. Vous pouvez utiliser ses fonctionnalités de sécurité pour mettre en œuvre les autorisations appropriées.
- Cryptage: Les lacs de données utilisent souvent le chiffrement pour protéger les données en transit et au repos.
Architecture de l'entrepôt de données
Architecture d'entrepôt de données définit la structure et les composants d'un système d'entreposage de données. Il existe généralement trois composants principaux dans une architecture d'entrepôt de données :
- Les sources de données:
- Sources de données opérationnelles: Il s'agit de systèmes tels que des bases de données, des logiciels CRM (Customer Relationship Management), des feuilles de calcul et diverses applications d'où proviennent les données d'une organisation.
- Sources de données externes: Les données peuvent également provenir de sources externes telles que des études de marché, des médias sociaux ou des fournisseurs de données.
- Processus ETL (Extraire, Transformer, Charger):
- Extraction: Les données sont extraites provenant de diverses sources et introduits dans l'entrepôt de données soit par traitement par lots, soit par streaming de données en temps réel.
- Transformer: Les données extraites sont nettoyées, validées et transformées pour s'adapter à un format ou une structure commune, à l'aide de transformations de données et de règles métier.
- Charge: Les données transformées sont chargées dans l'entrepôt de données, généralement organisées en tables de faits (contenant des données transactionnelles) et en tables de dimensions (contenant des données descriptives).
- Stockage dans l'entrepôt de données:
- Base de données de l'entrepôt de données: Les entrepôts de données utilisent des systèmes de gestion de bases de données (SGBD) spécialisés conçus à des fins analytiques. Les types courants incluent les bases de données relationnelles traditionnelles ou les bases de données en colonnes plus récentes. Les données transformées et structurées sont stockées ici.
- Datamarts: Les data marts sont des sous-ensembles de l'entrepôt de données, souvent adaptés à des unités commerciales ou à des départements spécifiques. Ils sont généralement utilisés pour une analyse plus ciblée.
- Couche d'accès aux données:
- Outils de requête et de reporting: Les utilisateurs finaux interagissent avec l'entrepôt de données à l'aide d'outils de requête et de reporting, tels que des interfaces basées sur SQL ou des outils BI (Business Intelligence).
- OLAP (traitement analytique en ligne): Les outils OLAP fournissent une analyse multidimensionnelle, qui permet aux utilisateurs d'explorer les données de différentes manières, en créant des pivots, des analyses approfondies et des analyses complexes.
- Référentiel de métadonnées:
- Les métadonnées sont des données sur les données. Il comprend des informations sur la structure et la signification des données stockées dans l'entrepôt. Les métadonnées aident les utilisateurs à comprendre et à localiser les données dont ils ont besoin pour l'analyse.
Data Lake et Data Warehouse : différences
Maintenant que vous comprenez l’architecture du lac de données et de l’entrepôt de données, voici quelques différences supplémentaires entre les deux :
| Caractéristique | Entreposage De Données | Lac de données |
| Objectif | Conçu pour les données structurées, optimisé pour le traitement analytique et le reporting. | Conçu pour stocker des données structurées et non structurées, y compris des données brutes et semi-structurées pour diverses analyses. |
| Structure de données | Stocke les données structurées avec un schéma bien défini, souvent sous forme de tableau. | Stocke les données dans leur format natif, y compris les données brutes, semi-structurées et structurées, sans schéma prédéfini. |
| Ingestion de données | Implique un processus ETL (Extract, Transform, Load) bien défini qui structure et nettoie les données avant de les charger dans l'entrepôt. | Permet l’ingestion de données sous leur forme brute, sans nécessité immédiate de transformation. La transformation peut être appliquée selon les besoins. |
| Performance | Optimisé pour les performances des requêtes, utilisant souvent des techniques telles que l'indexation et la pré-agrégation pour des réponses rapides aux requêtes SQL. | Donne la priorité au stockage des données par rapport aux performances des requêtes. Les performances des requêtes dépendent de la manière dont les données sont transformées et traitées lorsqu'elles sont interrogées. |
| Évolution du schéma | Les schémas sont relativement statiques et les changements peuvent nécessiter des efforts et une planification importants. | Permet la lecture du schéma, ce qui permet une flexibilité dans l'adaptation aux modifications des données sans avoir besoin de modifications de schéma initiales. |
| Flexibilité des types de données | Principalement conçu pour les données structurées ; peut ne pas bien gérer les données non structurées. | Conçu pour gérer efficacement les données structurées, semi-structurées et non structurées. |
| Utilisation | Principalement utilisé pour l'analyse de données structurées, la business intelligence et le reporting. | Utilisé pour un large éventail d'analyses, notamment l'analyse avancée, la science des données, l'apprentissage automatique et l'exploration des données. |
| Prix | Cela implique généralement des coûts de stockage et de requête plus élevés, car les données sont souvent dupliquées et indexées pour des raisons de performances. | Souvent rentable pour stocker de gros volumes de données brutes, mais les coûts peuvent augmenter avec le traitement et les transformations des données. |
| Qualité des données | Met l'accent sur la qualité, la cohérence et l'exactitude des données, souvent grâce à des pratiques strictes de gouvernance des données. | Offre de la flexibilité et peut nécessiter des efforts supplémentaires pour garantir la qualité et la cohérence des données. |
| Exemples | Les exemples incluent les entrepôts de données traditionnels comme Oracle Exadata, Teradata ou les services basés sur le cloud comme Amazon Redshift. | Les exemples incluent des solutions de lac de données basées sur le cloud comme Amazon S3 avec AWS Glue ou Azure Data Lake Storage avec Azure Databricks. |
Cas d'usage
En ce qui concerne les cas d'utilisation des lacs de données et des entrepôts de données, les lacs de données sont polyvalents et adaptables et peuvent répondre à un large éventail de types de données et de cas d'utilisation d'analyse, y compris l'analyse de données avancée et exploratoire. Ils peuvent gérer divers types de données et sont bien adaptés au traitement des données en temps réel et à l’analyse exploratoire des données.
Les entrepôts de données, quant à eux, se concentrent sur les données structurées, essentielles au reporting standardisé et à la business intelligence dans divers secteurs. Voici quelques-uns des cas d'utilisation les plus importants des deux entreposage de données et lacs de données :
Cas d'utilisation de l'entrepôt de données :
- Rapports financiers et analyse : Les entrepôts de données sont largement utilisés dans le secteur financier pour stocker et analyser des données financières structurées. Ils soutiennent principalement des activités telles que la budgétisation, les prévisions et les rapports financiers.
- Ventes au détail et gestion des stocks : Les organisations de vente au détail utilisent des entrepôts de données pour analyser les tendances des ventes, surveiller les niveaux de stocks et optimiser la gestion de la chaîne d'approvisionnement.
- Gestion de la relation client (CRM): Les entrepôts de données aident les organisations à analyser les données clients pour améliorer la satisfaction client, identifier les opportunités de vente et cibler les efforts marketing.
- Analyse des soins de santé : Le secteur de la santé utilise des entrepôts de données pour analyser les dossiers des patients, gérer les opérations de soins de santé et surveiller les résultats des patients afin d'améliorer la prise de décision et les soins aux patients.
- Analyse des ressources humaines : Les entrepôts de données aident les services RH à suivre les performances des employés, à gérer les données sur la main-d'œuvre et à prendre des décisions basées sur les données pour l'acquisition et la rétention des talents.
- Analyse de la logistique et de la chaîne d'approvisionnement : Les entreprises impliquées dans la gestion de la logistique et de la chaîne d'approvisionnement utilisent des entrepôts de données pour optimiser les itinéraires, gérer les stocks et suivre les marchandises en transit.
- Optimisation du processus de fabrication : Les fabricants utilisent des entrepôts de données pour surveiller et analyser les données de production, le contrôle qualité et les performances des équipements afin d'améliorer les processus et de réduire les coûts.
- Consommation d’énergie et gestion des services publics : Les sociétés énergétiques utilisent des entrepôts de données pour analyser les données de consommation d'énergie, surveiller les infrastructures et optimiser l'allocation des ressources.
Cas d'utilisation du lac de données :
- Mégadonnées et apprentissage automatique :
- Les lacs de données sont idéaux pour stocker et traiter de grands volumes de données diverses utilisées dans les modèles d'apprentissage automatique et les projets de science des données, tels que le traitement du langage naturel et la reconnaissance d'images.
- Analyse des médias sociaux:
- Les organisations qui analysent les données des plateformes de médias sociaux pour comprendre le ressenti des clients, suivre les mentions de marque et améliorer leurs stratégies marketing trouvent également les lacs de données plus adaptés.
- Analyse des données IoT :
- Les lacs de données sont bien adaptés au traitement des données générées par les appareils Internet des objets (IoT). Ils permettent une surveillance en temps réel et une maintenance prédictive dans des secteurs tels que l'industrie manufacturière et les villes intelligentes.
- Stockage et analyse des données génomiques :
- Les établissements de santé et de recherche stockent les données génomiques dans des lacs de données à des fins d’analyse et permettent des recherches personnalisées en médecine et en génomique.
- Flux de clics et Web Analytics :
- Les entreprises utilisent des lacs de données pour stocker et analyser les données de parcours, le comportement des utilisateurs sur les sites Web et les interactions en ligne afin d'améliorer l'expérience utilisateur et les efforts marketing.
- Analyse du texte et des sentiments :
- Les lacs de données peuvent également être utilisés pour stocker des données textuelles provenant de sources telles que des avis clients, des e-mails et des documents à des fins d'analyse des sentiments, d'exploration de texte et de recommandation de contenu.
- Données en streaming en temps réel :
- Les lacs de données ingèrent et analysent les données en streaming en temps réel, ce qui est crucial pour des applications telles que la détection des fraudes, la surveillance du trafic réseau et la prise de décision en temps réel.
- Archivage et conformité :
- Les organisations utilisent des lacs de données pour conserver les données à long terme, répondre aux exigences de conformité réglementaire et archiver les données historiques à des fins juridiques et d'audit.
Tendances émergentes
Il se passe toujours quelque chose de nouveau avec les lacs de données et les technologies d’entrepôt de données. Voici quelques-unes des principales tendances :
Convergence des lacs de données et des entrepôts de données :
Il s’agit d’une tendance émergente intéressante, car les organisations cherchent de plus en plus à combler le fossé entre les lacs de données et les entrepôts de données et à les faire converger vers une architecture « lakehouse ». Une Lakehouse vise à combiner les atouts des deux, afin que les données structurées et non structurées puissent coexister.
Plus d'automatisation
Les processus automatisés de gestion des entrepôts de données et des lacs de données deviendront plus répandus, ce qui permettra aux entreprises de déployer et de gérer rapidement ces technologies sans configurer manuellement ni utiliser d'API pour gérer leurs systèmes.
Utilisation accrue de la technologie cloud
La technologie cloud est de plus en plus populaire pour stocker et traiter de gros volumes de données. Les lacs de données et les entrepôts qui utilisent des solutions de stockage basées sur le cloud peuvent avoir une capacité supérieure à celle des solutions traditionnelles sur site. Ainsi, au fil du temps, ces technologies deviendront plus rentables.
Temps d'accès plus rapides
Les technologies de lac de données et d’entrepôt sont de plus en plus rapides, les entreprises peuvent donc s’attendre à des gains de performances encore plus importants.
Une solution de bout en bout pour le développement d'entrepôts de données modernes
Astera Constructeur DW offre une plate-forme unifiée que vous pouvez exploiter pour rationaliser tous les aspects de leur processus de développement, de la collecte initiale et du nettoyage des données à la conception de modèles de données prêts pour le reporting adaptés à vos exigences en matière de gouvernance des données, à votre cours et au déploiement de votre entrepôt de données dans le cloud. .
Avec ADWB, vous n'avez pas besoin de compter sur une pile technologique complexe ou sur des ressources techniques expérimentées pour faire passer votre implémentation sur toute la ligne. Le produit offre une interface intuitive par glisser-déposer, prend en charge une itération rapide et fonctionne aussi bien avec divers systèmes source et destination. Contactez notre équipe pour commencer avec Astera DW Builder aujourd'hui.



