

Автоматизированный, Без кода Стек данных
Научиться Astera Data Stack может упростить и оптимизировать управление данными вашего предприятия.
Что такое архитектура хранилища данных?
В течение последних нескольких десятилетий архитектура хранилища данных была основой корпоративных экосистем данных. И несмотря на многочисленные изменения за последние пять лет в сфере больших данных, облачных вычислений, прогнозного анализа и информационных технологий, хранилища данных только приобрели еще большее значение.
Сегодня важность хранилище данных нельзя отрицать, и сейчас доступно больше возможностей для хранения, анализа и индексации данных, чем когда-либо.
В этой статье будут обсуждаться различные базовые концепции архитектуры корпоративного хранилища данных, различные модели корпоративного хранилища данных (EDW), их характеристики и важные компоненты, а также исследоваться основная цель хранилища данных в современных отраслях.
Теории архитектуры хранилищ данных
Чтобы понять архитектуру хранилища данных, важно знать о Ральфе Кимбалле и Билле Инмоне, двух выдающихся фигурах в области хранилищ данных. Эти двое предложили разные подходы к проектированию архитектур хранилищ данных.
Подход Кимбалла
Ральф Кимбалл известен своим размерное моделирование подход, который фокусируется на доставке данных способом, оптимизированным для запросов и отчетов конечного пользователя. Подход Кимбалла фокусируется на создании хранилищ данных с использованием структур звездообразной схемы, где центральная таблица фактов содержит количественные показатели, а таблицы измерений описывают связанные атрибуты. Это нисходящий, итеративный и гибкий подход, который подчеркивает быстрое получение бизнес-ценности за счет создания специализированных витрин данных для удовлетворения конкретных потребностей пользователей в отчетности.
Инмонский подход
С другой стороны, подход Билла Инмона делает упор на более централизованную, комплексную и структурированную среду хранения данных. Он выступает за нормализованную модель данных, в которой данные организованы в отдельные таблицы для устранения избыточности и поддержания целостность данных. Он использует концепцию «шины хранилища данных» для создания стандартизированных, повторно используемых компонентов и уделяет особое внимание Интеграция данных, преобразование и управление для обеспечения точности и согласованности данных.
Компоненты архитектуры СХД
Прежде чем мы перейдем к особенностям архитектуры, давайте поймем основы того, что представляет собой хранилище данных — скелет этой структуры.
Различные уровни хранилища данных или компоненты архитектуры DWH:
- База данных хранилища данных
Центральным компонентом типичной архитектуры хранилища данных является база данных, которая хранит все корпоративные данные и позволяет управлять ими для составления отчетов. Очевидно, это означает, что вам нужно выбрать, какой тип базы данных вы будете использовать для хранения данных в своем хранилище.
Ниже приведены четыре типа баз данных, которые вы можете использовать:
- Типичные реляционные базы данных — это базы данных, ориентированные на строки, которые вы, возможно, используете ежедневно, например Microsoft SQL Server, SAP, Oracle и IBM DB2.
- Базы данных аналитики специально разработаны для хранения данных для поддержки и управления аналитикой, такие как Teradata и Greenplum.
- Приложения для хранения данных это не совсем базы данных хранения, но некоторые дилеры теперь предлагают приложения, которые предлагают программное обеспечение для управления данными а также оборудование для хранения данных. Например, SAP Hana, Oracle Exadata и IBM Netezza.
- Облачные базы данных могут размещаться и получаться в облаке, поэтому вам не нужно приобретать какое-либо оборудование для настройки хранилища данных — например, Amazon Redshift, Google BigQuery и Microsoft Azure SQL.
2. Инструменты извлечения, преобразования и загрузки (ETL)
Инструменты ETL являются центральными компонентами корпоративное хранилище данных дизайн. Эти инструменты помогают извлекать данные из разных источников, преобразовывать их в подходящую структуру и загружать в хранилище данных.
Выбранный вами инструмент ETL определит следующее:
- Время, затраченное на извлечение данных
- Подходы к извлечению данных
- Вид примененных преобразований и простота их выполнения.
- Определение бизнес-правила для валидация данных и очистка для улучшения аналитики конечного продукта
- Заполнение затерянных данных
- Схема распределения информации из фундаментального хранилища в ваши приложения BI.

3. Метаданные
В типичной архитектуре хранилища данных метаданные описывают базу данных хранилища данных и предлагают структуру для данных. Это помогает в создании, сохранении, обработке и использовании хранилища данных.
В хранилищах данных существует два типа метаданных:
- Технические метаданные содержит информацию, которая может использоваться разработчиками и менеджерами при выполнении задач по развитию и администрированию хранилища.
- Бизнес-метаданные включает информацию, которая предлагает легко понимаемую точку зрения на данные, хранящиеся в хранилище.

Роль метаданных в хранилище данных
Метаданные играют важную роль для предприятий и технических специалистов, позволяя понять данные, находящиеся в хранилище, и преобразовать их в информацию.
Ваше хранилище данных — это не проект; это процесс. Чтобы сделать вашу реализацию максимально эффективной, вам необходимо использовать по-настоящему гибкий подход, который требует архитектура хранилища данных на основе метаданных.
Это визуальный подход к хранилищу данных, который использует модели данных, обогащенные метаданными, для управления каждым аспектом процесса разработки, от документирования исходных систем до репликации схем в физической базе данных и облегчения процесса разработки. отображение данных от источника до места назначения.
Схема хранилища данных настроить на уровне метаданных, что означает, что вам не нужно беспокоиться о качестве кода и о том, как он выдержит большие объемы данных. Фактически, вы можете управлять своими данными и контролировать их, не вдаваясь в код.
Кроме того, вы можете одновременно тестировать модели хранилища данных перед развертыванием и реплицируйте свою схему в любую ведущую базу данных. Подход, основанный на метаданных, приводит к итеративной культуре разработки и обеспечивает будущее развертывание вашего хранилища данных, поэтому вы можете обновлять существующую инфраструктуру в соответствии с новыми требованиями, не нарушая целостности и удобства использования вашего хранилища данных.
В сочетании с возможностями автоматизации проект хранилища данных на основе метаданных может оптимизировать проектирование, разработку и развертывание, что приводит к надежной реализации хранилища данных.
4. Инструменты доступа к хранилищу данных
Хранилище 0data использует базу данных или группу баз данных в качестве основы. Корпорации, занимающиеся хранилищами данных, обычно не могут работать с базами данных без использования инструментов, если у них нет администраторов баз данных. Однако это касается не всех подразделений.
Вот почему они прибегают к помощи нескольких инструментов хранения данных без кода, таких как:
- Инструменты запросов и отчетов Помогите пользователям создавать корпоративные отчеты для анализа, которые могут быть в форме электронных таблиц, расчетов или интерактивных визуальных изображений.
- Инструменты разработки приложений помогают создавать индивидуальные отчеты и представлять их в интерпретации, предназначенной для целей отчетности.
- Инструменты интеллектуального анализа данных для хранилищ данных систематизировать процедуру выявления массивов и связей в огромных объемах данных, используя современные методы статистического моделирования.
- OLAP-инструменты помогают построить многомерное хранилище данных и позволяют анализировать корпоративные данные с различных точек зрения.
5. Шина хранилища данных
Он определяет поток данных в архитектуре шины хранилища данных и включает в себя витрину данных. Витрина данных — это уровень доступа, который позволяет пользователям передавать данные. Он также используется для разделения данных, созданных для определенной группы пользователей.
6. Уровень отчетности хранилища данных
Уровень отчетов в хранилище данных позволяет конечным пользователям получать доступ к интерфейсу BI или архитектуре базы данных BI. Цель уровня отчетности в хранилище данных — выступать в качестве информационной панели для визуализации данных, создания отчетов и извлечения любой необходимой информации.
Характеристики проектирования хранилища данных
Ниже приведены основные характеристики проектирования, разработки и передового опыта хранилищ данных:
Тематически ориентированный
В проекте хранилища данных используется определенная тема. Он предоставляет информацию, касающуюся предмета, а не деятельности бизнеса. Эти темы могут быть связаны с продажами, рекламой, маркетингом и многим другим.
Вместо того, чтобы сосредотачиваться на бизнес-операциях или транзакциях, хранилища данных делают упор на бизнес-аналитику (BI), т. е. отображение и анализ данных для принятия решений. Он также предлагает прямую и краткую интерпретацию конкретной темы, исключая данные, которые могут оказаться бесполезными для лиц, принимающих решения.
унифицированный
Используя моделирование хранилища данных, проект хранилища данных объединяет и интегрирует данные из разных баз данных приемлемым для всех способом.
Он включает данные из различных источников, таких как реляционные и нереляционные базы данных, плоские файлы, мэйнфреймы и облачные системы. Кроме того, хранилище данных должно поддерживать согласованную классификацию, структуру и кодирование для облегчения эффективного анализа данных.
Разница во времени
В отличие от других операционных систем, хранилище данных хранит централизованные данные за определенный период времени. Таким образом, хранилище данных идентифицирует собранные данные в течение определенного периода времени и предоставляет информацию с точки зрения прошлого. Более того, он не позволяет структурировать или изменять данные после их поступления в хранилище.
энергонезависимость
Энергонезависимость — еще одна важная характеристика хранилища данных, означающая, что оно не удаляет первичные данные при загрузке новой информации. Более того, он позволяет только считывать данные и периодически обновлять их, чтобы предоставить пользователю полную и обновленную картину.
Типы архитектуры хранилища данных
Архитектура типичного хранилища данных определяет расположение данных в различных базах данных. Чтобы извлечь ценную информацию из необработанных данных, современная структура хранилища данных определяет наиболее эффективный метод организации и очистки данных.
Используя многомерную модель, хранилище данных извлекает и преобразует необработанные данные в промежуточной области в простую потребляемую структуру хранилища для предоставления ценной бизнес-аналитики.
Более того, в отличие от облачное хранилище данныхТрадиционная модель хранилища данных требует наличия локальных серверов для функционирования всех компонентов хранилища.
При проектировании корпоративного хранилища данных следует учитывать три различных типа моделей:
Одноуровневое хранилище данных
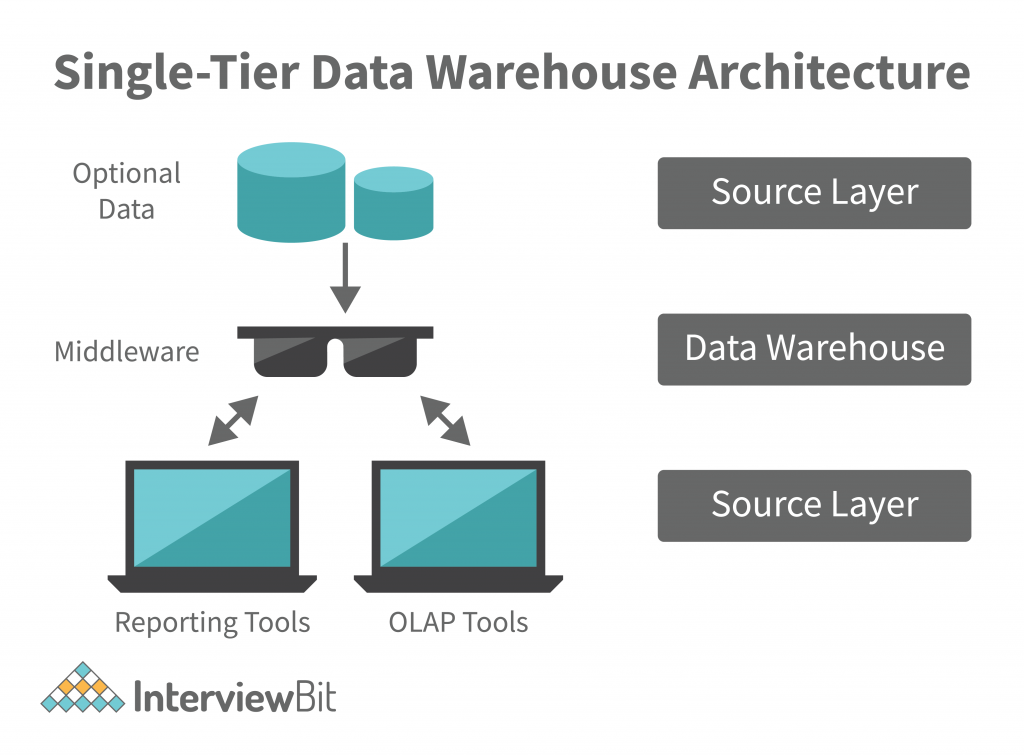
Источник: ИнтервьюБит
Структура одноуровневой архитектуры хранилища данных создает плотный набор данных и уменьшает объем хранимых данных.
Хотя это выгодно для устранения избыточности, этот тип структуры хранилища не подходит для предприятий со сложными требованиями к данным и многочисленными потоками данных. Именно здесь на помощь приходят многоуровневые архитектуры хранилищ данных, поскольку они работают с более сложными потоками данных.
Двухуровневое хранилище данных

Источник: ИнтервьюБит
Для сравнения, структура данных двухуровневой модели хранилища данных отделяет материальные источники данных от самого хранилища. В отличие от одноуровневой, двухуровневая конструкция использует систему и сервер базы данных.
Небольшие организации, где сервер используется в качестве витрины данных, обычно используют этот тип архитектуры хранилища данных. Хотя двухуровневая структура более эффективна при хранении и организации данных, она не масштабируется. Более того, он поддерживает только номинальное количество пользователей.
Трехуровневое хранилище данных

Трехуровневая архитектура хранилища данных является наиболее распространенным типом современной конструкции СХД, поскольку она обеспечивает хорошо организованный поток данных от необработанной информации до ценной информации.
Нижний уровень модели хранилища данных обычно включает сервер банка данных, который создает уровень абстракции для данных из многочисленных источников, таких как банки транзакционных данных, используемые для внешнего использования.
Средний уровень включает в себя Онлайн-аналитическая обработка (OLAP) сервер. Этот уровень преобразует данные в более подходящую структуру для анализа и многогранного исследования с точки зрения пользователя. Поскольку оно включает в себя предварительно встроенный в архитектуру сервер OLAP, мы также можем называть его хранилищем данных, ориентированным на OLAP.
Третий и самый верхний уровень — это уровень клиента, который включает в себя инструменты и интерфейс прикладного программирования (API), используемые для высокоуровневого анализа данных, запросов и отчетов.
Однако люди почти не включают 4-й уровень в архитектуру хранилища данных, поскольку он часто не считается таким же неотъемлемым, как другие три типа.
Теперь давайте подробно узнаем об основных компонентах хранилища данных (DWH) и о том, как они помогают создавать и масштабировать хранилище данных.

Облачная архитектура хранилища данных
Облачная архитектура хранилища данных использует ресурсы облачных вычислений для хранения, управления и анализа данных для бизнес-аналитики и аналитики. Основой этого хранилища данных является облачная инфраструктура, предоставляемая поставщиками облачных услуг, такими как AWS (Amazon Web Services), Azure или Google Cloud. Эти провайдеры предлагают ресурсы по требованию, такие как вычислительная мощность, хранилище и сеть.
Вот основные компоненты облачной архитектуры хранилища данных:
- Попадание данных: Первый компонент — это механизм приема данных из различных источников, включая локальные системы, базы данных, сторонние приложения и внешние каналы данных.
- Хранение данных : данные хранятся в облачном хранилище данных, которое обычно использует распределенные и масштабируемые системы хранения. Выбор технологии хранения может варьироваться в зависимости от поставщика облачных услуг и архитектуры: например, Amazon S3, Azure Data Lake Storage или Google Cloud Storage.
- Вычислительные ресурсы: Облачные хранилища данных предоставляют гибкие и масштабируемые вычислительные ресурсы для выполнения аналитических запросов. Эти ресурсы могут предоставляться по требованию, поэтому предприятия могут регулировать вычислительную мощность в зависимости от требований рабочей нагрузки.
- Автоматическое масштабирование: Облачные хранилища данных часто поддерживают автоматическое масштабирование, что упрощает предприятиям динамическую адаптацию в соответствии с требованиями рабочей нагрузки.
Модели традиционной и облачной архитектуры хранилища данных
Хотя традиционные хранилища данных предлагают полный контроль над оборудованием и расположением данных, они часто требуют более высоких первоначальных затрат, ограниченной масштабируемости и более медленного времени развертывания. Облачные хранилища данных, с другой стороны, обеспечивают преимущества с точки зрения масштабируемости, экономической эффективности, глобальной доступности и простоты обслуживания, но при этом потенциально уменьшают контроль над расположением и резидентностью данных.
Выбор между двумя архитектурами зависит от конкретных потребностей, бюджета и предпочтений организации. Вот более глубокий взгляд на различия между ними:
| Аспект | Традиционное хранилище данных | Облачное хранилище данных |
| Расположение и инфраструктура | Локально, с выделенным оборудованием | Облачный, с использованием инфраструктуры облачного провайдера. |
| Масштабируемость | Ограниченная масштабируемость, для роста требуется обновление оборудования. | Высокая масштабируемость, ресурсы по требованию для увеличения или уменьшения масштаба. |
| Капитальные затраты | Высокие первоначальные капитальные затраты на оборудование и инфраструктуру | Снижение первоначальных капитальных затрат, модель ценообразования с оплатой по факту использования |
| Операционные расходы | Текущие эксплуатационные расходы на техническое обслуживание, модернизацию и электропитание/охлаждение. | Снижение эксплуатационных расходов, поскольку обслуживание инфраструктуры берет на себя поставщик облачных услуг. |
| Время развертывания | Более длительное время развертывания для приобретения и настройки оборудования. | Более быстрое развертывание благодаря легкодоступным облачным ресурсам |
| Глобальная доступность | Доступ ограничен локальными расположениями, может потребоваться сложная настройка для глобального доступа. | Легкий доступ из любой точки мира, с возможностью распространения данных по всему миру. |
| Масштабируемость | Ограниченная масштабируемость, для роста требуется обновление оборудования. | Высокая масштабируемость, ресурсы по требованию для увеличения или уменьшения масштаба. |
| Data Integration | Интеграция с внешними источниками данных может быть сложной и ресурсоемкой. | Оптимизированная интеграция данных с облачными инструментами и сервисами ETL. |
| Безопасность данных | Безопасность и соответствие требованиям контролируются собственными силами, что потенциально сложно. | Поставщики облачных услуг предлагают надежные функции безопасности с шифрованием, контролем доступа и мерами обеспечения соответствия. |
| Резервное копирование и аварийное восстановление | Включает настройку и управление решениями для резервного копирования и аварийного восстановления. | Поставщики облачных услуг предлагают встроенные возможности резервного копирования и аварийного восстановления. |
| Предоставление ресурсов | Ручное выделение ресурсов и планирование мощности аппаратных ресурсов. | Автоматическое предоставление ресурсов, масштабирование и управление |
| Гибкость и ловкость | Ограниченная гибкость, менее оперативное реагирование на меняющиеся потребности бизнеса. | Повышенная гибкость и оперативность с возможностью масштабирования ресурсов по требованию. |
| Стоимость модели | Модель капитальных затрат, при которой затраты авансовые и фиксированные. | Модель операционных расходов с гибкой оплатой по мере использования |
| Обслуживание и обновления | Внутренняя ответственность за обслуживание оборудования, обновления и исправления. | Облачный провайдер занимается обслуживанием, обновлениями и исправлениями инфраструктуры. |
| Интеграция с инструментами BI | Интеграция с инструментами BI может потребовать дополнительной настройки и управления. | Бесшовная интеграция с широким спектром инструментов бизнес-аналитики и бизнес-аналитики. |
| Управление данными | Требуются внутренние процессы и инструменты управления. | Облачные хранилища данных часто предоставляют функции и инструменты управления данными. |
| Контроль местоположения данных | Полный контроль над расположением и резидентностью данных | Облачные данные могут распределяться по регионам, при этом местонахождение данных регулируется политикой поставщика облачных услуг. |
| Мониторинг ресурсов | Требуется настройка инструментов и систем мониторинга. | Поставщики облачных услуг предлагают встроенный мониторинг и аналитику использования ресурсов. |
Настройка архитектуры DW с использованием промежуточной области и витрин данных
Вы можете настроить архитектуру своего хранилища данных с помощью промежуточной области и витрин данных. Благодаря такой настройке вы можете предоставлять нужные данные нужным пользователям, что делает их более эффективными и действенными для бизнес-аналитики.
Плацдарм:
- Цель: Промежуточная область — это промежуточное пространство хранения в архитектуре хранилища данных, где необработанные или минимально обработанные данные временно хранятся перед загрузкой в основное хранилище данных.
- Адаптация люстры: вы можете настроить промежуточную область в соответствии с потребностями интеграции данных вашей организации. Например, вы можете спроектировать промежуточную область для размещения процессов преобразования данных, очистки данных и проверки данных, которые подготавливают данные к анализу.
Витрины данных:
- Цель: Витрины данных — это подмножества хранилища данных, специально разработанные для удовлетворения аналитических потребностей бизнес-подразделений, функций или групп пользователей. Они содержат предварительно агрегированные и адаптированные данные для конкретных типов анализа.
- Производство на заказ: Чтобы настроить архитектуру хранилища данных с помощью витрин данных, вам необходимо спроектировать и заполнить эти витрины данных на основе уникальных требований каждого отдела или группы пользователей.

Лучшие практики архитектуры хранилища данных
- Создавай модели хранилищ данных которые оптимизированы для поиска информации как в размерном, так и в денормализованном или гибридном подходах.
- Решите между ETL или ELT подход к интеграции данных.
- Выберите один подход к проектированию хранилища данных, например «сверху вниз» или «снизу вверх», и придерживайтесь его.
- При использовании ETL подходе всегда очищайте и преобразуйте данные с помощью инструмента ETL перед загрузкой данных в хранилище данных.

Фотография взята с сайта medium.com/@vishwan/data-preparation-etl-in-business- Performance-37de0e8ef632.
- Создайте автоматизированный процесс очистки данных, при котором все данные будут одинаково очищаться перед загрузкой.
- Разрешите обмен метаданными между различными компонентами хранилища данных для упрощения процесса извлечения.
- Примите гибкий подход вместо фиксированного подхода к построению хранилища данных.
- Всегда проверяйте, что данные правильно интегрированы, а не просто консолидированный при перемещении его из хранилищ данных в хранилище данных. Это потребует нормализации моделей данных 3NF.
Автоматизация проектирования хранилищ данных
Автоматизация проектирования хранилища данных может начните разработку хранилища данных. Очень важно правильно подобрать подход.
Во-первых, определите, где находятся ваши критически важные бизнес-данные и какие данные актуальны для ваших BI-инициатив. Затем создайте стандартизированную структуру метаданных, которая обеспечивает критический контекст для этих данных на моделирование данных этап.
Такая структура будет соответствовать вашей модели хранилища данных исходной системе, обеспечивая соответствующее построение отношений между сущностями с правильно определенными первичными и внешними ключами. Это также позволило бы установить правильные соединения таблиц и точно назначить типы связей между объектами.
Кроме того, вам необходимо иметь процессы, которые позволят вам интегрировать новые источники и другие изменения в вашу модель исходных данных и повторно развернуть ее. Использование итеративного подхода обеспечит более детальный взгляд на данные, предоставляемые для целей BI, и материализованных представлений.
Вы можете принять 3NF или подход многомерного моделированияв зависимости от ваших требований к BI. Последнее лучше, поскольку оно поможет вам создать упрощенную денормализованную структуру для вашей модели хранилища данных.
Пока вы это делаете, вот несколько важных советов, которые вам следует иметь в виду:
- Поддержание единообразия в многомерных моделях данных.
- Примените правильную технику обработки SCD к своим размерным атрибутам.
- Оптимизируйте загрузку таблицы фактов с помощью подхода, основанного на метаданных.
- Внедрите процессы для работы с ранними фактами
Наконец, члены команды могут протестировать Качество данных и целостность моделей данных до их развертывания в целевой базе данных. Имея автоматизированная проверка модели данных Инструмент может обеспечить значительную экономию времени.
Следование этим рекомендациям при автоматизации моделирования схемы поможет вам беспрепятственно обновлять модель и распространять изменения по конвейерам данных.
Следующим шагом в процессе проектирования хранилища данных является выбор правильной архитектуры хранилища данных.
Создайте свое хранилище данных с помощью Astera Построитель хранилища данных

Astera Построитель хранилища данных — это комплексное решение для хранения данных, которое автоматизирует проектирование и развертывание хранилища данных в среде без кода.
Он использует мета-ориентированный подход, который позволяет пользователям манипулировать данными с помощью комплексного набора встроенных преобразований без сложных сценариев ETL или сценариев SQL.
Узнайте больше о лучшей архитектуре хранилища данных для отчетности.




