
Die automatisierte, Kein Code Datenstapel
Erfahren Sie, wie Astera Data Stack kann die Datenverwaltung Ihres Unternehmens vereinfachen und rationalisieren.

Traditioneller Ansatz im Vergleich zu metadatengesteuertem Data Warehousing

Von monolithischen Managementinformationssystemen bis hin zu dimensional modellierten Data Warehouses und Data Lakes haben wir im Laufe der Jahre massive Veränderungen in der Art und Weise festgestellt, wie Unternehmen ihre Daten sammeln, verarbeiten, speichern und analysieren. Jeder technologische und technologische Sprung wurde von der bewussten Anstrengung geleitet, ihre Berichterstellung und Analyse flexibler, zugänglicher und skalierbarer zu gestalten.
Zu Recht müssen Unternehmen in einer Betriebsumgebung, in der sich Kundenpräferenzen und die vorherrschenden Marktbedingungen sofort ändern können, Daten häufig innerhalb von Stunden visualisieren und abfragen, um diesen entscheidenden Vorteil gegenüber Wettbewerbern zu erzielen. Eine agile Datenarchitektur ist unerlässlich, um dieses Ziel zu erreichen.
Geben Sie die metadatengesteuerter Ansatz. Mit Astera Mit DW Builder können Sie umfassende Datenmodelle erstellen, die das Design, die Logik und die zugehörigen Daten integrieren Datenzuordnungen Diese machen den Großteil der Data Warehouse-Entwicklung aus und replizieren dann das gesamte Schema in einer Cloud oder einer lokalen Datenbank Ihrer Wahl. Von dort aus können Sie Ihr Data Warehouse problemlos füllen, nutzen oder aktualisieren.
Am Ende des Tages haben Sie einen schnellen und reaktionsschnellen Prozess, der entwickelt wurde, um umsetzbare Erkenntnisse gemäß Ihrem Zeitplan zu liefern. Vergleichen Sie unseren Ansatz mit früher, und Sie werden die Vorteile von Metadaten und den enormen Wert sehen, den unser Produkt für den Entwicklungsprozess bringt.
Warum sich Data Warehousing weiterentwickeln muss
Der traditionelle Ansatz

Wenn wir über das reden traditioneller AnsatzWir beziehen uns auf die Entwicklung im Wasserfallstil, die diesen Raum seit den 90er Jahren dominiert. In diesem Prozess wird das Data Warehouse in einer sorgfältig geplanten Abfolge von Phasen erstellt, die wie folgt aussehen:
- Anforderungserfassung: In dieser Phase treffen sich die Entwickler mit Geschäftsanalysten und anderen Endbenutzern, um zu dokumentieren, welche Art von BI erforderlich ist.
- Design: Nach dem Studium der Anforderungen entwerfen die Entwickler eine Prototyparchitektur, die die physische / logische Struktur und die Datenzuordnungen umfasst, die zum Auffüllen und Verwalten erforderlich sind
- Barrierefreiheit erstellen: Entwickler müssen dann entscheiden, wie auf die Lagerdaten für die Berichterstellung und Analyse zugegriffen werden soll. Daten können über eine Front-End-BI-Plattform wie PowerBI oder Tableau oder eine benutzerdefinierte Lösung verfügbar gemacht werden, die auf die Anforderungen des Unternehmens zugeschnitten ist.
- Testing: Umfasst sowohl einen QS-Teil, um Fehler zu identifizieren und zu beheben, die die Benutzerfreundlichkeit / Leistung beeinträchtigen könnten. Ebenso wie Benutzerakzeptanztests, um sicherzustellen, dass das Data Warehouse seinen angegebenen Zweck erfüllt.
Ihr Data Warehouse ist kein Projekt. Es ist ein Prozess.
Die wichtigste Einschränkung des Wasserfallansatzes besteht darin, dass die Entwicklung auf eine fertige Lösung ausgerichtet ist, die als Antwort auf alle BI-Anforderungen des Unternehmens präsentiert wird. Dieser Big-Ticket-Ansatz berücksichtigt nicht die sich ständig ändernde Natur dieser Bedürfnisse.
- Während die Geschäftsanforderungen auf der Grundlage der aktuellen Bedürfnisse der Endbenutzer erfasst werden, müssen sie auch alle möglichen Szenarien umfassen, die sich in Monaten oder sogar Jahren entwickeln könnten. Natürlich ist es leichter gesagt als getan, den zukünftigen Zustand Ihres Unternehmens vorherzusagen.
- Da es im gesamten Entwicklungsprozess so viele Übergaben von Geschäftsanalysten an Entwickler, Architekten und ETL-Spezialisten gibt, besteht immer die Möglichkeit, dass Anforderungen falsch interpretiert werden. Infolgedessen könnte die fertige Lösung weit von dem entfernt sein, was ursprünglich vereinbart wurde, d. H. Chinesisches Flüstern
- Es besteht auch die eindeutige Möglichkeit, dass Endbenutzer ihre Anforderungen überhaupt nicht verstanden haben. Sie haben möglicherweise die Daten unterschätzt, die integriert werden müssen.
- Da die meisten dieser Probleme erst in der Testphase festgestellt werden, erhöhen Korrekturen natürlich die Kosten und den Zeitrahmen des Projekts.
Okay, aber was macht den metadatengesteuerten Ansatz besser?
Beginnen wir mit dem, was wir unter dem metadatengesteuerten Ansatz verstehen, denn die Behandlung von Data Warehouse-Entwicklungen hat viele Facetten Astera DW-Builder.
Alles beginnt mit dem Datenmodell
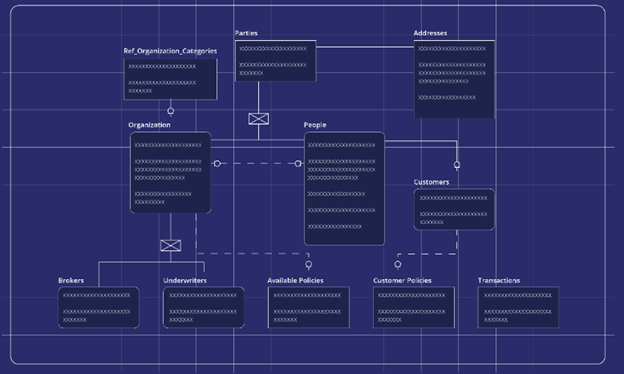
Das erste, was zu beachten ist, ist, dass wir setzen Datenmodellierung ganz vorne und in der Mitte unseres Produkts. Unser umfassender, codefreier Datenmodelldesigner ermöglicht es Benutzern, jedes Element ihrer EDW in einem einzigen End-to-End-Prozess zu entwerfen. Dadurch werden sofort die sequentiellen Übergaben entfernt, die den Wasserfallansatz charakterisieren. Stattdessen haben Sie einen nahtlosen Entwurfsprozess, der von einer einzelnen Person initiiert und verwaltet werden kann (falls erforderlich).
Möglicherweise möchten Sie technische und nichttechnische Benutzer in die Erstellung Ihrer Datenmodelle einbeziehen, und ETL-Flows in der Praxis. Diese Art der Zusammenarbeit wird in unserem Produkt uneingeschränkt unterstützt, da alle zum Entwerfen eines Datenmodells erforderlichen Elemente auf Metadatenebene verwaltet und konfiguriert werden. Unabhängig davon, ob Sie Ihre Quellsystementitäten modellieren oder einzelne Fakten- und Dimensionstabellen einrichten, ist all dies möglich, indem Sie mithilfe geschäftsdefinierter Konzepte direkt mit dem Datenmodell interagieren.
Der große Vorteil hierbei ist, dass der Endbenutzer seine konzeptionellen Anforderungen tatsächlich in ein physisches Datenmodell übersetzen kann. In diesem Fall werden alle Entitätsbeziehungen, Geschäftsregeln und Namenskonventionen während der Entwurfsphase vereinbart - und nicht am Ende geklärt, wenn ein Prototyp tatsächlich präsentiert wird. Ein weiterer wesentlicher Vorteil besteht darin, dass der Endbenutzer beim Erstellen des Modells sofort Feedback zu erforderlichen Korrekturen geben oder seine anfänglichen Anforderungen basierend auf dem Arbeitsdesign des Data Warehouse anpassen kann.
Das Ergebnis ist ein fertiges Datenmodell, das auf die Anforderungen des Unternehmens abgestimmt ist.
Arbeiten Sie iterativ, um die BI-Anforderungen zu erfüllen

Lassen Sie uns an dieser Stelle darüber sprechen agile Entwicklung und wie es sich vom Wasserfallansatz unterscheidet. In dieser Methodik werden einige grundlegende Werte geschätzt - die Zusammenarbeit (die wir behandelt haben), die Priorisierung funktionaler Software gegenüber der präzisen Dokumentation und die Fähigkeit, schnell auf sich ändernde Anforderungen anstatt auf einen festgelegten Plan zu reagieren.
Die beiden letztgenannten Punkte sind entscheidend, wenn diskutiert wird, wie der metadatengesteuerte Ansatz die Data Warehouse-Entwicklung verbessert. Wir haben darauf hingewiesen, wie schwierig es ist, eine präzise Dokumentation zu erstellen, die genau vorhersagt, wie hoch Ihre BI-Anforderungen in einem Jahr oder noch länger sein werden. Warum also nicht sofort mit der Arbeit an einer kleineren Bereitstellung beginnen, die den aktuellen Geschäftsanforderungen entspricht?
Mit der Astera Mit DW Builder können Sie Ihrem Data Warehouse diese Art von Agilität hinzufügen. Sobald eine dringende Anforderung erkannt wurde, kann Ihr Team ein Datenmodell erstellen, das die zugrunde liegenden Betriebssysteme widerspiegelt, die analysiert werden müssen, sowie ein Schema für das Data Warehouse, das zum Abfragen dieser Systeme verwendet wird. Insgesamt kann der Vorgang in wenigen Tagen oder sogar Stunden abgeschlossen werden. Am Ende verfügen Sie über eine funktionale Architektur, die sofort umsetzbare Erkenntnisse für Ihre Front-End-Anwendungen liefert.
Wenn sich diese Anforderungen ändern, können Sie natürlich entweder Ihre vorhandenen Modelle ändern, indem Sie Ihrem Datenmodell neue Entitäten oder Felder hinzufügen. Oder Sie können ein völlig neues Datenmodell für einen anderen Geschäftsprozess erstellen, das eingehend untersucht werden muss. Mit einem agilen Ansatz erhalten Sie einen iterativen Entwicklungsprozess, der sich ideal für ein sich schnell änderndes Geschäftsumfeld eignet.
Verabschieden Sie sich von der Handcodierung

ETL ist im Allgemeinen der zeitaufwändigste Teil der Data Warehouse-Entwicklung, da Entwickler sicherstellen müssen, dass alle in die EDW geladenen Daten frei von Duplikaten oder anderen Problemen mit der Datenqualität sind und die Ladezeiten nach Möglichkeit minimiert werden. In der Regel erfordert der Prozess einen erheblichen manuellen Aufwand, da Entwickler ihren Code von Grund auf neu schreiben, um ihn an die Details jeder Datenpipeline anzupassen.
ADWB wird mit einer Datenflusskomponente geliefert, mit der Sie diese Zuordnungen von Quelle zu Data Warehouse auf Metadatenebene entwerfen können. Beginnen Sie mit einer Reihe von sofort einsatzbereiten Konnektoren, mit denen Sie problemlos Daten aus Flatfile-Systemen und APIs in vorhandene Quellsystemschemata abrufen können, die mit unserem Datenmodell-Designer erstellt wurden.
Diese letzte Funktionalität ist wichtig, da keine Daten mehr direkt von Ihren Betriebssystemen abgerufen werden müssen, wodurch wertvolle Rechenressourcen auf kritischen Datenbankservern verbraucht werden. Es schafft auch eine zusätzliche Sicherheitsebene zwischen Ihren Transaktionsdaten und dem Endbenutzer, da Sie Ihre Datenmodelle so erstellen können, dass sie analysebereite Tabellen und Datensätze widerspiegeln. Unser Produkt verfügt außerdem über einen speziellen Builder für Datenmodellabfragen, mit dem Sie eine hierarchische Quellentabelle erstellen können, die mehrere Datenmodellentitäten enthält, die auf vorhandenen Beziehungen basieren, die in der Modellierungsphase definiert wurden. Auch diese komplexe Abfrageerstellung erfordert kein tatsächliches SQL. Relevante Entitäten werden auf Metadatenebene ausgewählt und konfiguriert.
Das Produkt bietet Ihnen auch Informationen zur Aufbereitung und Anreicherung Ihrer Quelldaten. Der Dataflow Builder bietet über hundert integrierte Transformationen, mit denen Sie alle Daten, die in Ihr Data Warehouse verschoben werden, bereinigen, filtern, ersetzen, analysieren und validieren können. So können Sie sicherstellen, dass nur qualitativ hochwertige, analysebereite Daten in Ihre BI-Architektur gelangen.
Die Datenzuordnung wird durch dedizierte Fakt- und Dimensionslader weiter beschleunigt, die zeitintensives Staging und komplexe Dimensionssuchvorgänge (in historischen Datensätzen werden beibehalten) auf einfache Drag-and-Drop-Zuordnung reduzieren. Verbinden Sie einfach die Zieltabelle mit der relevanten Entität in Ihrem Dimensionsmodell, und schon kann es losgehen.
Sobald Sie mit dem Entwerfen von End-to-End-Datenzuordnungen fertig sind, können Sie den Datenfluss ausführen. Unsere ETL-Engine liest die Metadaten und generiert automatisch den erforderlichen Code, um Daten von der Quelle zum Ziel zu bringen. Wir bieten sogar Planungs- und Workflow-Orchestrierungsfunktionen an, mit denen Sie diese Vorgänge gemäß Ihren Anforderungen automatisieren können.
Vor der Bereitstellung gleichzeitig testen

Mit ADWB haben wir fortlaufende Tests in die Architektur der Plattform integriert. Bevor Sie eines Ihrer Datenmodelle bereitstellen, müssen Sie das Design überprüfen, um sicherzustellen, dass jede Entität korrekt konfiguriert ist und keine leeren Felder oder inkonsistenten Werte vorhanden sind. Mit gleichzeitigen Tests können Sie Fehler in Ihrem Build schnell identifizieren und korrigieren, bevor sie Probleme für den Endbenutzer verursachen.
In ähnlicher Weise haben wir Echtzeitprotokollierung und Fehlerbenachrichtigungen während der Datenflussausführung implementiert, sodass Probleme in Ihren ETL-Prozessen in den Metadaten erkannt werden können. Das Ergebnis ist eine stressgeprüfte Architektur, die selbst die komplexesten BI-Anwendungsfälle problemlos bewältigen kann.
Replizieren Sie Ihr Schema in einer beliebigen führenden Datenbank.

Da Datenmodelle auf Metadatenebene erstellt werden, sind sie nicht für die Integration in eine bestimmte Plattform fest codiert. Im Wesentlichen haben Sie ein plattformunabhängiges Schema erstellt, das problemlos in jede Zieldatenbank repliziert werden kann. Um es noch einfacher zu machen, unterstützen wir führende lokale und Cloud Data Warehouses, sodass Sie Ihr Data Warehouse auf der Infrastruktur aufbauen können, die Ihren BI-Anforderungen am besten entspricht.
Sie möchten die Skalierbarkeit und Leistung von nutzen Amazon RedShiftStellen Sie eine Verbindung zur Datenbank her und leiten Sie den Techniker weiter. Möchten Sie Ihre Berichterstattung intern halten? Wählen Sie einen lokalen Anbieter wie SQL Server oder Oracle Database aus - Sie haben die Wahl.
Vergleichen Sie diesen Prozess mit den im Wasserfall bevorzugten Big-Ticket-Implementierungen, bei denen Aktualisierungen oder Änderungen eine weitere End-to-End-Entwicklungsrunde erfordern und klar ist, welche Methode für moderne BI besser geeignet ist.
Erleben Sie metadatengesteuertes Data Warehousing mit Astera DW-Builder
Möchten Sie von unserer spannenden neuen Data Warehousing-Lösung profitieren? Melden Sie sich mit unseren Experten, um mehr darüber zu erfahren, wie unsere metadatengesteuerte Architektur Ihnen dabei helfen kann, die gewünschten Ergebnisse zu erzielen oder für eine personalisierte Demo für Ihren speziellen Anwendungsfall.



