
Die automatisierte, Kein Code Datenstapel
Erfahren Sie, wie Astera Data Stack kann die Datenverwaltung Ihres Unternehmens vereinfachen und rationalisieren.

Eine Einführung in den Aufbau von Datenpipelines in Python
Die Vielseitigkeit, die intuitive Syntax und die umfangreichen Bibliotheken von Python ermöglichen es Fachleuten, agile Pipelines zu erstellen, die sich an sich ändernde Geschäftsanforderungen anpassen. Python automatisiert nahtlos Arbeitsabläufe, verwaltet komplexe Transformationen und orchestriert reibungslose Datenbewegungen und schafft so eine Grundlage für eine effiziente und anpassungsfähige Datenverarbeitung in verschiedenen Bereichen.
Datenpipelines in Python
A Datenpipeline ist eine Reihe automatisierter Verfahren, die den nahtlosen Datenfluss von einem Punkt zum anderen ermöglichen. Das Hauptziel einer Datenpipeline besteht darin, eine effiziente Datenbewegung und -transformation zu ermöglichen und sie für Analysen, Berichte oder andere Geschäftsvorgänge vorzubereiten.
Aufgrund seiner Einfachheit und Anpassungsfähigkeit wird Python häufig bei der Erstellung von Datenpipelines verwendet. Eine Datenpipeline in Python ist eine Folge von Datenverarbeitungselementen, wobei jede Stufe Daten von der vorherigen Stufe übernimmt, eine bestimmte Operation ausführt und die Ausgabe an die nächste Stufe weitergibt. Das Hauptziel besteht darin, Daten aus verschiedenen Quellen und in verschiedenen Formaten zu extrahieren, zu transformieren und (ETL) in ein einziges System zu laden, wo sie gemeinsam analysiert und angezeigt werden können.
Python-Datenpipelines sind nicht auf ETL-Aufgaben beschränkt. Sie können auch komplexe Berechnungen und große Datenmengen bewältigen und eignen sich daher ideal für Aufgaben wie Datenbereinigung, Datenintegration, Datentransformation und Datenanalyse. Durch die Einfachheit und Lesbarkeit von Python sind diese Pipelines einfach zu erstellen, zu verstehen und zu warten. Darüber hinaus bietet Python mehrere Frameworks wie Luigi, Apache Beam, Airflow, Dask und Prefect, die vorgefertigte Funktionen und Strukturen zum Erstellen von Datenpipelines bereitstellen, was den Entwicklungsprozess beschleunigen kann.
Hauptvorteile von Python beim Aufbau von Datenpipelines
- Flexibilität: Das umfangreiche Angebot an Bibliotheken und Modulen von Python ermöglicht ein hohes Maß an Individualisierung.
- Integrationsfähigkeiten: Python kann nahtlos in verschiedene Systeme und Plattformen integriert werden. Seine Fähigkeit, eine Verbindung zu verschiedenen Datenbanken, cloudbasierten Speichersystemen und Dateiformaten herzustellen, macht es zu einer praktischen Wahl für den Aufbau von Datenpipelines in unterschiedlichen Datenökosystemen.
- Erweiterte Datenverarbeitung: Das Ökosystem von Python umfasst leistungsstarke Datenverarbeitungs- und Analysebibliotheken wie Pandas, NumPy und SciPy. Diese Bibliotheken ermöglichen komplexe Datentransformationen und statistische Analysen und verbessern die Datenverarbeitungsfähigkeiten innerhalb der Pipeline.
Python-Datenpipeline-Frameworks
Python-Datenpipeline-Frameworks sind spezialisierte Tools, die den Prozess der Erstellung, Bereitstellung und Verwaltung von Datenpipelines optimieren. Diese Frameworks bieten vorgefertigte Funktionen, die die Aufgabenplanung, das Abhängigkeitsmanagement, die Fehlerbehandlung und die Überwachung übernehmen können. Sie bieten einen strukturierten Ansatz für die Pipeline-Entwicklung und stellen sicher, dass die Pipelines robust, zuverlässig und effizient sind.
Es stehen mehrere Python-Frameworks zur Verfügung, um den Prozess der Erstellung von Datenpipelines zu optimieren. Diese beinhalten:
- Luigi: Luigi ist ein Python-Modul zum Erstellen komplexer Pipelines von Batch-Jobs. Es übernimmt die Abhängigkeitsauflösung und hilft bei der Verwaltung eines Workflows, wodurch es einfacher wird, Aufgaben und ihre Abhängigkeiten zu definieren.
- Apache-Strahl: Apache Beam bietet ein einheitliches Modell, das Entwicklern den Aufbau datenparalleler Verarbeitungspipelines ermöglicht. Es unterstützt sowohl Batch- als auch Streaming-Daten und bietet ein hohes Maß an Flexibilität. Diese Anpassungsfähigkeit macht Apache Beam zu einem vielseitigen Werkzeug für die Bewältigung unterschiedlicher Datenverarbeitungsanforderungen.
- Airflow: Airflow ist eine systematische Plattform, die Arbeitsabläufe definiert, plant und überwacht. Es ermöglicht die Definition von Aufgaben und deren Abhängigkeiten und übernimmt die Orchestrierung und Überwachung von Arbeitsabläufen.
- Dask: Dask ist eine vielseitige Python-Bibliothek, die für die einfache Ausführung paralleler Rechenaufgaben entwickelt wurde. Es ermöglicht parallele und größere Berechnungen als der Speicher und lässt sich gut in bestehende Python-Bibliotheken wie Pandas und Scikit-Learn integrieren.
- Präfekt: Prefect ist ein modernes Workflow-Management-System, das Fehlertoleranz priorisiert und die Entwicklung von Datenpipelines vereinfacht. Es bietet eine übergeordnete Pythonic-Schnittstelle zum Definieren von Aufgaben und ihren Abhängigkeiten.
Python-Datenpipeline-Prozess
Sehen wir uns die fünf wesentlichen Schritte zum Aufbau von Datenpipelines an:
1. Installation der erforderlichen Pakete
Bevor Sie mit dem Aufbau einer Datenpipeline beginnen, müssen Sie die erforderlichen Python-Pakete mit pip, dem Paketinstallationsprogramm von Python, installieren. Wenn Sie Pandas zur Datenbearbeitung verwenden möchten, verwenden Sie den Befehl „pip install pandas“. Wenn Sie ein bestimmtes Framework wie Airflow verwenden, können Sie es mit „pip install apache-airflow“ installieren.
![]()
2. Datenextraktion
Der erste Schritt besteht darin, Daten aus verschiedenen Quellen zu extrahieren. Dies kann das Lesen von Daten aus Datenbanken, APIs, CSV-Dateien oder Web Scraping umfassen. Python vereinfacht diesen Prozess mit Bibliotheken wie „requests“ und „beautifulsoup4“ für Web Scraping, „pandas“ für das Lesen von CSV-Dateien und „psycopg2“ für die PostgreSQL-Datenbankinteraktion.
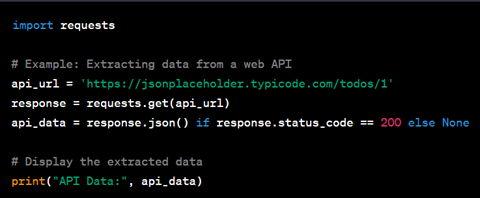
3. Datentransformation
Sobald die Daten extrahiert sind, müssen sie häufig in ein geeignetes Format für die Analyse umgewandelt werden. Dies kann das Bereinigen, Filtern, Aggregieren der Daten oder das Durchführen anderer Berechnungen umfassen. Für diese Vorgänge ist die Pandas-Bibliothek besonders nützlich. Insbesondere können Sie „dropna()“ verwenden, um fehlende Werte zu entfernen, oder „groupby()“ zum Aggregieren von Daten.
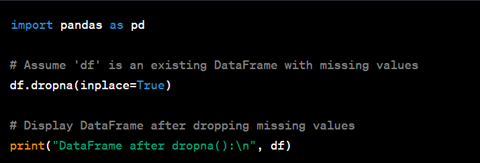
4. Daten laden
Nachdem die Daten transformiert wurden, werden sie in ein System geladen, wo sie analysiert werden können. Dies kann eine Datenbank, ein Data Warehouse oder ein Data Lake sein. Python stellt mehrere Bibliotheken für die Interaktion mit solchen Systemen bereit, darunter „pandas“ und „sqlalchemy“ zum Schreiben von Daten in eine SQL-Datenbank sowie „boto3“ für die nahtlose Interaktion mit Amazon S3 im Falle eines Data Lake auf AWS.
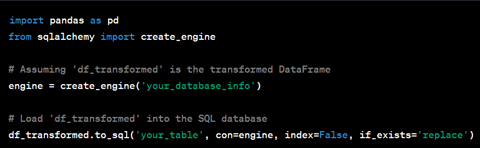
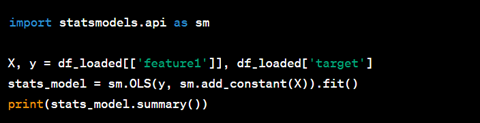
5. Datenanalyse
Der letzte Schritt besteht darin, die geladenen Daten zu analysieren, um Erkenntnisse zu gewinnen. Dies kann die Erstellung von Visualisierungen, die Erstellung von Modellen für maschinelles Lernen oder die Durchführung statistischer Analysen umfassen. Python bietet für diese Aufgaben mehrere Bibliotheken an, etwa „matplotlib“ und „seaborn“ für die Visualisierung, „scikit-learn“ für maschinelles Lernen und „statsmodels“ für statistische Modellierung.
Während dieses Prozesses ist es wichtig, Fehler und Ausfälle ordnungsgemäß zu behandeln, sicherzustellen, dass die Daten zuverlässig verarbeitet werden, und Einblick in den Zustand der Pipeline zu gewähren. Die Datenpipeline-Frameworks von Python wie Luigi, Airflow und Prefect bieten Tools zum Definieren von Aufgaben und ihren Abhängigkeiten, zum Planen und Ausführen von Aufgaben sowie zum Überwachen der Aufgabenausführung.
Aufbau von Datenpipelines: Code- vs. No-Code-Ansatz
Python bietet zwar ein hohes Maß an Flexibilität und Kontrolle, stellt jedoch bestimmte Herausforderungen dar:
- Komplexität: Der Aufbau von Datenpipelines umfasst die Handhabung verschiedener komplexer Aspekte wie das Extrahieren von Daten aus mehreren Quellen, das Transformieren von Daten, den Umgang mit Fehlern und die Planung von Aufgaben. Die manuelle Implementierung kann ein komplexer und zeitaufwändiger Prozess sein.
- Mögliche Fehler: Manuelle Codierung kann zu Fehlern führen, die zum Ausfall von Datenpipelines oder zu falschen Ergebnissen führen können. Das Debuggen und Beheben dieser Fehler kann ebenfalls ein langwieriger und herausfordernder Prozess sein.
- Wartung: Manuell codierte Pipelines erfordern häufig eine umfangreiche Dokumentation, um sicherzustellen, dass sie von anderen verstanden und verwaltet werden können. Dies verlängert die Entwicklungszeit und kann zukünftige Änderungen erschweren.
Der Prozess des Aufbaus und der Wartung von Datenpipelines ist komplexer geworden. No-Code-Lösungen sind darauf ausgelegt, diese Komplexität effizienter zu bewältigen. Sie bieten ein Maß an Flexibilität und Anpassungsfähigkeit, das mit herkömmlichen Codierungsansätzen nur schwer zu erreichen ist, und machen die Datenverwaltung umfassender, anpassungsfähiger und effizienter
Während Python nach wie vor eine vielseitige Wahl ist, setzen Unternehmen zunehmend auf Code-freie Datenpipeline-Lösungen. Dieser strategische Wandel wird durch den Wunsch vorangetrieben, das Datenmanagement zu demokratisieren, eine datengesteuerte Kultur zu fördern und den Pipeline-Entwicklungsprozess zu rationalisieren, um Datenexperten auf allen Ebenen zu stärken.
Vorteile von No-Code-Datenpipeline-Lösungen
Die Entscheidung für eine automatisierte No-Code-Lösung zum Aufbau von Datenpipelines bietet mehrere Vorteile, wie zum Beispiel:
- Effizienz: No-Code-Lösungen beschleunigen den Prozess des Aufbaus von Datenpipelines. Sie sind mit vorgefertigten Konnektoren und Transformationen ausgestattet, die ohne das Schreiben von Code konfiguriert werden können. Dadurch können sich Datenexperten darauf konzentrieren, Erkenntnisse aus den Daten abzuleiten, anstatt Zeit mit der Pipeline-Entwicklung zu verbringen.
- Einfache Anwendung: No-Code-Lösungen sind so konzipiert, dass sie auch für technisch nicht versierte Benutzer benutzerfreundlich sind. Sie verfügen oft über intuitive grafische Oberflächen, die es Benutzern ermöglichen, Datenpipelines über einen einfachen Drag-and-Drop-Mechanismus zu erstellen und zu verwalten. Dies demokratisiert den Prozess der Datenpipeline-Erstellung und ermöglicht es Geschäftsanalysten, Datenwissenschaftlern und anderen technisch nicht versierten Benutzern, ihre eigenen Pipelines zu erstellen, ohne Python oder eine andere Programmiersprache erlernen zu müssen.
- Verwaltungs- und Überwachungsfunktionen: No-Code-Lösungen umfassen typischerweise integrierte Funktionen zur Überwachung und Verwaltung von Datenpipelines. Dazu können Warnungen bei Pipeline-Ausfällen, Dashboards zur Überwachung der Pipeline-Leistung sowie Tools zur Versionierung und Bereitstellung von Pipelines gehören.
Nutzung Astera's No-Code Data Pipeline Builder
Eine solche No-Code-Lösung, die die Art und Weise verändert, wie Unternehmen mit ihren Daten umgehen, ist Astera. Diese fortschrittliche Datenintegrationsplattform bietet eine umfassende Suite von Funktionen, die darauf ausgelegt sind, Datenpipelines zu rationalisieren, Arbeitsabläufe zu automatisieren und die Datengenauigkeit sicherzustellen.
Hier ist ein Blick darauf, wie Astera sticht hervor:
- No-Code-Umgebung: AsteraMit der intuitiven Drag-and-Drop-Oberfläche können Benutzer Datenpipelines visuell entwerfen und verwalten. Diese benutzerfreundliche Umgebung verringert die Abhängigkeit von IT-Teams und ermöglicht technisch nicht versierten Benutzern, eine aktive Rolle bei der Datenverwaltung zu übernehmen, wodurch eine integrativere Datenkultur innerhalb der Organisation gefördert wird.
- Große Auswahl an Steckverbindern: Astera ist mit vorgefertigten Konnektoren für verschiedene Datenquellen und -ziele ausgestattet. Dazu gehören Konnektoren für Datenbanken wie SQL Server, Cloud-Anwendungen wie Salesforce und Dateiformate wie XML, JSON und Excel. Dadurch entfällt die Notwendigkeit einer komplexen Codierung zum Herstellen von Verbindungen, was den Datenintegrationsprozess vereinfacht.
- Vorgefertigte Transformationen: Astera bietet eine breite Palette von Datentransformationsfunktionen. Dazu gehören unter anderem Transformationen zum Zusammenführen, Routing und Pivotieren/Unpivotieren. Diese Vorgänge ermöglichen es Benutzern, Daten gemäß ihren Geschäftsanforderungen zu bereinigen, zu standardisieren und anzureichern und sicherzustellen, dass die Daten das richtige Format und die richtige Struktur für die Analyse haben.
- Datenqualitätssicherung: Astera bietet erweiterte Datenprofilierungs- und Datenqualitätsregeln. Benutzer können vordefinierte Regeln festlegen und Daten anhand dieser Regeln prüfen, um deren Genauigkeit und Zuverlässigkeit sicherzustellen. Diese Funktion trägt zur Wahrung der Datenintegrität bei und stellt sicher, dass Ihre Geschäftsentscheidungen auf qualitativ hochwertigen Daten basieren.
- Jobplanung und Automatisierung: Die Plattform ermöglicht es Benutzern, Aufträge zu planen und deren Fortschritt und Leistung zu überwachen. Benutzer können zeitbasierte oder ereignisbasierte Auslöser für Aufgaben einrichten, um den Datenpipeline-Prozess zu automatisieren und die rechtzeitige Ausführung von Datenjobs sicherzustellen.
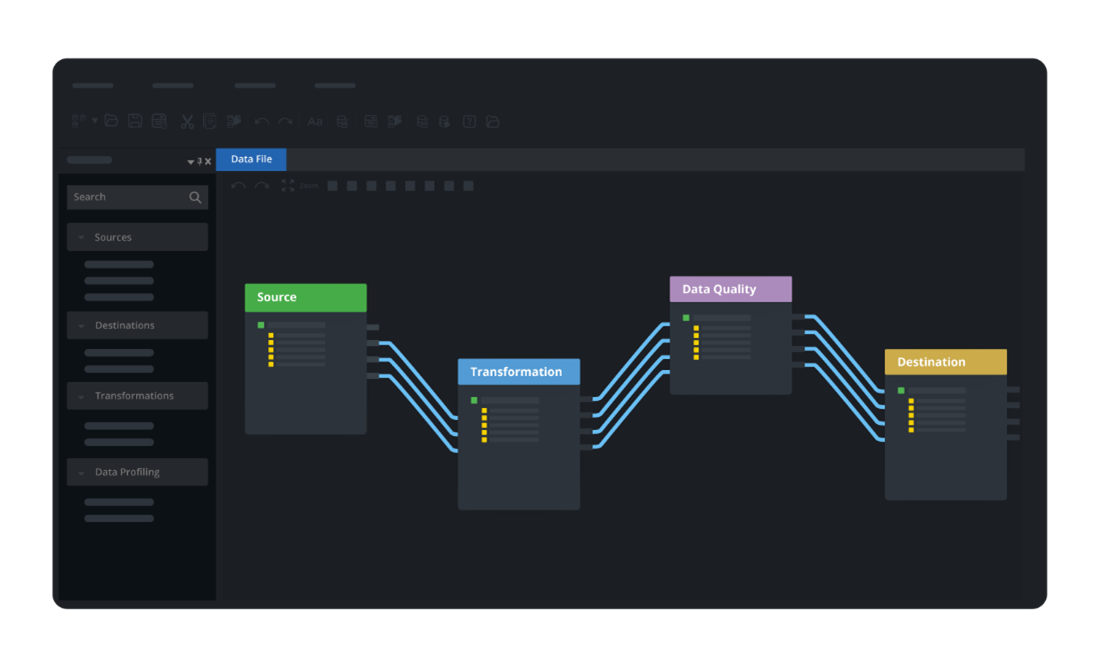
Asteraist die No-Code-Plattform
Machen Sie den ersten Schritt zu einem effizienten und zugänglichen Datenmanagement. Laden Sie Ihre 14-tägige kostenlose Testversion herunter Astera Datenpipeline-Builder und beginnen Sie mit dem Bau von Pipelines, ohne eine einzige Zeile Code zu schreiben!



