
Автоматизированный, Без кода Стек данных
Научиться Astera Data Stack может упростить и оптимизировать управление данными вашего предприятия.

Оптимизация обработки претензий по автострахованию с помощью Astera
Сегодня индустрия автострахования решает проблему управление огромными объемами неструктурированных данных с помощью инновационных решений. Ведущий страховщик в Азиатско-Тихоокеанском регионе ожидает значительных улучшений за счет Генеративный ИИ в течение следующих 12 месяцев, чтобы повысить эффективность и точность обработки претензий по автострахованию. Astera — это мощный инструмент, который использует искусственный интеллект для упрощения и повышения точности обработки претензий.
Доступно Astera, страховые компании могут быстро сортировать и анализировать важную информацию из различных источников, ускоряя весь процесс урегулирования убытков.
Упрощение обработки претензий
Astera упрощает сложный процесс извлечение данных, в частности неструктурированные данные, при обработке претензий. Благодаря интерфейсу без кода, Astera делает извлечение данных доступным для бизнес-пользователей.
Основная функциональность Astera опирается на модель извлечения на основе шаблонов. Пользователи могут создавать модели отчетов. или шаблоны извлечения, которые помогают программному обеспечению идентифицировать и извлекать необходимые данные из различных неструктурированных источников, таких как отсканированные документы, заполняемые формы PDF и текстовые документы, связанные с претензиями по страхованию автомобиля. Такой подход упрощает процесс обработки данных за счет автоматизации.
Используя Asteraпредприятия могут преобразовывать неструктурированные данные о претензиях в структурированный формат. Это имеет решающее значение для ускорения процесса разрешения претензий, повышения точности и, в конечном итоге, повышения удовлетворенности клиентов.
Основные характеристики Astera для претензий по автострахованию Обработка
Astera ReportMiner извлекает информацию из сложных документов по претензиям, таких как PDF-файлы со сметой ремонта или текстовые документы, несущие информацию о материальный ущерб. Предприятия могут использовать Astera ReportMiner автоматизировать утомительный процесс парсинг различных PDF-документов, уменьшая необходимость операций по ручному вводу данных.
на базе искусственного интеллекта Добыча
Astera ReportMiner использует искусственный интеллект для автоматического определения необходимых полей в формах претензий, улучшая процесс извлечения. Этот Управляемый ИИ подход не только идентифицирует, но и разумно оценивает контекст и закономерности в данных.
Автоматизируя извлечение данных из PDF-файлов с помощью ИИ, Astera ReportMiner устраняет догадки и ручные усилия, традиционно необходимые для выявления и извлечения ключевых данных, оптимизируя рабочий процесс обработки претензий.
Автоматизированный рабочий процессs
Astera ReportMiner предлагает комплексные возможности автоматизации рабочих процессов, которые охватывают весь рабочий процесс обработки претензий, от извлечения данных до принятия решений. Это включает в себя автоматизацию конвейера извлечения для работы с пакетами PDF-файлов, что обеспечивает быстрый и эффективный доступ ко всей необходимой информации.
Эффективное извлечение на основе шаблонов
Для текстовых PDF-файлов пользователи могут создать шаблон извлечения, используя определенные шаблоны, присутствующие в документе, направляя Astera ReportMiner для точного получения информации. В случае отсканированных PDF-файлов ReportMinerВозможности OCR преобразуют эти документы в текстовые форматы для создания шаблонов извлечения.
Кроме того, для PDF-файлов на основе форм, распространенных в бизнес-операциях, ReportMiner упрощает извлечение бизнес-данных для дальнейшей отчетности и анализа.
После извлечения данных их можно преобразовать и экспортировать в различные места назначения, включая электронные таблицы Excel, базы данных и файлы CSV, что облегчает интеграцию в существующую экосистему данных организации.
Пошаговое руководство по Стриминг Cсчастье Обработка
В этом примере Astera тока процесс из начальный извлечение данных для разрешения претензий, принимая пакет претензий по автострахованию в качестве домен вариант использования. Каждая претензия в этой партии сопровождается подробным описанием ущерба. информация n PDF-формат.


Шаг 1: Чтобы начать процесс, загрузите PDF-форму в Astera ReportMinerдизайнер.
Шаг 2: Определите шаблон извлечения, определив и указав шаблоны, которые встречаются в исходном отчете. Тэти шаблоны будут идентичны для всех файлов в нашем пакете. поэтому мы сможем использовать один шаблон извлечения для всех файлов.
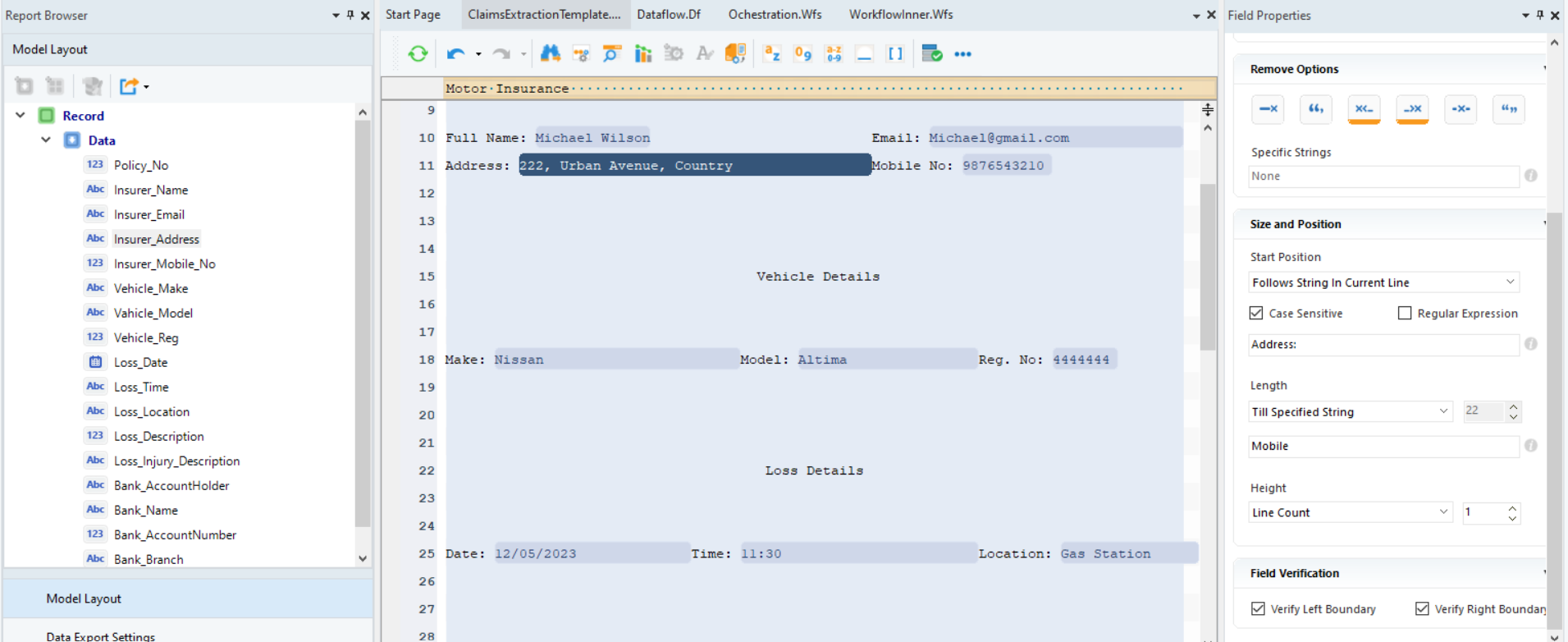
Шаг 3: В разделе свойств поля настройте размеры и расположение полей данных. Например, в случае поля адреса мы определили, что оно следует за строкой «Адрес» в текущей строке.
Шаг 4: После указания полей данных, региона и их положений для захвата в модели отчета просмотрите выходные данные извлеченных данных в окне предварительного просмотра данных.

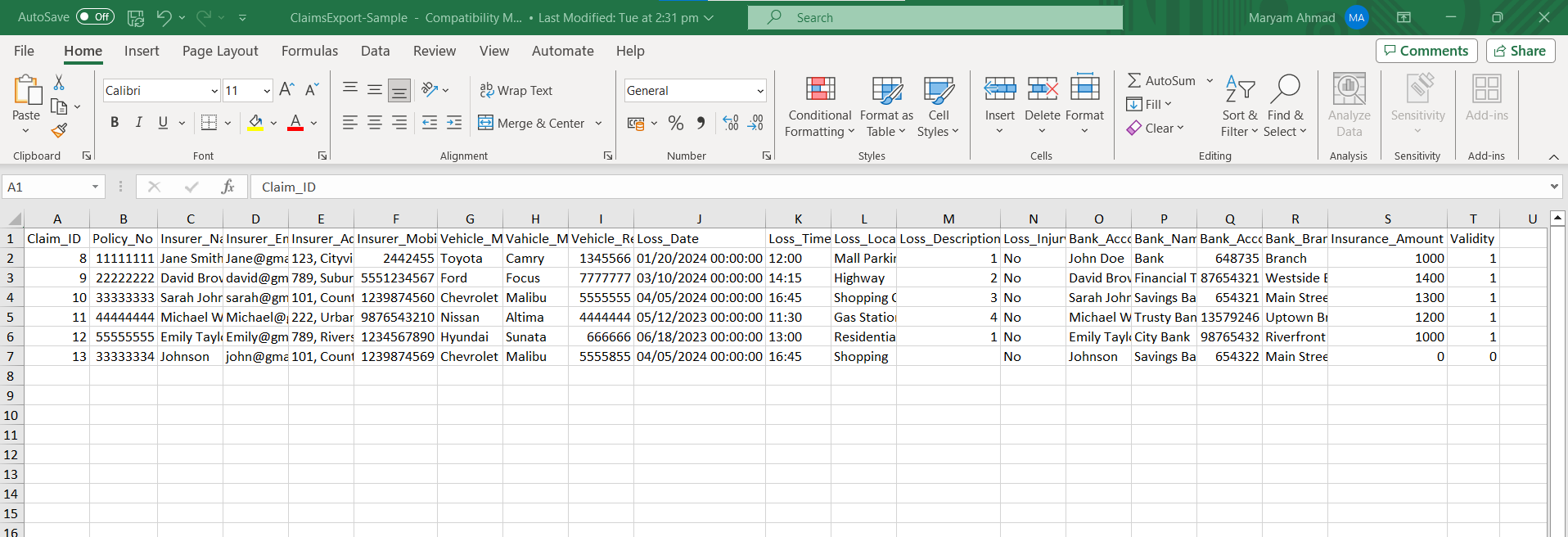
Ассоциация требования информация теперь находится в структурированном формате и может быть сохранена в таблице Excel для дальнейшего анализа.
Шаг 5: Для дальнейшей автоматизации процесса данных структурированных претензийдобавим эту модель отчета в поток данных, где мы сможем построить конвейеры данных.
Шаг 6: Объект Lookup ищет сумму страхования в базе данных по значению категории убытков в извлеченных данных о претензии. Мы включаем эту сумму в новое поле в записи претензий.
Также проверьте, обоснована ли претензия. Например, в этом случае, если убыток не входит в перечисленные категории, претензия признается недействительной и система не назначит ей никакой суммы. В таких случаях дайте команду системе записать ошибку.
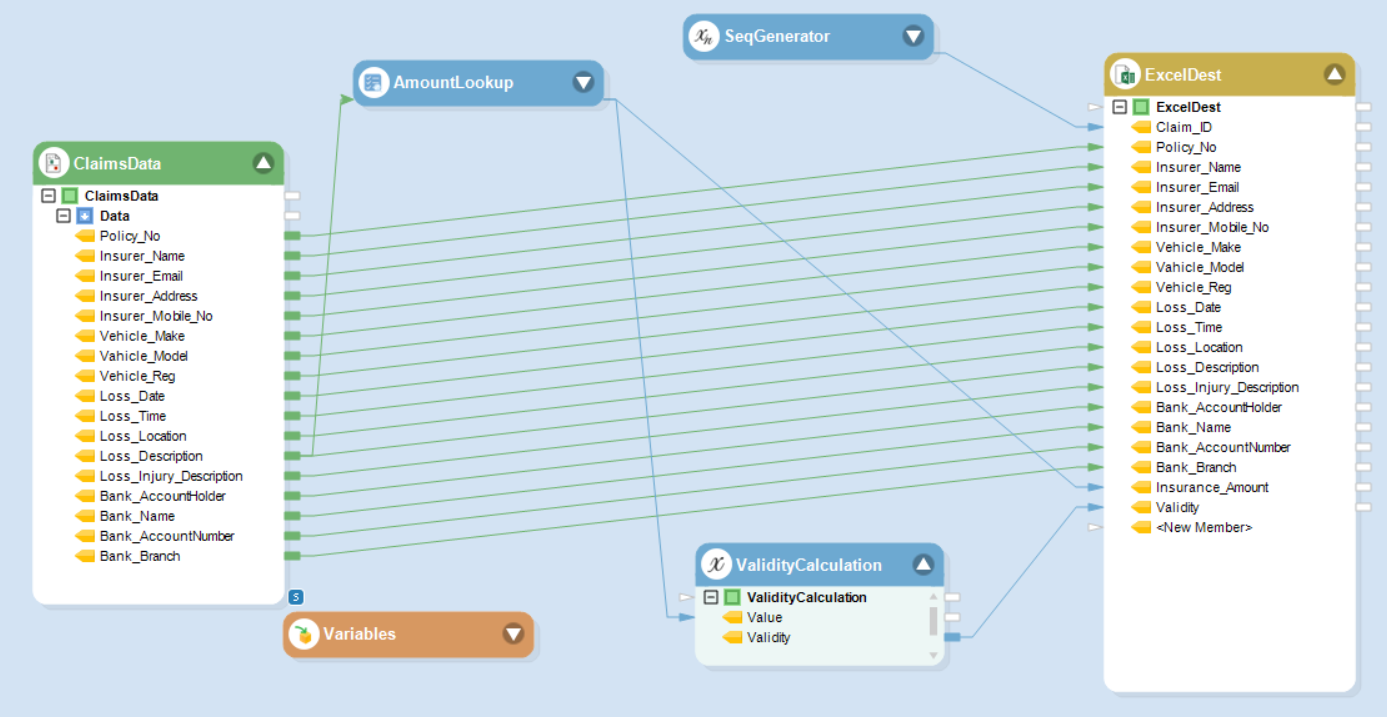
Шаг 7: Как только появится строка Поток данных выполняется, мы можем увидеть процесс обнаруживатьs ошибка в одном из требований, повлекшая за собой неначисление страховой суммы и пометку срока действия как 0.

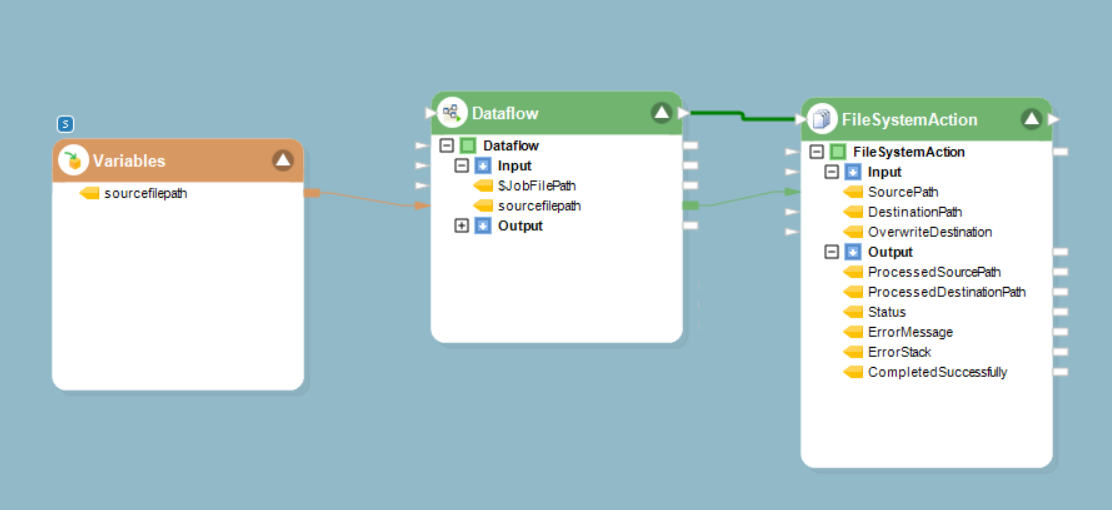
Шаг 8: В настоящее время этой данным обработка для один файл. Чтобы обработать всю партию, использовать домен Файлыystem в получить каждый файл в папкег и обрабатывать каждый файл через разработанный нами конвейер данных.
Шаг 9: Astera ReportMiner также предлагает автоматизированные контролироватьoкольцо. Используя ОтправитьМчеснок инструмент, мы можем настроить систему на автоматическую отправку электронного письма после обработки всех файлов.
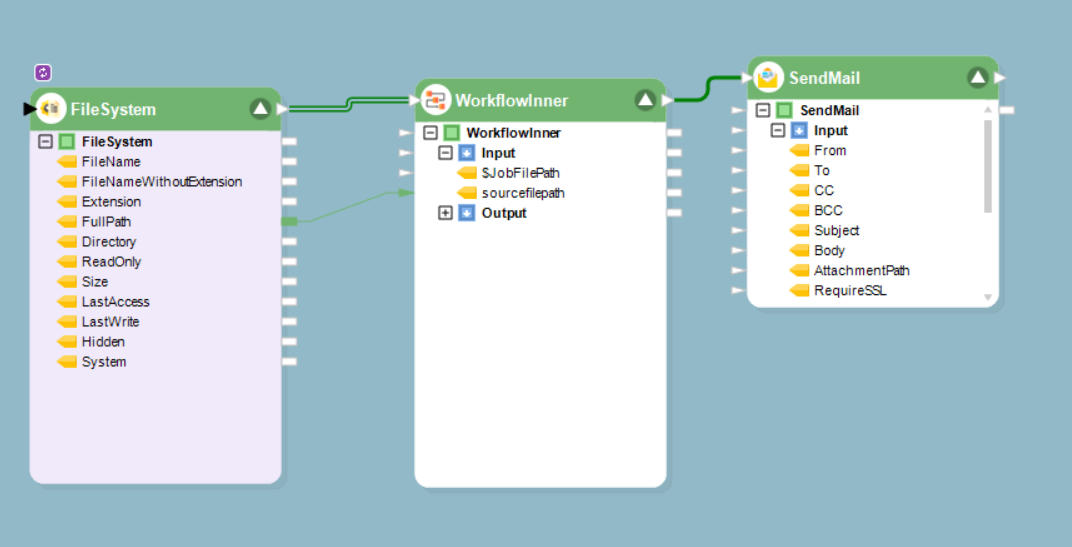
Как только мы запустим рабочий процесс, страховщик получит всю необходимую информацию по каждой претензии, что упростит процесс принятия решений и упростит определение того, какие претензии следует рассматривать.
Расширение возможностей роста и удовлетворенности для страховщиков
Улучшение Довольных клиентов
Когда клиент подает претензию, Astera ReportMiner быстро просматривает поданные документы. Программное обеспечение использует извлечение данных инструментом для выявления и получения соответствующей информации в режиме реального времени.
Это ускоряет процесс первоначальной проверки. и гарантирует, что все данные, используемые при принятии решений, являются точными и полными. В результате клиенты получают обновления и решения с беспрецедентной скоростью.
Astera ReportMiner интегрируется с платформами обслуживания клиентов, такими как Salesforce, что позволяет страховщикам предоставлять обновления статуса претензий непосредственно клиентам, способствуя прозрачным и доверительным отношениям.
Поддержка масштабируемости и роста
Astera ReportMiner масштабирует успех предоставляя основу, которая легко обрабатывает растущие объемы претензий. Его модель извлечения на основе шаблонов позволяет быстро обрабатывать аналогичные документы без необходимости постоянной реконфигурации. Это означает, что по мере роста страховой компании и увеличения количества претензий, Astera ReportMinerЭффективная обработка данных обеспечивает плавность и бесперебойность рабочего процесса.
Поскольку автоматизация снижает объем ручной работы, пользователи могут более эффективно распределять ресурсы и сосредоточиться на инициативах стратегического роста.
Astera ReportMiner может обрабатывать растущие объемы претензий без ущерба для качества и скорости, тем самым поддерживая цели расширения компании, сохраняя при этом высокую удовлетворенность клиентов. Откройте для себя преимущества интеграции Astera в свой рабочий процесс и узнайте, как это повлияет на вашу операционную эффективность и качество обслуживания клиентов.
Чтобы изучить, как Astera ReportMiner может произвести революцию в обработке претензий, запланировать демонстрацию прямо сейчас
Оптимизируйте автоматическую обработку претензий с помощью Astera
Готовы упростить процесс рассмотрения претензий? Пытаться AsteraИзвлечение данных бесплатно! Начните с 14-дневной бесплатной пробной версии и убедитесь, насколько простой и эффективной может быть обработка претензий.
Начать бесплатную пробную версию



