
Автоматизированный, Без кода Стек данных
Научиться Astera Data Stack может упростить и оптимизировать управление данными вашего предприятия.

Вот почему вам нужен PDF-экстрактор
Программное обеспечение для извлечения PDF-файлов может помочь вам преобразовать неструктурированные данные в PDF-файлах в чистые структурированные данные, которые можно хранить в хранилище данных для отчетности и бизнес-аналитики. Файлы формата переносимых документов (PDF) ими легко делиться и просматривать, и они сохраняют свою целостность на всех платформах (Windows, macOS, Linux и т. д.). В результате они составляют большую часть счетов-фактур, юридических документов и других официальных деловых документов на корпоративной арене. .
Несмотря на то, что форматы файлов PDF содержат ценную бизнес-информацию, они не идеально подходят для отчетности и анализа, т. е. представляют собой неструктурированные файлы, поэтому необходимы инструменты извлечения данных, чтобы превратить эти документы в генераторы аналитической информации.
Извлечение данных из PDF-файлов
Извлечение данных из файлов PDF является неотъемлемой частью рабочего процесса управления данными. Это позволяет организациям превращать необработанный неструктурированный текст в документах в структурированные данные для поддержания централизованного хранилища данных для отчетности и анализа. Однако это не прогулка по парку, поскольку данные в PDF-файлах не структурированы, то есть аккуратно расположены в столбцах и строках. Экстракторы PDF используют отсканированные изображения страниц из файла и выполняют оптическое распознавание символов для извлечения из них текста.
Извлечение данных из PDF-файлов: какие у вас есть варианты?
Когда дело доходит до извлечения данных из PDF-документов, первым делом нужно просто вручную ввести данные в системы. Хорошо, если у вас есть пара документов. Но при ежедневной обработке сотен и тысяч файлов это становится гораздо менее жизнеспособным вариантом даже для компаний среднего размера.
Давайте сравним ввод данных вручную с некоторыми другими доступными вариантами извлечения данных из PDF-документов:
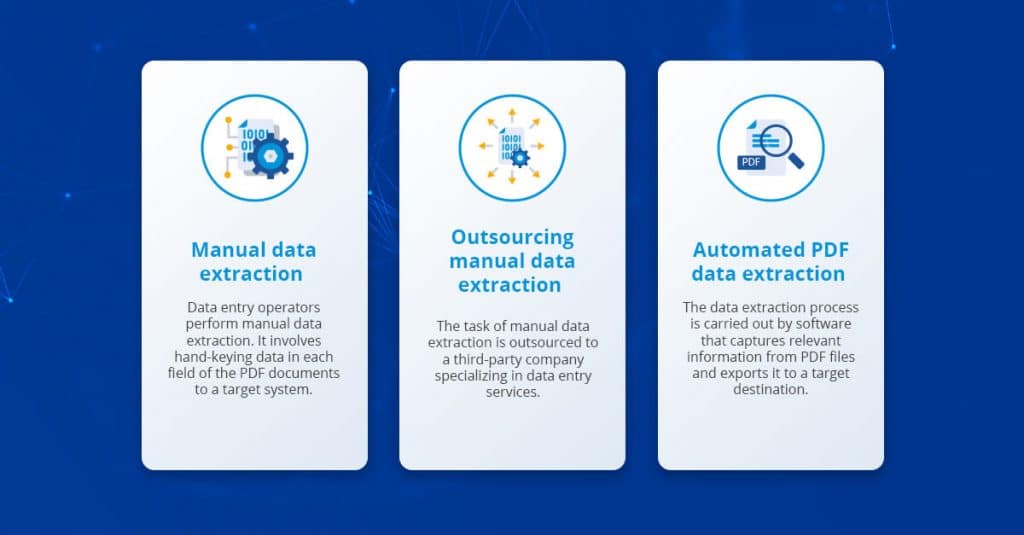
- Ручное извлечение данных является дорогостоящим, повторяющимся и трудоемким процессом. Это непрактичный вариант для обработки больших объемов данных. Он также подвержен человеческим ошибкам, которые влияют на качество данных.
- Аутсорсинг может в определенной степени минимизировать затраты и скорость извлечения данных; однако это создает серьезные проблемы с безопасностью данных и контролем качества, которые сводят на нет эти преимущества.
- Автоматическое извлечение данных — это самый быстрый и эффективный способ получения данных из файлов PDF. Современные программы для извлечения PDF-файлов могут обрабатывать тысячи документов за считанные секунды.
Извлечение данных, ориентированное на искусственный интеллект, и извлечение данных на основе шаблонов
Существует два основных подхода к извлечению данных: извлечение, ориентированное на искусственный интеллект, и извлечение данных на основе шаблонов.
Извлечение данных, ориентированное на искусственный интеллект
Извлечение данных, ориентированное на искусственный интеллект, — это новый подход, в котором алгоритмы машинного обучения и глубокого обучения используются для установления связей между наборами данных и отсканированными документами. Ученые, работающие с данными, обучают модели распознавать ключевые имена для ключевых полей в бизнес-данных на основе пользовательского ввода, помечать их, а затем извлекать соответствующий текст из неструктурированного документа.
Этот подход предлагает компаниям универсальность и масштабируемость и отлично работает для диалогового ИИ, где требуются понятность и ответы в реальном времени. Например, обученные чат-боты могут очень быстро отвечать на ожидаемые запросы клиентов. Более того, компании могут минимизировать время ответа с помощью контекстно-ориентированных ответов.
Однако процесс извлечения данных, ориентированный на искусственный интеллект, требует значительного обучения работе с наборами данных и навыков машинного обучения, поскольку модели необходимо обучать понимать неоднозначность, контекст и несколько сложных аспектов, связанных с распознаванием языка.
Разработчик моделей данных должен определить правильный объем данных, необходимый для обучения каждой модели, чтобы гарантировать, что точность и качество алгоритмических результатов соответствуют бизнес-требованиям. Если этот процесс плохо спроектирован или реализован, он может привести к получению некачественных данных из текстовых файлов.
Извлечение данных на основе шаблонов
Извлечение данных на основе шаблонов — это проверенный подход к обработке оцифрованных PDF-документов в больших масштабах. Он включает в себя создание шаблона извлечения данных для изоляции определенных текстовых разделов документа. Шаблон указывается с использованием положения и близости текста в документе.
Например, пользователь может указать шаблон или несколько шаблонов для извлечения данных из определенной области PDF-документа. Шаблон будет искать шаблон(ы) с определенной комбинацией алфавитов, слов, цифр или буквенно-цифровых символов, указанных пользователем для сбора информации.
Он требует относительно небольших вычислительных мощностей по сравнению с его аналогом, ориентированным на искусственный интеллект, и обеспечивает большую точность. Кроме того, шаблоны можно повторно использовать для документов PDF с аналогичной структурой, что ускоряет извлечение данных. Эта масштабируемость особенно полезна при извлечении данных из больших объемов PDF-файлов.
Тем не менее, извлечение данных на основе шаблонов также представляет некоторые проблемы. Например, документ PDF может содержать плавающее поле, т. е. расположение поля одной строки отличается от остальных строк. В некоторых случаях столбец смещен из-за деформации данных.
Современные решения для извлечения данных на основе шаблонов предназначены для решения этих проблем и создания всех возможных шаблонов для беспрепятственного сбора данных из PDF и других неструктурированных файлов.
Ключевые особенности PDF Extractor
Требования организаций к извлечению данных различаются в зависимости от варианта использования. Вот некоторые из наиболее обязательных функций PDF-экстрактора:
- Соединители с различными источниками и местами назначения данных
- Возможности автоматизации
- Оркестрация рабочего процесса
- Среда с нулевым кодом
- Простой в освоении, интуитивно понятный пользовательский интерфейс
Astera ReportMiner — Автоматизированный PDF-экстрактор без кода.
Astera ReportMiner — это средство извлечения PDF-файлов корпоративного уровня, которое автоматизирует и упрощает обработку неструктурированных документов. Его интуитивно понятный и простой в освоении пользовательский интерфейс позволяет бизнес-пользователям легко извлекать ценную информацию из PDF-документов. Пользователи могут создавать собственные правила качества данных для проверки извлеченных данных из файлов PDF.
Ключевые особенности Astera ReportMiner

Автоматизированное извлечение данных: истории успеха Astera Software
В течение многих лет Astera ReportMiner помог множеству организаций сэкономить время за счет автоматизации операций по извлечению данных. Вот несколько историй успеха клиентов, использующих наш PDF-экстрактор:
Ускоренная обработка данных по претензиям в формате PDF для Aclaimant
Aclaimant, поставщик передовых систем снижения рисков и управления инцидентами, использует Astera ReportMiner для быстрого извлечения страниц из PDF-файлов. Оно использует ReportMiner для сбора данных из форм претензий в формате PDF и записи их в отчеты Excel и CSV. Это привело к сокращению на 50 процентов времени и ресурсов, затрачиваемых на расшифровку форм претензий вручную.
Прочитайте полный пример здесь.
Автоматизированное извлечение данных в формате PDF для подрядчика ИТ-услуг государственной организации
Astera ReportMiner позволяет подрядчику ИТ-услуг, который обрабатывает информацию об истории работы государственных служащих, упростить извлечение данных в формате PDF и свести к минимуму ошибки, экономя более 1000 ручных часов в год.
Прочитайте полный пример здесь.
Извлечение данных из PDF-файлов заказов клиентов на поставку за считанные минуты для Ciena Corporation
Корпорация Ciena, поставщик сетевых услуг, программного обеспечения и оборудования, использует Astera ReportMiner извлекать ключевые данные из PDF-файлов заказов клиентов всего за 2 минуты вместо часов. Теперь компания может выполнять запросы клиентов в 15 раз быстрее.
Прочитайте полный пример здесь.
Извлеките данные за несколько простых шагов
Astera ReportMiner — это PDF Extractor с интуитивно понятным пользовательским интерфейсом без кода и расширенными функциями для сбора данных из файлов PDF.
1) Импортируйте PDF-файл.
Загрузите PDF-файл из локального или общего каталога. Текст на страницах PDF будет отображаться в конструкторе модели отчета.
*ReportMiner поддерживает различные типы файлов, включая Excel, RTF, PRN, EDI и т. д.
2) Создайте модель отчета
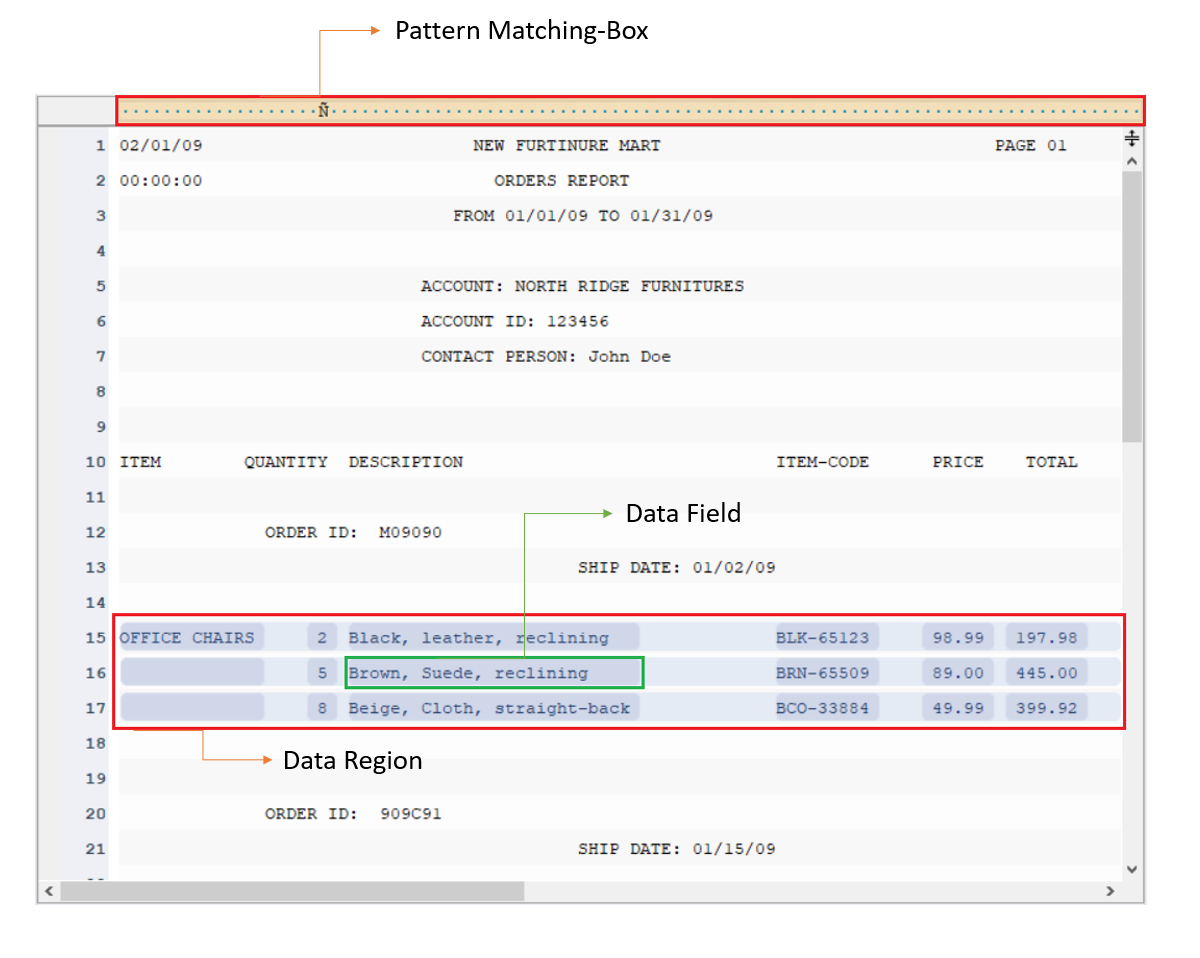
Используя поле шаблона и панели свойств региона, создайте модель отчета, выбрав наборы данных и страницы для извлечения и указав шаблон в интуитивно понятной среде без кода.

Укажите шаблон сопоставления областей для наборов данных на страницах, которые вы хотите извлечь из файла PDF. Повторите процесс, чтобы создать дополнительные поля данных для сбора всей необходимой информации в документе.
Шаблон извлечения дает вам полный контроль над процессом извлечения данных. Даже если у вас многостраничный документ, вы можете получить соответствующую информацию с определенных страниц или их части.
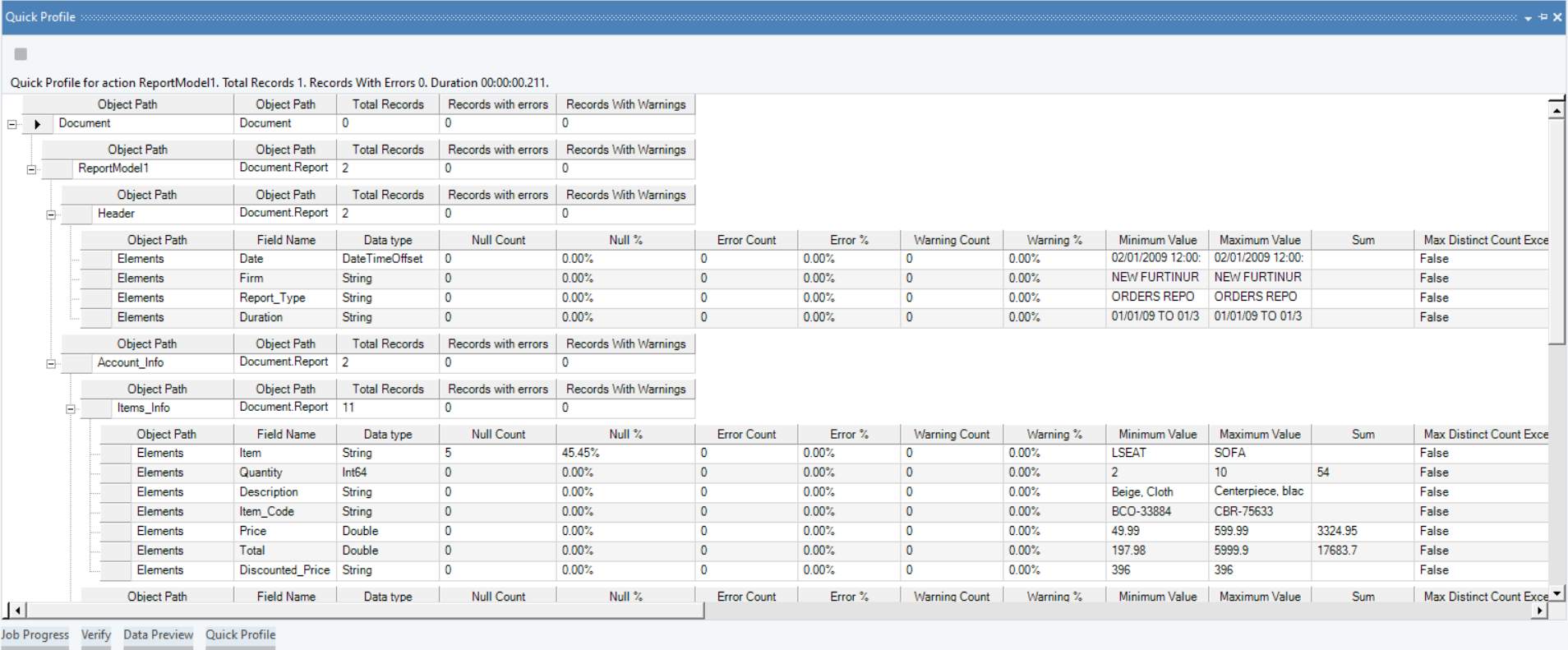
После извлечения данных вы можете использовать функцию предварительного просмотра данных, чтобы обеспечить точность и полноту информации.
3) Экспорт данных в пункт назначения
Вы можете экспортировать извлеченные данные из файлов PDF в файл Excel, CSV или любую базу данных по вашему выбору, локально или в облаке. Вы также можете открыть модель отчета в потоке данных, чтобы очистить данные и применить преобразования перед их экспортом в целевой пункт назначения.
И вы сделали. За несколько простых шагов вы легко структурируете неструктурированные данные, содержащиеся в деловых документах PDF.
Если вы ищете умный и интуитивно понятный инструмент для извлечения данных PDF, скачать получите 14-дневную бесплатную пробную версию нашего решения для автоматического извлечения данных сегодня или позвоните по телефону +1 888-77-ASTERA чтобы обсудить ваш вариант использования.



