
Die automatisierte, Kein Code Datenstapel
Erfahren Sie, wie Astera Data Stack kann die Datenverwaltung Ihres Unternehmens vereinfachen und rationalisieren.

3 Möglichkeiten, Daten von Amazon S3 zu Redshift zu übertragen
Mit sozialen Medien, Sensoren und IoT-Geräten, die jedem Gerät Leben einhauchen, generieren wir täglich große Datenmengen. Mehr Daten sind immer eine gute Nachricht, bis Ihre Speicherrechnung zu steigen beginnt und es schwierig wird, sie zu verwalten. Unstrukturierte Daten werden voraussichtlich zunehmen 175 Milliarden Zettabyte bis 2025. Während Cloud-Dienste wie Amazon S3 es Unternehmen ermöglicht haben, diese riesigen Datenmengen bei der Analyse zu verwalten, reichen Speicherlösungen nicht aus, und hier kommt Data Warehouse wie Amazon Redshift ins Bild.
Unternehmen verwenden häufig beide Amazon-Dienste zusammen, um Kosten und Datenagilität zu verwalten, oder sie verwenden Amazon S3 als Staging-Bereich, während sie ein Data Warehouse auf Amazon Redshift aufbauen. Das wahre Potenzial beider Dienste können Sie jedoch nur ausschöpfen, wenn Sie eine nahtlose Verbindung von Amazon S3 zu Redshift erreichen. Astera Centerprise ist eine codefreie Lösung, mit der Sie beide Dienste problemlos integrieren können. Sehen wir uns einige Vorteile von AWS Redshift und Amazon S3 an und wie Sie sie problemlos verbinden können.
Erhöhen Sie die Abfragegeschwindigkeit mit AWS Redshift
AWS Redshift ist ein vollständig verwaltetes Cloud Data Warehouse, das auf AWS-Services bereitgestellt wird. Das Data Warehouse wurde für komplexe, großvolumige Analysen entwickelt und kann problemlos auf Petabytes an Daten skaliert werden. Es ermöglicht Ihnen, aussagekräftige Erkenntnisse aus Ihren Daten zu extrahieren, sodass Sie Ihre Entscheidungen nicht Ihrem Bauchgefühl überlassen.
Es gibt mehrere Gründe, warum AWS Redshift Ihrer Datenarchitektur einen echten Mehrwert verleihen kann:
- Als robustes Cloud Data Warehouse kann es große Datenmengen ohne nennenswerte Verzögerung abfragen.
- Mit einer Schnittstelle wie MYSQL ist das Data Warehouse benutzerfreundlich, was es einfacher macht, es Ihrer Datenarchitektur hinzuzufügen
- Da es sich in der Cloud befindet, können Sie es einfach nach oben und unten skalieren, ohne in Hardware zu investieren.
Obwohl AWS Redshift Ihre Datenanalyseanforderungen erfüllen kann, ist es keine ideale Lösung für die Speicherung, und das liegt hauptsächlich an seiner Preisstruktur. AWS Redshift berechnet Ihnen stündlich. Während die Kosten also klein anfangen, können sie schnell anschwellen.
Amazon S3 für die Speicherung
Wenn Sie an eine Ergänzung denken Amazon S3 mit Redshift, dann ist die einfache Antwort, dass Sie sollten. Amazon S3 ist eine schnelle, skalierbare und kosteneffiziente Speicheroption für Unternehmen. Als Objektspeicher ist er insbesondere eine perfekte Lösung für die Speicherung unstrukturierter Daten und historischer Daten.
Der Cloud-Speicher bietet eine Haltbarkeit von 99.9999 %, sodass Ihre Daten immer verfügbar und sicher sind. Ihre Daten werden zur Sicherung über mehrere Regionen hinweg repliziert, und die Zugriffspunkte für mehrere Regionen stellen sicher, dass beim Zugriff auf Daten keine Latenzprobleme auftreten. Darüber hinaus bietet S3 umfassende Speicherverwaltungsfunktionen, mit denen Sie Ihre Daten im Auge behalten können.
Techniken zum Verschieben von Daten von Amazon S3 zu Redshift
Es gibt einige Methoden, mit denen Sie Daten von Amazon S3 an Redshift senden können. Sie können integrierte Befehle nutzen und über AWS-Services senden, oder Sie können ein Drittanbieter-Tool wie z Astera Centerprise.
- COPY-Befehl: Der COPY-Befehl ist integriert in Rotverschiebung. Damit können Sie das Data Warehouse ohne weitere Tools mit anderen Quellen verbinden.
- AWS-Services: Es gibt mehrere AWS-Services wie AWS Glue und AWS Data Pipeline, die Ihnen bei der Datenübertragung helfen können.
- Astera Centerprise: Es ist ein End-to-End Datenintegration Plattform, die es Ihnen ermöglicht, Daten aus verschiedenen Quellen an beliebte Data Warehouses und Datenbankziele Ihrer Wahl zu senden, ohne eine einzige Codezeile schreiben zu müssen.
Kopierbefehl zum Verschieben von Daten von Amazon S3 nach Redshift
Amazon Redshift ist mit einer Option ausgestattet, mit der Sie Daten mit den Befehlen INSERT und COPY von Amazon S3 nach Redshift kopieren können. Der INSERT-Befehl ist besser, wenn Sie eine einzelne Zeile hinzufügen möchten. Der COPY-Befehl nutzt die parallele Verarbeitung, was ihn ideal zum Laden großer Datenmengen macht.
Sie können Daten auf folgende Weise über den COPY-Befehl an Redshift senden. Bevor Sie dies tun, müssen Sie jedoch eine Reihe von Schritten befolgen:
- Wenn Sie bereits über einen Cluster verfügen, laden Sie die Dateien auf Ihren Computer herunter.
- Erstellen Sie einen Bucket auf Amazon S3 und laden Sie dann Daten hinein.
- Tabellen erstellen.
- Führen Sie den COPY-Befehl aus.

Amazon Redshift COPY-Befehl
Das obige Bild zeigt einen grundlegenden Befehl. Sie müssen einen Tabellennamen, eine Spaltenliste, eine Datenquelle und Anmeldeinformationen angeben. Der Tabellenname im Befehl ist Ihre Zieltabelle. Die Spaltenliste gibt die Spalten an, denen Redshift Daten zuordnen wird. Dies ist ein optionaler Parameter. Datenquelle ist der Ort Ihrer Quelle; Dies ist ein Pflichtfeld. Sie müssen auch Sicherheitsanmeldeinformationen, Datenformat und Konvertierungsbefehle angeben. Der COPY-Befehl erlaubt nur einige Konvertierungen wie EXPLICIT_IDS, FILLRECORD, NULL AS, TIME FORMAT usw.
Das Verschieben von Daten von Amazon S3 nach Redshift durch diesen Prozess ist jedoch mit mehreren Einschränkungen verbunden. Der COPY-Befehl eignet sich am besten für Masseneinfügungen. Wenn Sie Daten einzeln hochladen möchten, ist dies nicht die beste Option.
Die zweite Einschränkung dieses Ansatzes besteht darin, dass Sie keine Transformationen auf die Datensätze anwenden können. Beachten Sie die Datentypkonvertierungen, die beim COPY-Befehl im Hintergrund stattfinden.
Der COPY-Befehl schränkt auch die Art der Datenquellen ein, die Sie übertragen können. Sie können nur JSON, AVRO und CSV übertragen.
Verschieben Sie Daten mit AWS Glue von Amazon S3 zu Redshift
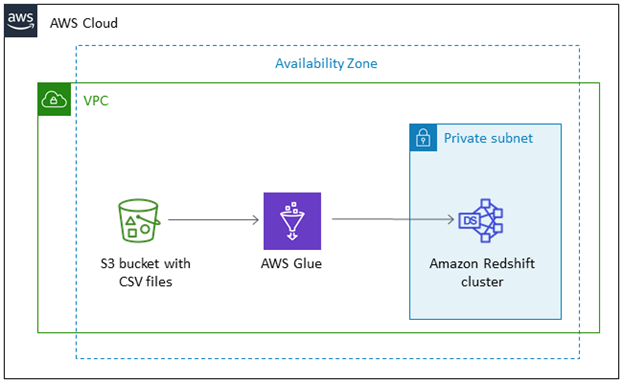
ETL-Daten mit AWS Glue
AWS Glue ist ein Server ETL-Tool von Amazon Web Services eingeführt, um Daten zwischen Amazon-Diensten zu verschieben. Sie können verwenden AWS-Kleber um Daten zu und von AWS Redshift zu verschieben. Das ETL-Tool verwendet COPY- und UNLOAD-Befehle, um einen maximalen Durchsatz zu erzielen. AWS Glue verwendet Amazon S3 als Staging-Phase, bevor es auf Redshift hochgeladen wird.
Bei der Verwendung von AWS Glue müssen Sie eines beachten. AWS Glue gibt temporäre Sicherheitsanmeldeinformationen weiter, wenn Sie einen Auftrag erstellen. Diese Anmeldeinformationen laufen nach einer Stunde ab und stoppen Ihre Jobs auf halbem Weg. Um dieses Problem zu beheben, müssen Sie eine separate IAM-Rolle erstellen, die dem Redshift-Cluster zugeordnet werden kann.
Sie können Daten mit AWS Glue auf folgende Weise übertragen:
- Starten Sie den AWS Redshift-Cluster.
- Erstellen Sie einen Datenbankbenutzer für die Migration.
- Erstellen Sie eine IAM-Rolle und gewähren Sie ihr Zugriff auf S3
- Hängen Sie die IAM-Rolle an das Datenbankziel an.
- Fügen Sie eine neue Datenbank in AWS Glue hinzu.
- Fügen Sie neue Tabellen in der AWS Glue-Datenbank hinzu.
- Geben Sie Amazon s3-Quellspeicherort und Details zur Tabellenspalte an.
- Erstellen Sie einen Auftrag in AWS Glue.
- Geben Sie die IAM-Rolle und Amazon S3 als Datenquellen in Parametern an.
- Wählen Sie die Option „Tabellen in Ihrem Datenziel erstellen“ und wählen Sie JDBC für den Datenspeicher.
- Führen Sie den AWS Glue-Job aus.
Während AWS Glue die Arbeit für Sie erledigen kann, müssen Sie die damit verbundenen Einschränkungen berücksichtigen. AWS Glue ist kein vollwertiges ETL-Tool. Außerdem müssen Sie Transformationen in Python oder Scala schreiben. AWS Glue erlaubt Ihnen auch nicht, Transformationen zu testen, ohne sie auf echten Daten auszuführen. AWS Glue unterstützt nur JSBC-Verbindungen und S3 (CSV).
Verschieben Sie Daten mit AWS Data Pipeline von Amazon S3 nach Redshift
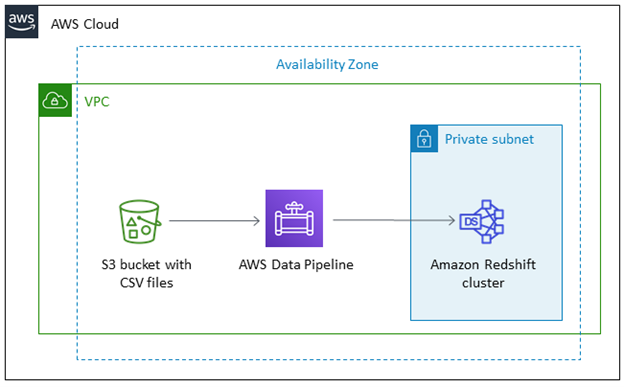
Senden Sie Daten mit AWS Data Pipeline an Amazon Redshift
AWS Data Pipeline ist ein speziell entwickelter Amazon-Service, mit dem Sie Daten zwischen anderen Amazon-Quellen sowie lokalen Quellen übertragen können. Mit Data Pipeline können Sie äußerst zuverlässige und fehlertolerante Datenpipelines erstellen.
Der Prozess enthält Datenknoten, in denen Ihre Daten gespeichert werden, die Aktivitäten, EMR-Jobs oder SQL-Abfragen und einen Zeitplan, wann Sie den Prozess ausführen möchten. Wenn Sie also beispielsweise Daten von Amazon S3 an Redshift senden möchten, müssen Sie:
- Deine Pipeline mit S3DataNode definieren,
- A Hive-Aktivität zum Konvertieren Ihrer Daten in .csv,
- RedshiftCopyActivity zum Kopieren Ihrer Daten von S3 nach Redshift.
So können Sie eine Datenpipeline erstellen:
- Erstellen Sie eine Pipeline. Es verwendet die Copy to Redshift-Vorlage in der AWS Data Pipeline-Konsole.
- Speichern und validieren Sie Ihre Datenpipeline. Sie können es während des Vorgangs jederzeit speichern. Das Tool gibt Ihnen Warnungen aus, wenn es Probleme in Ihrem Workload gibt.
- Aktivieren Sie Ihre Pipeline und überwachen Sie sie dann.
- Sie können Ihre Pipeline löschen, sobald die Übertragung abgeschlossen ist.
Verschieben Sie Daten von Amazon S3 zu Redshift mit Astera Centerprise
Astera Centerprise bietet Ihnen eine einfachere Möglichkeit, Daten von Amazon S3 an Redshift zu senden. Das codefreie Tool verfügt über eine native Konnektivität zu gängigen Datenbanken und Dateiformaten. Damit können Sie Daten von jeder Quelle an jedes Ziel senden, ohne eine einzige Codezeile schreiben zu müssen. Mit Astera Centerprise, alles, was Sie tun müssen, ist, die Konnektoren per Drag-and-Drop in den Datenpipeline-Designer zu ziehen, und Sie können im Handumdrehen mit dem Erstellen von Datenpipelines beginnen. Die Plattform wird auch mit Visual geliefert Datenmapping und eine intuitive Benutzeroberfläche, die Ihnen einen vollständigen Einblick in Ihre Datenpipelines gibt.
Verwendung von Amazon S3 als Staging-Bereich für Amazon Redshift
Wenn Sie Amazon S3 als Staging-Bereich verwenden, um Ihr Data Warehouse in Amazon Redshift zu erstellen, dann Astera Centerprise bietet Ihnen eine problemlose Möglichkeit, Daten in großen Mengen zu senden. So können Sie das tun:
- Ziehen Sie das Datenbankziel in den Datenpipeline-Designer und legen Sie es dort ab, wählen Sie Amazon Redshift aus dem Dropdown-Menü und geben Sie dann Ihre Anmeldeinformationen ein, um eine Verbindung herzustellen. Um Amazon S3 als Staging-Bereich zu verwenden, klicken Sie einfach auf die Option und geben Sie Ihre Anmeldeinformationen ein.
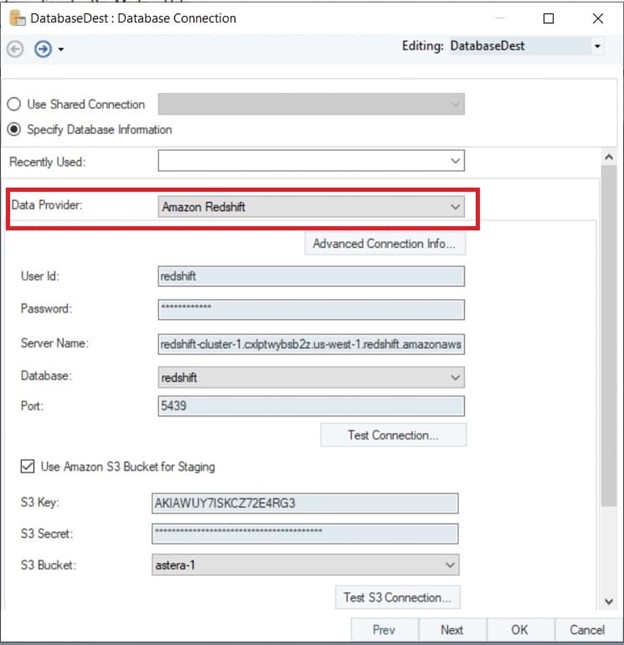
Verbinden mit Amazon Redshift in Astera Centerprise
- Anschließend können Sie auch die Größe der Beilage auswählen. Wenn Sie beispielsweise ein Excel mit einer Million Datensätzen haben, können Sie es an senden Amazon RedShift in Chargen von 10,000.
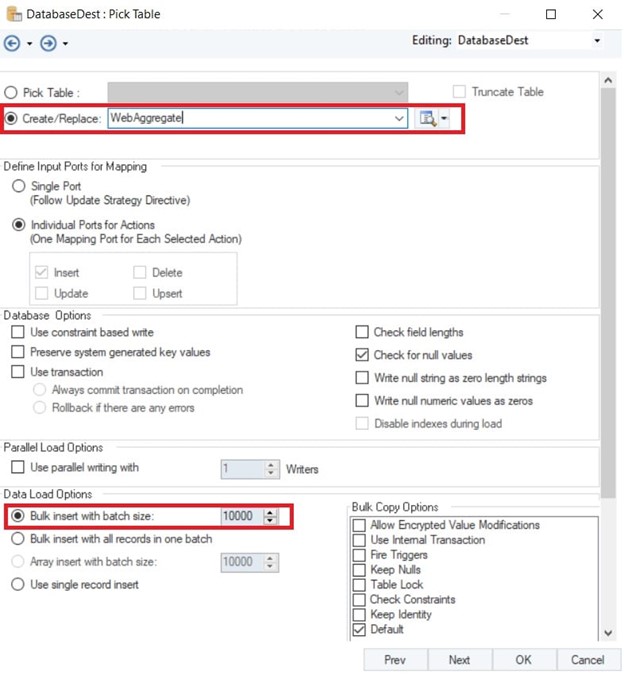
Auswählen der Stapelgröße für die Masseneinfügung in Amazon S3
Reichern Sie Ihre Daten an, bevor Sie sie von Amazon S3 an Redshift senden
Im Gegensatz zum COPY-Befehl Astera Centerprise ermöglicht es Ihnen, Ihre Daten zu massieren, bevor Sie sie an Amazon Redshift senden, und sorgt so für Robustheit Datenqualitätsmanagement. Astera Centerprise verfügt über integrierte, ausgeklügelte Transformationen, mit denen Sie Daten nach Belieben verarbeiten können. Ob Sie Ihre Daten sortieren, filtern oder Datenqualitätsregeln anwenden möchten, mit der umfangreichen Transformationsbibliothek können Sie dies tun.
Was macht Astera Centerprise die richtige Entscheidung?
Während es andere Alternativen gibt, einschließlich AWS-Tools, mit denen Sie Daten von Amazon S3 an Redshift senden können, Astera Centerprise bietet Ihnen den schnellsten und einfachsten Weg zur Überweisung. Das Codefreie Datenintegrationstool ist:
- Einfach zu bedienen: Es kommt mit einer minimalen Lernkurve, die es selbst Erstbenutzern ermöglicht, innerhalb von Minuten mit dem Aufbau von Datenpipelines zu beginnen
- Automatisiert: Mit den Job-Scheduling-Funktionen können Sie ganze Workflows basierend auf zeit- oder ereignisbasierten Triggern automatisieren.
- Datenqualität: Das Tool verfügt über mehrere sofort einsatzbereite Optionen zum Bereinigen, Validieren und Profilieren Ihrer Daten, um sicherzustellen, dass nur qualifizierte Daten das Ziel erreichen. Sie können den Builder für benutzerdefinierte Ausdrücke auch verwenden, um Ihre eigenen Regeln zu definieren.
Möchten Sie Daten von Amazon S3 auf Redshift laden? Los geht´s mit Astera Centerprise



