
L'automatisé, Pas de code Pile de données
Apprener comment Astera Data Stack peut simplifier et rationaliser la gestion des données de votre entreprise.

Voici pourquoi vous avez besoin d'un extracteur de PDF
Un logiciel d'extraction de PDF peut vous aider à convertir des données non structurées dans des fichiers PDF en données propres et structurées pouvant être stockées dans un entrepôt de données à des fins de reporting et de business intelligence. La Fichiers au format de document portable (PDF) sont faciles à partager et à consulter, et ils conservent leur intégrité sur toutes les plates-formes (Windows, macOS, Linux, etc.). Par conséquent, ils constituent une grande partie des factures de vente, des documents juridiques et d'autres documents commerciaux officiels dans l'arène de l'entreprise. .
Malgré le fait que les formats de fichiers PDF contiennent d'excellentes informations commerciales, ils ne sont pas idéalement configurés pour les rapports et l'analyse, c'est-à-dire qu'il s'agit de fichiers non structurés. Des outils d'extraction de données sont donc nécessaires pour transformer ces documents en générateurs d'informations.
Extraction de données à partir de PDF
L'extraction de données à partir de fichiers PDF fait partie intégrante du flux de travail de gestion des données. Il permet aux organisations de transformer le texte brut et non structuré des documents en données structurées afin de maintenir un référentiel de données centralisé pour le reporting et l'analyse. Cependant, ce n'est pas une promenade dans le parc car les données des fichiers PDF ne sont pas structurées, c'est-à-dire soigneusement organisées en colonnes et en lignes. Les extracteurs de PDF utilisent des images numérisées des pages du fichier et effectuent une reconnaissance optique des caractères pour en extraire le texte.
Extraction de données à partir de PDF : quelles sont vos options ?
En ce qui concerne l'extraction de données à partir de documents PDF, le premier réflexe consiste simplement à saisir manuellement les données dans les systèmes. C'est bien si vous avez quelques documents. Mais lors du traitement quotidien de centaines et de milliers de fichiers, cela devient une option beaucoup moins viable, même pour les entreprises de taille moyenne.
Comparons la saisie manuelle des données avec certaines des autres options disponibles pour l'extraction de données à partir de documents PDF :
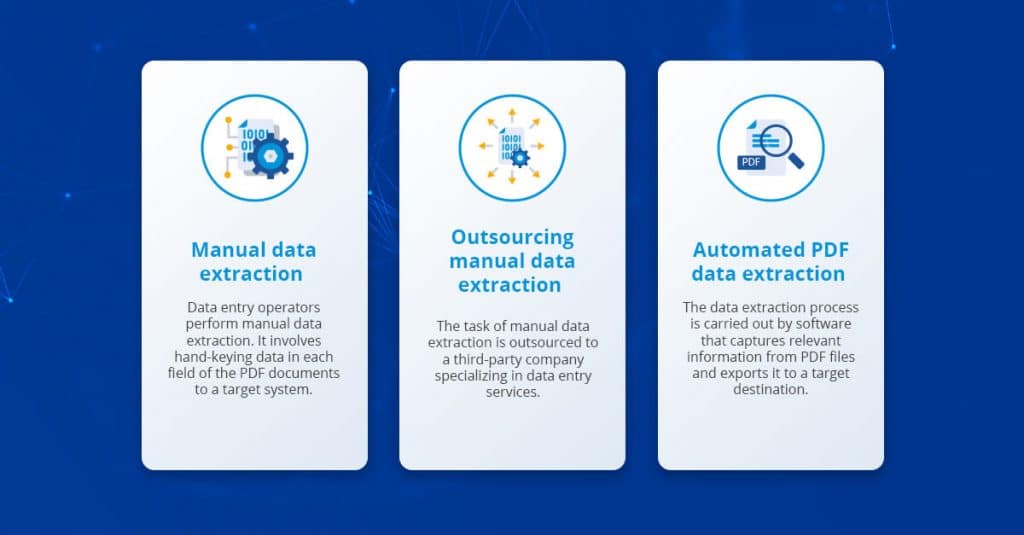
- L'extraction manuelle des données est coûteuse, répétitive et chronophage. C'est une option peu pratique pour le traitement de gros volumes de données. Il est également sujet aux erreurs humaines, qui affectent la qualité des données.
- L'externalisation peut minimiser les coûts et la vitesse d'extraction des données dans une certaine mesure ; cependant, cela pose de sérieux problèmes de sécurité des données et de contrôle de la qualité qui compensent ces avantages.
- L'extraction automatisée des données est le moyen le plus rapide et le plus efficace de capturer des données à partir de fichiers PDF. Les extracteurs PDF modernes peuvent traiter des milliers de documents en quelques secondes.
Extraction de données centrée sur l'IA par rapport à l'extraction de données basée sur des modèles
Il existe essentiellement deux approches de l'extraction de données : l'extraction centrée sur l'IA et l'extraction de données basée sur des modèles.
Extraction de données centrée sur l'IA
L'extraction de données centrée sur l'IA est une nouvelle approche dans laquelle des algorithmes d'apprentissage automatique et d'apprentissage en profondeur sont utilisés pour établir des relations entre des ensembles de données et des documents numérisés. Les scientifiques des données forment des modèles pour reconnaître les noms clés des champs clés des données d'entreprise en fonction de la saisie de l'utilisateur, les étiqueter, puis capturer le texte pertinent à partir du document non structuré.
Cette approche offre polyvalence et évolutivité aux entreprises et fonctionne parfaitement pour l'IA conversationnelle, où une compréhensibilité et des réponses en temps réel sont requises. Par exemple, les chatbots formés peuvent répondre très rapidement aux requêtes anticipées des clients. De plus, les entreprises peuvent minimiser le temps de réponse avec des réponses contextuelles.
Cependant, le processus d'extraction de données centré sur l'IA nécessite une formation considérable sur les ensembles de données et des compétences en apprentissage automatique, car les modèles doivent être formés pour comprendre les ambiguïtés, le contexte et plusieurs aspects complexes liés à la détection de la langue.
Un modélisateur de données doit déterminer le bon volume de données requis pour former chaque modèle afin de garantir que la précision et la qualité de la sortie algorithmique répondent aux exigences de l'entreprise. Lorsqu'il est mal conçu ou mis en œuvre, ce processus peut entraîner des données de mauvaise qualité à partir de fichiers texte.
Extraction de données basée sur un modèle
L'extraction de données basée sur des modèles est une approche éprouvée pour traiter des documents PDF numérisés à grande échelle. Cela implique la création d'un modèle d'extraction de données pour isoler des sections de texte spécifiques dans le document. Le modèle est spécifié en utilisant la position et la proximité du texte dans le document.
Par exemple, un utilisateur peut spécifier un modèle ou plusieurs modèles pour extraire des données d'une région spécifiée d'un document PDF. Le modèle rechercherait le ou les modèles avec une combinaison spécifique d'alphabets, de mots, de caractères numériques ou alphanumériques spécifiés par l'utilisateur pour capturer des informations.
Il nécessite une capacité de calcul relativement faible par rapport à son homologue centré sur l'IA et offre une plus grande précision. En outre, les modèles peuvent être réutilisés pour des documents PDF de structure similaire, ce qui accélère l'extraction des données. Cette évolutivité est particulièrement utile lors de l'extraction de données à partir de gros volumes de fichiers PDF.
Cela dit, l'extraction de données basée sur des modèles présente également certains défis. Par exemple, un document PDF peut contenir un champ flottant, c'est-à-dire que l'emplacement du champ d'une seule ligne est différent du reste des lignes. Dans certains cas, une colonne est mal alignée en raison de la déformation des données.
Les solutions modernes d'extraction de données basées sur des modèles sont conçues pour relever ces défis et créer tous les modèles possibles pour une capture de données transparente à partir de fichiers PDF et d'autres fichiers non structurés.
Fonctionnalités clés à rechercher dans un extracteur de PDF
Les exigences d'extraction de données des organisations diffèrent d'un cas d'utilisation à l'autre. Voici quelques-unes des principales fonctionnalités indispensables d'un extracteur de PDF :
- Connecteurs vers diverses sources de données et destinations
- Capacités d'automatisation
- Orchestration des flux de travail
- Environnement zéro code
- Interface utilisateur intuitive et facile à apprendre
Astera ReportMiner — L'extracteur de PDF automatisé et sans code
Astera ReportMiner est un extracteur de PDF de niveau entreprise qui automatise et simplifie le traitement des documents non structurés. Son interface utilisateur intuitive et facile à apprendre permet aux utilisateurs professionnels de extraire des informations précieuses à partir de documents PDF. Les utilisateurs peuvent créer des règles de qualité des données personnalisées pour valider les données extraites des fichiers PDF.
Principales caractéristiques de Astera ReportMiner

Extraction automatisée des données : exemples de réussite par Astera Software
Au fil des ans, Astera ReportMiner a aidé de nombreuses organisations à gagner du temps en automatisant les activités d'extraction de données. Voici quelques exemples de réussite de clients utilisant notre extracteur de PDF :
Traitement plus rapide des données de gestion des demandes de remboursement PDF pour un demandeur
Aclaimant, un fournisseur de systèmes avancés de réduction des risques et de gestion des incidents, utilise Astera ReportMiner pour extraire rapidement des pages de fichiers PDF. Il utilise ReportMiner pour capturer les données des formulaires de réclamation au format PDF et les écrire dans des rapports Excel et CSV. Cela a entraîné une réduction de 50 % du temps et des ressources consacrés à la transcription manuelle des formulaires de réclamation.
Lire l'étude de cas complète ici.
Extraction automatisée de données PDF pour un prestataire de services informatiques d'une organisation gouvernementale
Astera ReportMiner permet à un prestataire de services informatiques qui gère les informations d'historique de travail du personnel gouvernemental de simplifier l'extraction de données PDF et de minimiser les erreurs, économisant ainsi plus de 1000 XNUMX heures manuelles par an.
Lire l'étude de cas complète ici.
Extraction de données à partir de PDF de bons de commande client en quelques minutes pour Ciena Corporation
Ciena Corporation, un fournisseur de services, de logiciels et d'équipements de mise en réseau, utilise Astera ReportMiner pour extraire les données clés des PDF des bons de commande des clients en seulement 2 minutes au lieu de plusieurs heures. L'entreprise est désormais en mesure de répondre aux demandes des clients 15 fois plus rapidement.
Lire l'étude de cas complète ici.
Extraire des données en quelques étapes simples
Astera ReportMiner est un extracteur de PDF doté d'une interface utilisateur intuitive et sans code avec des fonctionnalités avancées pour capturer des données à partir de fichiers PDF.
1) Importer un fichier PDF
Téléchargez un PDF à partir de votre répertoire local ou partagé. Le texte des pages PDF s'affichera sur le concepteur du modèle de rapport.
*ReportMiner prend en charge divers types de fichiers, notamment Excel, RTF, PRN, EDI, etc.
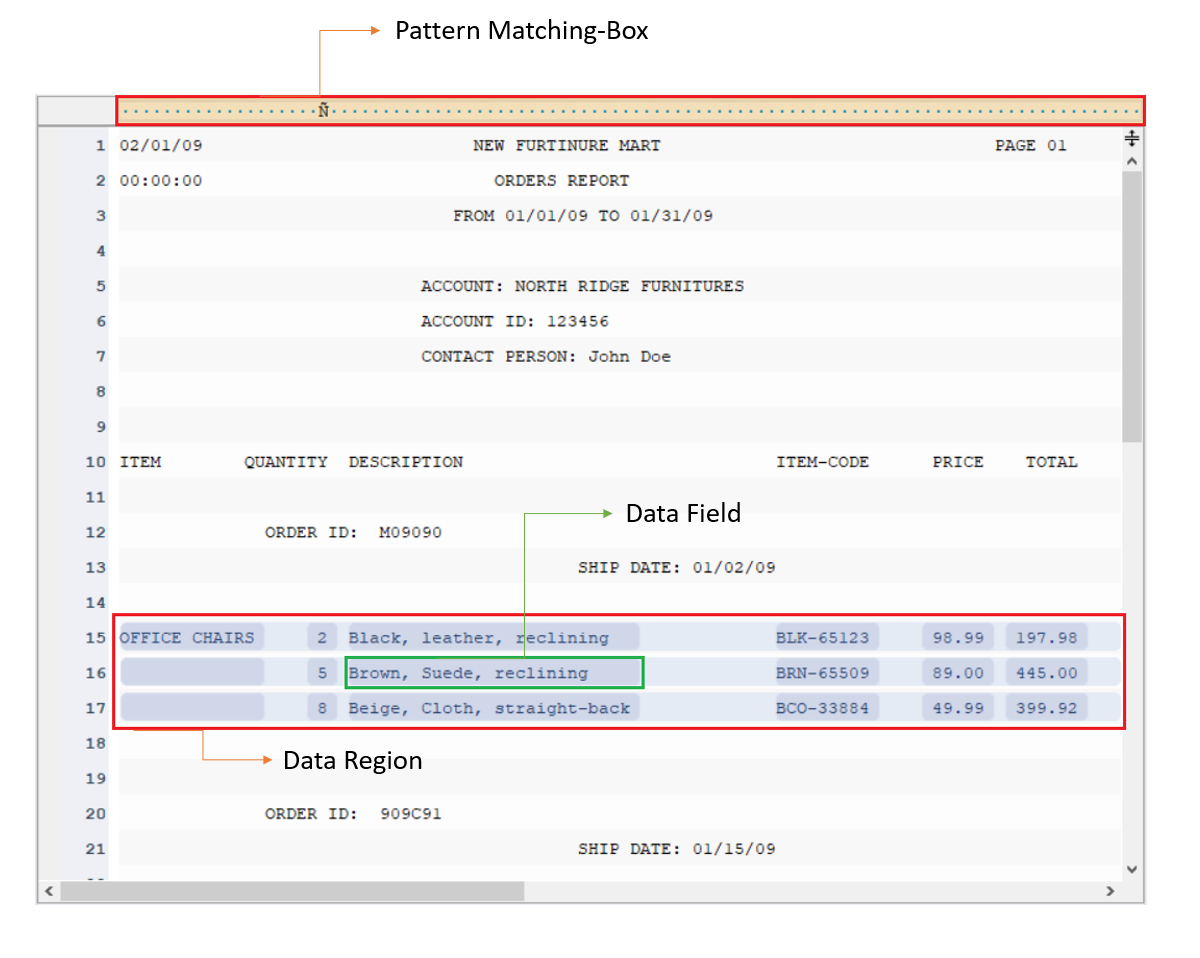
2) Créer un modèle de rapport
À l'aide des panneaux de propriétés de boîte de modèle et de région, créez un modèle de rapport en sélectionnant les jeux de données et les pages à extraire et en spécifiant un modèle dans un environnement intuitif sans code.

Spécifiez le modèle de correspondance des régions pour les jeux de données dans les pages que vous souhaitez extraire du fichier PDF. Répétez le processus pour créer plus de champs de données afin de capturer toutes les informations pertinentes dans le document.
Le modèle d'extraction vous donne un contrôle total sur le processus d'extraction des données. Même si vous avez un document de plusieurs pages, vous pouvez capturer des informations pertinentes à partir de pages spécifiques ou d'une partie de celui-ci.
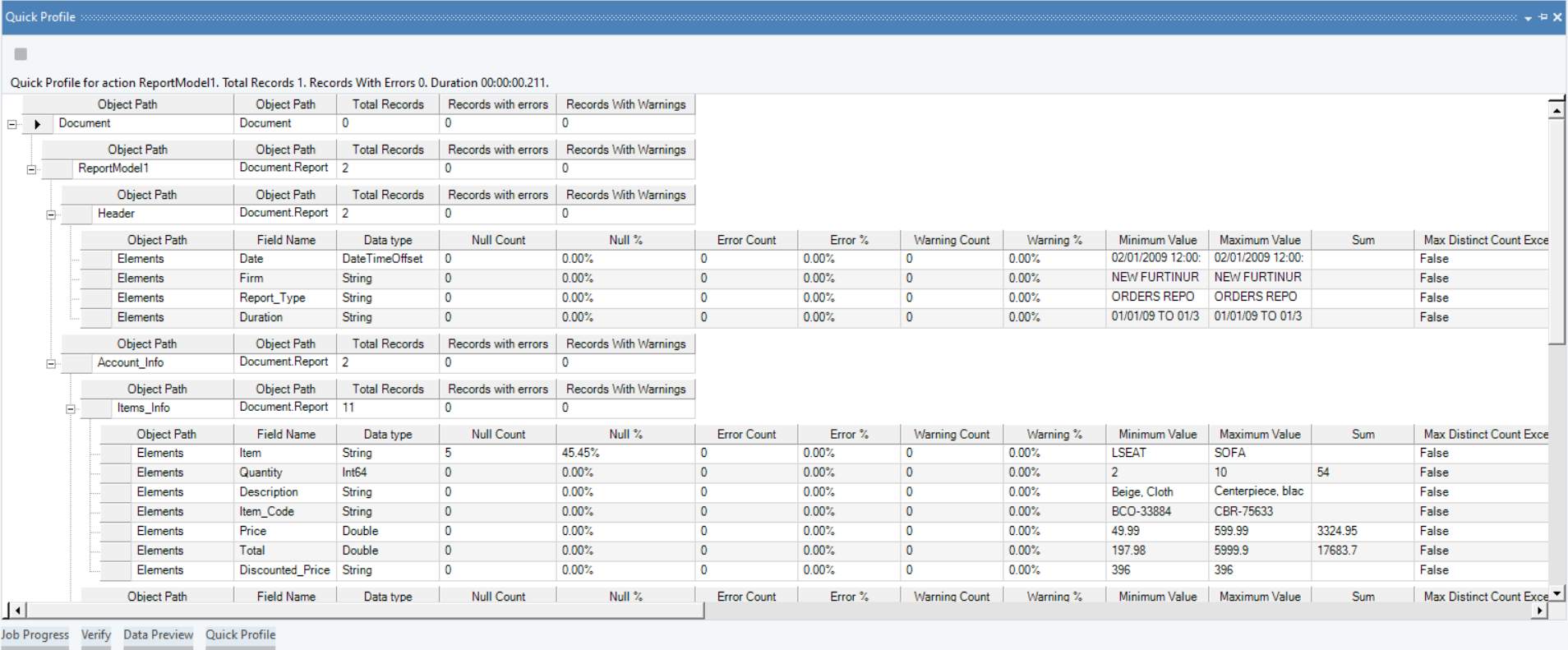
Une fois les données extraites, vous pouvez utiliser la fonction de prévisualisation des données pour garantir l'exactitude et l'exhaustivité des informations.
3) Exporter les données vers la destination
Vous pouvez exporter les données extraites à partir de fichiers PDF vers un fichier Excel, CSV ou toute base de données de votre choix, que ce soit sur site ou sur le cloud. Vous pouvez également ouvrir le modèle de rapport dans un flux de données pour nettoyer les données et appliquer des transformations avant de l'exporter vers votre destination cible.
Et tu as fini. En quelques étapes simples, vous structurez de manière transparente les données non structurées piégées dans les documents commerciaux PDF.
Si vous recherchez un outil d'extraction de données PDF intelligent et intuitif, download un essai gratuit de 14 jours de notre solution d'extraction de données automatisée dès aujourd'hui ou appelez le +1 888-77-ASTERA pour discuter de votre cas d'utilisation.



