

Die automatisierte, Kein Code Datenstapel
Erfahren Sie, wie Astera Data Stack kann die Datenverwaltung Ihres Unternehmens vereinfachen und rationalisieren.

Was ist Data Warehouse-Architektur?
In den letzten Jahrzehnten war die Data-Warehouse-Architektur die Säule der Datenökosysteme von Unternehmen. Und trotz zahlreicher Veränderungen in den letzten fünf Jahren im Bereich Big Data, Cloud Computing, prädiktiver Analyse und Informationstechnologien, Data Warehouse haben nur noch mehr an Bedeutung gewonnen.
Heute ist die Bedeutung von Data Warehousing lässt sich nicht leugnen, und es stehen mehr Möglichkeiten zum Speichern, Analysieren und Indizieren von Daten zur Verfügung als je zuvor.
In diesem Artikel werden die verschiedenen Grundkonzepte einer Enterprise-Data-Warehouse-Architektur, verschiedene Enterprise-Data-Warehouse-Modelle (EDW), ihre Merkmale und wesentlichen Komponenten erörtert und der Hauptzweck eines Data-Warehouse in modernen Industrien untersucht.
Theorien zur Data-Warehouse-Architektur
Um die Data-Warehouse-Architektur zu verstehen, ist es wichtig, Ralph Kimball und Bill Inmon zu kennen, die beiden prominenten Persönlichkeiten auf dem Gebiet des Data-Warehousing. Diese beiden schlugen unterschiedliche vor Ansätze bis hin zum Entwurf von Data-Warehousing-Architekturen.
Kimball-Ansatz
Ralph Kimball ist dafür bekannt dimensionale Modellierung Ansatz, der sich auf die Bereitstellung von Daten konzentriert, die für Endbenutzerabfragen und -berichte optimiert sind. Der Kimball-Ansatz konzentriert sich auf die Erstellung von Data Warehouses mithilfe von Sternschemastrukturen, bei denen eine zentrale Faktentabelle quantitative Kennzahlen enthält und Dimensionstabellen verwandte Attribute beschreiben. Es handelt sich um einen von oben nach unten gerichteten, iterativen und agilen Ansatz, der die schnelle Bereitstellung von Geschäftswert durch den Aufbau themenspezifischer Data Marts betont, um den spezifischen Berichtsanforderungen der Benutzer gerecht zu werden.
Inmon-Ansatz
Der Ansatz von Bill Inmon hingegen legt Wert auf eine stärker zentralisierte, umfassendere und strukturiertere Data-Warehousing-Umgebung. Es befürwortet ein normalisiertes Datenmodell, bei dem Daten in separaten Tabellen organisiert werden, um Redundanz zu vermeiden und zu verwalten Datenintegrität. Es nutzt ein „Data-Warehouse-Bus“-Konzept zur Erstellung standardisierter, wiederverwendbarer Komponenten und legt Wert darauf Datenintegration, Transformation und Governance, um Datengenauigkeit und -konsistenz sicherzustellen.
Komponenten der DWH-Architektur
Bevor wir zu den Besonderheiten der Architektur übergehen, wollen wir die Grundlagen dessen verstehen, was ein Data Warehouse ausmacht – das Grundgerüst hinter dieser Struktur.
Die verschiedenen Schichten eines Data Warehouse oder die Komponenten in einer DWH-Architektur sind:
- Data Warehouse-Datenbank
Zentraler Bestandteil einer typischen Data-Warehouse-Architektur ist eine Datenbank, die alle Unternehmensdaten vorhält und für das Reporting überschaubar macht. Dies bedeutet natürlich, dass Sie auswählen müssen, welche Art von Datenbank Sie zum Speichern von Daten in Ihrem Warehouse verwenden möchten.
Die folgenden vier Datenbanktypen können verwendet werden:
- Typische relationale Datenbanken sind die zeilenzentrierten Datenbanken, die Sie vielleicht täglich verwenden – zum Beispiel Microsoft SQL Server, SAP, Oracle und IBM DB2.
- Analytics-Datenbanken wurden speziell für die Datenspeicherung entwickelt, um Analysen wie Teradata und Greenplum aufrechtzuerhalten und zu verwalten.
- Data Warehouse-Anwendungen sind nicht gerade Speicherdatenbanken, aber mehrere Händler bieten mittlerweile Anwendungen an, die dies bieten Software für die Datenverwaltung sowie Hardware zur Datenspeicherung. Zum Beispiel SAP Hana, Oracle Exadata und IBM Netezza.
- Cloud-basierte Datenbanken kann in der Cloud gehostet und abgerufen werden, sodass Sie keine Hardware beschaffen müssen, um Ihr Data Warehouse einzurichten, z. B. Amazon Redshift, Google BigQuery und Microsoft Azure SQL.
2. Extraktions-, Transformations- und Lade-Tools (ETL)
ETL-Tools sind zentrale Bestandteile einer Enterprise Data Warehouse Design. Diese Tools helfen dabei, Daten aus verschiedenen Quellen zu extrahieren, sie in eine geeignete Anordnung umzuwandeln und sie in ein Data Warehouse zu laden.
Das von Ihnen gewählte ETL-Tool bestimmt Folgendes:
- Die aufgewendete Zeit Datenextraktion
- Ansätze zum Extrahieren von Daten
- Art der angewendeten Transformationen und die Einfachheit der Durchführung
- Geschäftsregeldefinition für Datenvalidierung und Reinigung zur Verbesserung der Endproduktanalytik
- Verlegte Daten werden gefüllt
- Gliederung der Informationsverteilung vom Fundamentaldepot zu Ihren BI-Anwendungen

3. Metadaten
In einer typischen Data-Warehouse-Architektur beschreiben Metadaten die Data-Warehouse-Datenbank und bieten einen Rahmen für Daten. Es hilft beim Aufbau, Erhalt, Umgang und der Nutzung des Data Warehouse.
Es gibt zwei Arten von Metadaten im Data Warehousing:
- Technische Metadaten umfasst Informationen, die von Entwicklern und Managern bei der Ausführung von Warehouse-Entwicklungs- und -Verwaltungsaufgaben verwendet werden können.
- Geschäfts-Metadaten enthält Informationen, die einen leicht verständlichen Standpunkt zu den im Lager gespeicherten Daten bieten.

Rolle von Metadaten in einem Data Warehouse
Metadaten spielen eine wichtige Rolle für Unternehmen und technische Teams, um die im Lager vorhandenen Daten zu verstehen und in Informationen umzuwandeln.
Ihr Data Warehouse ist kein Projekt; es ist ein Prozess. Um Ihre Implementierung so effektiv wie möglich zu gestalten, müssen Sie einen wirklich agilen Ansatz wählen, der Folgendes erfordert: a Metadaten-gesteuerte Data Warehouse-Architektur.
Dies ist ein visueller Ansatz für Data Warehousing, der mit Metadaten angereicherte Datenmodelle nutzt, um jeden Aspekt des Entwicklungsprozesses voranzutreiben, von der Dokumentation von Quellsystemen bis hin zur Replikation von Schemata in einer physischen Datenbank und deren Erleichterung Datenmapping Von der Quelle zum Ziel.
Das Data Warehouse-Schema ist auf Metadatenebene eingerichtet, was bedeutet, dass Sie sich keine Gedanken über die Codequalität machen müssen und wie er großen Datenmengen standhält. Tatsächlich können Sie Ihre Daten verwalten und kontrollieren, ohne in den Code einsteigen zu müssen.
Außerdem können Sie die Data Warehouse-Modelle gleichzeitig testen vor der Bereitstellung und replizieren Sie Ihr Schema in einer beliebigen führenden Datenbank. Ein metadatengesteuerter Ansatz führt zu einer iterativen Entwicklungskultur und macht Ihre Data Warehouse-Bereitstellung zukunftssicher, sodass Sie die vorhandene Infrastruktur mit den neuen Anforderungen aktualisieren können, ohne die Integrität und Benutzerfreundlichkeit Ihres Data Warehouse zu beeinträchtigen.
In Verbindung mit Automatisierungsfunktionen kann ein metadatengesteuertes Data-Warehouse-Design dies leisten Optimieren Sie Design, Entwicklung und Bereitstellung, was zu einer robusten Data Warehouse-Implementierung führt.
4. Data Warehouse-Zugriffstools
Ein 0data Warehouse verwendet eine Datenbank oder eine Gruppe von Datenbanken als Grundlage. Data Warehouse-Unternehmen können im Allgemeinen nicht ohne die Verwendung von Tools mit Datenbanken arbeiten, es sei denn, sie haben Datenbankadministratoren zur Verfügung. Dies ist jedoch nicht bei allen Geschäftsbereichen der Fall.
Aus diesem Grund nutzen sie die Unterstützung mehrerer No-Code-Data-Warehousing-Tools, wie zum Beispiel:
- Abfrage- und Berichterstellungstools Helfen Sie Benutzern, Unternehmensberichte zur Analyse zu erstellen, die in Form von Tabellenkalkulationen, Berechnungen oder interaktiven Grafiken vorliegen können.
- Tools zur Anwendungsentwicklung helfen, maßgeschneiderte Berichte zu erstellen und diese in Interpretationen für Berichtszwecke zu präsentieren.
- Data Mining-Tools für Data Warehousing systematisieren das Verfahren zur Identifizierung von Arrays und Verknüpfungen in riesigen Datenmengen mit Hilfe modernster statistischer Modellierungsmethoden.
- OLAP-Tools helfen beim Aufbau eines mehrdimensionalen Data Warehouse und ermöglichen die Analyse von Unternehmensdaten aus zahlreichen Blickwinkeln.
5. Data Warehouse Bus
Es definiert den Datenfluss innerhalb einer Data Warehousing-Busarchitektur und beinhaltet einen Data Mart. Ein Data Mart ist eine Zugriffsebene, die es Benutzern ermöglicht, Daten zu übertragen. Es wird auch zum Partitionieren von Daten verwendet, die für eine bestimmte Benutzergruppe erstellt werden.
6. Data Warehouse-Berichtsebene
Die Berichtsschicht im Data Warehouse ermöglicht den Endbenutzern den Zugriff auf die BI-Schnittstelle oder die BI-Datenbankarchitektur. Der Zweck der Berichtsschicht im Data Warehouse besteht darin, als Dashboard für die Datenvisualisierung zu fungieren, Berichte zu erstellen und alle erforderlichen Informationen zu entnehmen.
Eigenschaften von Data Warehouse Design
Im Folgenden sind die Hauptmerkmale des Entwurfs, der Entwicklung und der Best Practices von Data Warehousing aufgeführt:
Themenorientiert
Ein Data Warehouse-Entwurf verwendet ein bestimmtes Thema. Es enthält Informationen zu einem Thema und nicht zu den Geschäftsvorgängen eines Unternehmens. Diese Themen können sich auf Vertrieb, Werbung, Marketing und mehr beziehen.
Anstatt sich auf Geschäftsvorgänge oder Transaktionen zu konzentrieren, betont Data Warehousing Business Intelligence (BI), dh die Anzeige und Analyse von Daten für die Entscheidungsfindung. Es bietet auch eine einfache und prägnante Interpretation eines bestimmten Themas, indem Daten eliminiert werden, die für Entscheidungsträger möglicherweise nicht nützlich sind.
Einheitlicher
Mithilfe der Data-Warehouse-Modellierung vereinheitlicht und integriert ein Data-Warehouse-Design Daten aus verschiedenen Datenbanken in einer kollektiv geeigneten Weise.
Es integriert Daten aus verschiedenen Quellen, wie z. B. relationale und nicht relationale Datenbanken, Flatfiles, Mainframes und Cloud-basierte Systeme. Außerdem muss ein Data Warehouse konsistente Klassifizierung, Layout und Codierung beibehalten, um eine effiziente Datenanalyse zu ermöglichen.
Zeitabweichung
Im Gegensatz zu anderen Betriebssystemen speichert das Data Warehouse zentralisierte Daten aus einem bestimmten Zeitraum. Daher identifiziert das Data Warehouse die gesammelten Daten innerhalb einer bestimmten Zeitdauer und bietet Einblicke aus der Vergangenheitsperspektive. Darüber hinaus erlaubt es keine Struktur oder Änderung der Daten, nachdem sie in das Lager eingegeben wurden.
Nichtflüchtigkeit
Nichtflüchtigkeit ist ein weiteres wichtiges Merkmal eines Data Warehouse, was bedeutet, dass die Primärdaten nicht entfernt werden, wenn neue Informationen geladen werden. Darüber hinaus erlaubt es nur das Lesen von Daten und ein intermittierendes Auffrischen, um dem Benutzer ein vollständiges und aktualisiertes Bild zu liefern.
Arten von Data Warehouse-Architekturen
Die Architektur eines typischen Data Warehouse definiert die Anordnung von Daten in verschiedenen Datenbanken. Um wertvolle Informationen aus Rohdaten zu extrahieren, identifiziert eine moderne Data-Warehouse-Struktur die effektivste Technik zum Organisieren und Bereinigen der Daten.
Unter Verwendung eines dimensionalen Modells extrahiert und konvertiert das Data Warehouse die Rohdaten im Staging-Bereich in eine einfache verbrauchbare Lagerstruktur, um wertvolle Business Intelligence bereitzustellen.
Außerdem, im Gegensatz zu a Cloud Data Warehouse, erfordert ein herkömmliches Data-Warehouse-Modell lokale Server, damit alle Warehouse-Komponenten funktionieren.
Beim Entwerfen eines Unternehmens-Data Warehouse sind drei verschiedene Typen von Modellen zu berücksichtigen:
Einstufiges Data Warehouse
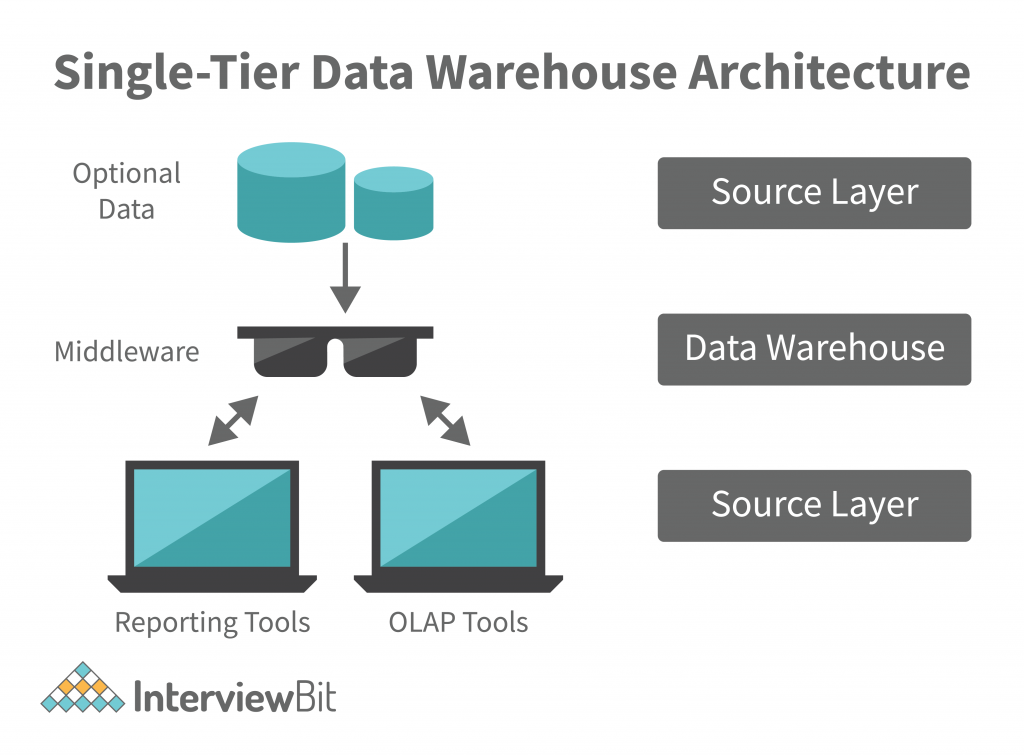
Quelle: InterviewBit
Der Aufbau einer Single-Tier-Data-Warehouse-Architektur erzeugt eine dichte Datenmenge und reduziert das Volumen der hinterlegten Daten.
Obwohl es für die Eliminierung von Redundanzen vorteilhaft ist, ist diese Art des Lagerdesigns nicht für Unternehmen mit komplexen Datenanforderungen und zahlreichen Datenströmen geeignet. Hier kommen mehrstufige Data-Warehouse-Architekturen ins Spiel, da sie mit komplexeren Datenströmen umgehen.
Zweistufiges Data Warehouse

Quelle: InterviewBit
Im Vergleich dazu trennt die Datenstruktur eines zweistufigen Data-Warehouse-Modells die materiellen Datenquellen vom Warehouse selbst. Im Gegensatz zu einem Single-Tier-Design verwendet das Two-Tier-Design ein System und einen Datenbankserver.
Kleine Organisationen, in denen ein Server als Data Mart verwendet wird, verwenden normalerweise diese Art von Data Warehouse-Architekturtyp. Obwohl es bei der Datenspeicherung und -organisation effizienter ist, ist die zweistufige Struktur nicht skalierbar. Darüber hinaus unterstützt es nur eine nominelle Anzahl von Benutzern.
Dreistufiges Data Warehouse

Die dreistufige Data-Warehouse-Architektur ist die häufigste Art des modernen DWH-Designs, da sie einen gut organisierten Datenfluss von Rohinformationen zu wertvollen Erkenntnissen erzeugt.
Die unterste Ebene im Data-Warehouse-Modell umfasst typischerweise den Datenbankserver, der eine Abstraktionsschicht für Daten aus zahlreichen Quellen erstellt, wie z. B. Transaktionsdatenbanken, die für Front-End-Anwendungen verwendet werden.
Die mittlere Stufe enthält eine Online Analytical Processing (OLAP) Server. Diese Ebene ändert die Daten in eine geeignetere Anordnung für die Analyse und das vielfältige Sondieren aus der Perspektive des Benutzers. Da es einen in der Architektur vorgefertigten OLAP-Server enthält, können wir es auch als OLAP-fokussiertes Data Warehouse bezeichnen.
Die dritte und oberste Ebene ist die Client-Ebene, die die Tools und die Anwendungsprogrammierschnittstelle (API) umfasst, die für Datenanalysen, Abfragen und Berichte auf hoher Ebene verwendet werden.
Die 4. Ebene wird jedoch kaum in die Data Warehouse-Architektur aufgenommen, da sie oft nicht als so integral wie die anderen drei Typen angesehen wird.
Lassen Sie uns nun mehr über die Hauptkomponenten eines Data Warehouse (DWH) erfahren und wie sie dabei helfen, ein Data Warehouse im Detail aufzubauen und zu skalieren.

Cloudbasierte Data Warehouse-Architektur
Eine cloudbasierte Data-Warehouse-Architektur nutzt Cloud-Computing-Ressourcen, um Daten für Business Intelligence und Analysen zu speichern, zu verwalten und zu analysieren. Die Grundlage dieses Data Warehouse ist die Cloud-Infrastruktur, die von Cloud-Dienstanbietern wie AWS (Amazon Web Services), Azure oder Google Cloud bereitgestellt wird. Diese Anbieter bieten On-Demand-Ressourcen wie Rechenleistung, Speicher und Netzwerk.
Hier sind die Hauptkomponenten der cloudbasierten Data Warehouse-Architektur:
- Datenaufnahme: Die erste Komponente ist ein Mechanismus zum Erfassen von Daten aus verschiedenen Quellen, einschließlich lokalen Systemen, Datenbanken, Anwendungen von Drittanbietern und externen Datenfeeds.
- Datenspeicher: Die Daten werden im Cloud Data Warehouse gespeichert, das typischerweise verteilte und skalierbare Speichersysteme verwendet. Die Wahl der Speichertechnologie kann je nach Cloud-Anbieter und Architektur variieren, mit Optionen wie Amazon S3, Azure Data Lake Storage oder Google Cloud Storage.
- Compute-Ressourcen: Cloudbasierte Data Warehouses bieten flexible und skalierbare Rechenressourcen für die Ausführung analytischer Abfragen. Diese Ressourcen können bei Bedarf bereitgestellt werden, sodass Unternehmen die Verarbeitungsleistung je nach Arbeitslastanforderungen anpassen können.
- Automatische Skalierung: Cloudbasierte Data Warehouses unterstützen häufig die automatische Skalierung, was es Unternehmen erleichtert, sich dynamisch an die Anforderungen der Arbeitslast anzupassen.
Traditionelle vs. Cloud Data Warehouse-Architekturmodelle
Während herkömmliche Data Warehouses die vollständige Kontrolle über Hardware und Datenspeicherort bieten, sind sie oft mit höheren Vorabkosten, begrenzter Skalierbarkeit und langsameren Bereitstellungszeiten verbunden. Cloud-Data-Warehouses hingegen bieten Vorteile in Bezug auf Skalierbarkeit, Kosteneffizienz, globale Zugänglichkeit und einfache Wartung, allerdings mit dem Nachteil einer möglicherweise eingeschränkten Kontrolle über den Speicherort und den Speicherort der Daten.
Die Wahl zwischen den beiden Architekturen hängt von den spezifischen Anforderungen, dem Budget und den Vorlieben einer Organisation ab. Hier ist ein genauerer Blick auf die Unterschiede zwischen den beiden:
| Aspekt | Traditionelles Data Warehouse | Cloud-Data Warehouse |
| Standort und Infrastruktur | Vor Ort, mit dedizierter Hardware | Cloudbasiert, Nutzung der Infrastruktur des Cloud-Anbieters |
| Skalierbarkeit | Begrenzte Skalierbarkeit, Hardware-Upgrades für Wachstum erforderlich | Hoch skalierbar, mit On-Demand-Ressourcen zur Skalierung nach oben oder unten |
| Kapitalaufwendungen | Hohe anfängliche Kapitalkosten für Hardware und Infrastruktur | Niedrigere Investitionskosten im Vorfeld, Pay-as-you-go-Preismodell |
| Betriebskosten | Laufende Betriebskosten für Wartung, Upgrades und Strom/Kühlung | Reduzierte Betriebskosten, da der Cloud-Anbieter die Wartung der Infrastruktur übernimmt |
| Bereitstellungszeit | Längere Bereitstellungszeiten für Hardwarebeschaffung und -einrichtung | Schnellere Bereitstellung aufgrund leicht verfügbarer Cloud-Ressourcen |
| Globale Zugänglichkeit | Der auf lokale Standorte beschränkte Zugriff erfordert möglicherweise komplexe Einstellungen für den globalen Zugriff | Leichter Zugriff von überall auf der Welt, mit der Möglichkeit, Daten global zu verteilen |
| Skalierbarkeit | Begrenzte Skalierbarkeit, Hardware-Upgrades für Wachstum erforderlich | Hoch skalierbar, mit On-Demand-Ressourcen zur Skalierung nach oben oder unten |
| Datenintegration | Die Integration mit externen Datenquellen kann komplex und ressourcenintensiv sein | Optimierte Datenintegration mit cloudbasierten ETL-Tools und -Diensten |
| Datensicherheit | Sicherheit und Compliance werden intern verwaltet, was möglicherweise komplex ist | Cloud-Anbieter bieten robuste Sicherheitsfunktionen mit Verschlüsselung, Zugriffskontrollen und Compliance-Maßnahmen |
| Backup und Disaster Recovery | Beinhaltet die Einrichtung und Verwaltung von Backup- und Disaster-Recovery-Lösungen | Cloud-Anbieter bieten integrierte Backup- und Disaster-Recovery-Optionen |
| Ressourcenbereitstellung | Manuelle Bereitstellung und Kapazitätsplanung für Hardwareressourcen | Automatische Ressourcenbereitstellung, Skalierung und Verwaltung |
| Flexibilität und Agilität | Begrenzte Flexibilität und weniger Agilität bei der Reaktion auf sich ändernde Geschäftsanforderungen | Größere Flexibilität und Agilität mit der Möglichkeit, Ressourcen nach Bedarf zu skalieren |
| Kostenmodell | Investitionsmodell, bei dem die Kosten im Voraus festgelegt und festgelegt werden | Betriebsausgabenmodell mit flexibler Pay-as-you-go-Preisgestaltung |
| Wartung und Updates | Eigene Verantwortung für Hardwarewartung, Updates und Patches | Der Cloud-Anbieter kümmert sich um die Wartung, Updates und Patches der Infrastruktur |
| Integration mit BI-Tools | Die Integration mit BI-Tools erfordert möglicherweise zusätzliche Einrichtung und Verwaltung | Nahtlose Integration mit einer Vielzahl von BI- und Analysetools |
| Datenverwaltung | Erfordert interne Governance-Prozesse und -Tools | Cloudbasierte Data Warehouses bieten häufig Data-Governance-Funktionen und -Tools |
| Kontrolle des Datenstandorts | Volle Kontrolle über den Speicherort und den Speicherort der Daten | Cloudbasierte Daten können über Regionen verteilt werden, wobei die Datenresidenz den Richtlinien des Cloud-Anbieters unterliegt |
| Ressourcenüberwachung | Erfordert die Einrichtung von Überwachungstools und -systemen | Cloud-Anbieter bieten integrierte Überwachung und Analyse für die Ressourcennutzung |
Anpassen der DW-Architektur mit Staging-Bereich und Data Marts
Sie können Ihre Data Warehouse-Architektur mit einem Staging-Bereich und Data Marts anpassen. Mit dieser Anpassung können Sie den richtigen Benutzern die richtigen Daten bereitstellen, was sie für Business Intelligence und Analysen effizienter und effektiver macht.
Bühnenbereich:
- Sinn: Ein Staging-Bereich ist ein Zwischenspeicherplatz innerhalb der Data-Warehouse-Architektur, in dem Rohdaten oder minimal verarbeitete Daten vorübergehend gespeichert werden, bevor sie in das Haupt-Data-Warehouse geladen werden.
- Maßgeschneidert: Sie können den Staging-Bereich basierend auf den Datenintegrationsanforderungen Ihrer Organisation anpassen. Beispielsweise können Sie den Staging-Bereich so gestalten, dass er Datentransformations-, Datenbereinigungs- und Datenvalidierungsprozesse unterstützt, die die Daten für die Analyse vorbereiten.
Datamarts:
- Zweck: Data Marts sind Teilmengen eines Data Warehouse, die speziell für die Analyseanforderungen von Geschäftsabteilungen, Funktionen oder Benutzergruppen entwickelt wurden. Sie enthalten voraggregierte und maßgeschneiderte Daten für bestimmte Analysearten.
- Anpassung: Um die Data Warehouse-Architektur mit Data Marts anzupassen, müssen Sie diese Data Marts basierend auf den individuellen Anforderungen jeder Abteilung oder Benutzergruppe entwerfen und füllen.

Best Practices der Data Warehouse-Architektur
- Erstellen Data Warehouse-Modelle Diese sind für das Abrufen von Informationen sowohl in dimensionalen als auch in de-normalisierten oder hybriden Ansätzen optimiert.
- Entscheiden Sie sich zwischen einem ETL oder ein ELT Ansatz zur Datenintegration.
- Wählen Sie einen einzigen Ansatz für Data-Warehouse-Designs, z. B. den Top-Down- oder den Bottom-Up-Ansatz, und bleiben Sie dabei.
- Bei Verwendung eines ETL Ansatz: Bereinigen und transformieren Sie Daten immer mit einem ETL-Tool, bevor Sie die Daten in das Data Warehouse laden.

Foto von medium.com/@vishwan/data-preparation-etl-in-business-performance-37de0e8ef632
- Erstellen Sie einen automatisierten Datenbereinigungsprozess, bei dem alle Daten vor dem Laden einheitlich bereinigt werden.
- Ermöglichen Sie die gemeinsame Nutzung von Metadaten zwischen verschiedenen Komponenten des Data Warehouse für einen reibungslosen Extraktionsprozess.
- Verwenden Sie beim Aufbau Ihres Data Warehouse einen agilen Ansatz anstelle eines starren Ansatzes.
- Stellen Sie immer sicher, dass die Daten richtig integriert sind und nicht nur konsolidiert beim Verschieben von den Datenspeichern in das Data Warehouse. Dies würde die 3NF-Normalisierung von Datenmodellen erfordern.
Automatisieren des Data Warehouse-Designs
Die Automatisierung des Data Warehouse-Designs kann Starten Sie Ihre Data Warehouse-Entwicklung. Es ist wichtig, dass Sie Ihren Ansatz richtig finden.
Identifizieren Sie zunächst, wo sich Ihre kritischen Geschäftsdaten befinden und welche Daten für Ihre BI-Initiativen relevant sind. Erstellen Sie dann ein standardisiertes Metadaten-Framework, das einen kritischen Kontext für diese Daten bereitstellt Datenmodellierung Stufe.
Ein solches Framework würde Ihr Data-Warehouse-Modell an das Quellsystem anpassen und eine angemessene Konstruktion von Beziehungen zwischen Entitäten mit korrekt definierten Primär- und Fremdschlüsseln sicherstellen. Es würde auch korrekte Tabellenverknüpfungen herstellen und Entitätsbeziehungstypen genau zuweisen.
Außerdem müssen Sie über Prozesse verfügen, mit denen Sie neue Quellen und andere Änderungen in Ihr Quelldatenmodell integrieren und erneut bereitstellen können. Ein iterativer Ansatz bietet einen detaillierteren Ausblick auf die für BI-Zwecke gelieferten Daten und materialisierten Ansichten.
Sie können eine 3NF adoptieren oder dimensionaler Modellierungsansatz, abhängig von Ihren BI-Anforderungen. Letzteres ist besser, da es Ihnen hilft, eine optimierte, denormalisierte Struktur für Ihr Data Warehouse-Modell zu erstellen.
Wenn Sie schon dabei sind, hier sind einige wichtige Tipps, die Sie beachten sollten:
- Behalten Sie eine konsistente Maserung in dimensionalen Datenmodellen bei
- Wenden Sie die richtige SCD-Handhabungstechnik auf Ihre Dimensionsattribute an
- Optimieren Sie das Laden von Faktentabellen mit einem metadatengesteuerten Ansatz
- Richten Sie Prozesse ein, um mit früh eintreffenden Fakten umzugehen
Abschließend können die Teammitglieder testen Datenqualität und die Integrität von Datenmodellen, bevor sie in der Zieldatenbank bereitgestellt werden. Mit einem automatisierte Datenmodellüberprüfung Werkzeug kann erhebliche Zeitersparnisse bieten.
Wenn Sie diese Best Practices bei der Automatisierung der Schemamodellierung befolgen, können Sie Ihr Modell nahtlos aktualisieren und Änderungen an Ihre Datenpipelines weitergeben.
Der nächste Schritt im Data-Warehouse-Designprozess ist die Auswahl der richtigen Data-Warehousing-Architektur.
Erstellen Sie Ihr Data Warehouse mit Astera DW-Builder

Astera DW-Builder ist eine End-to-End-Data-Warehousing-Lösung, die das Entwerfen und Bereitstellen eines Data Warehouse in einer Code-freien Umgebung automatisiert.
Es verwendet einen metagesteuerten Ansatz, der es Benutzern ermöglicht, Daten mithilfe eines umfassenden Satzes integrierter Transformationen ohne komplexes ETL-Skripting oder SQL-Skripting zu manipulieren.
Erfahren Sie mehr über die beste Data-Warehouse-Architektur für die Berichterstellung.

Autoren:
 Nida Fatima
Nida Fatima



