
The Automated, No-Code Data Stack
Learn how Astera Data Stack can simplify and streamline your enterprise’s data management.

Modernize Your Data Architecture with a Best-Practices Approach to Dimensional Data Modeling
Dimensional data modeling has been the foundation of effective data warehouse design for decades. Kimball’s methodology promises optimized query performance and a streamlined structure that’s easily understood by stakeholders at every level of the enterprise. Read on to find out how our automated approach helps you implement this schema for maximum effectiveness in your data warehouse.
To build a truly modern analytics architecture that enables advanced techniques like machine learning, predictive analysis, forecasting, and data visualizations, you need to implement dimensional data modeling in your data warehouse. There are a few checkmarks a BI system needs to hit before it can qualify.
First, it must be capable of collecting and processing large volumes of data from disparate transactional sources. Second, it should handle both current and historical records. Third, it should support a range of complex, ever-changing query operations. Finally, it needs to produce up-to-date, relevant data for your end-users.
The key to meeting these expectations lies in the design stage during data modeling. The decisions you make here will directly affect your data warehouse’s agility, performance, and scalability.
But Why Dimensional Data Modeling?
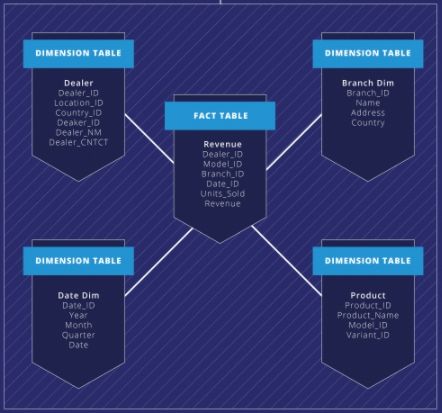
The classic star schema
Let’s say you opt for a 3NF schema, which minimizes data redundancy through normalization. The number of tables store will increase substantially. This means that any query run against a 3NF schema would involve a lot of complex joins.
By comparison, dimensional modeling techniques offer a streamlined, denormalized structure that produces far fewer joins and thus improves query performance. Dimensional data models also support slowly changing data and date/time-specific dimensions, both of which facilitate historical analysis. This schema is more easily understood by end-users, allowing them to collaborate with their development team using a common language. As a result, it becomes much easier to build a data warehouse around actual business processes and evolve the data model to encompass the ever-changing needs of your enterprise.
Let’s look at some critical factors that will make your dimensional models a key driver for your data warehouse development.
Pay Attention to the Grain

Finding the right grain for your fact table is essential (hint: wheat won’t work)
Finding the right grain for your fact table row is essential (hint: wheat won’t work)
Typically, you will want to build individual dimensional models for different areas of operation across your enterprise. Each of these processes will have a defined grain; this is the level of detail at which data is stored in fact tables and related dimensions. It is essential to maintain a consistent grain in dimensional data models to ensure the best performance and usability during the consumption phase. Otherwise, you might end up with miscalculated reports and analyses.
For an excellent example of this, let’s say you’re designing a dimensional data model for your sales process. You have two different sources in which data is recorded, one tracking domestic invoices on a per-transaction basis and the other tracking orders generated globally per month. One table is far better suited to later slicing and dicing of data while the latter essentially provides a summary view of the sales process, which will only be useful high-level reporting and business intelligence.
In general, when data relates to different business processes, you can assume that multiple models will need to be built. So, you need to be able to engineer these schemas accurately based on the entity relationships identified at the source system. Facts and dimension tables should be assigned correctly at the appropriate level of detail.
By moving to a process that allows you to automate initial schema modeling, you can ensure that these basic concepts are correctly applied to your schema. From there, you can work to mold it more closely to your BI requirements. More importantly, you can easily update your models to reflect changes in the source system or end-user requirements and then propagate these changes across your data pipelines without extensive manual rework.
Another critical detail to getting your approach right is ensuring that your dimensional modeling approach includes date dimension tables. These tables provide various types of date-specific measurement such as daily, monthly, yearly, fiscal quarters, or public holidays. Ultimately, this will help end-users filter and group their data more efficiently during the consumption phase.
Automatically Handle Your Slowly Changing Data

Those historical records can come in handy (https://xkcd.com/2075/)
Business processes are in a constant stage of change. Employees join the organization, get promoted, and eventually retire. Customers move to a new address or change their contact details. In some cases, entire departments are absorbed, renamed, or restructured. Therefore, you must ensure that your dimensional model can reflect this dynamic environment accurately.
By applying the correct SCD-handling technique to your dimensional data models, you can account for changes to records in the source system and, if necessary, preserve historical data for further analysis. Now, there are multiple SCD types available based on your requirements. Techniques range from SCD Type 1 for overwriting past values to SCD Type 3 which updates the current record while adding a new field to show the previous value for the attribute.
The dimension table may also contain additional fields to reflect when a particular change came into effect (Effective Date/Expiry Date) or the currency of a specific record (Version) in case multiple changes have been made to it across the years. You may even have an active flag indicator to denote which version of a record is in use at the time of reporting.
One caveat here is that it is cumbersome to facilitate these inserts and updates during data warehouse loading manually. After all, we’re talking about implementing processes to automatically check for changes in the source system record then identifying whether records should be overwritten or updated. In the latter case, several new surrogate keys may need to be generated, not to mention multiple new fields. You will also have to create data mapping for all of these activities.
If you’re developing your data warehouse with the help of a dimensional data modeling tool that follows a code-free metadata-driven approach, you can simply assign the relevant SCD types to attributes at the logical level. Then, these details will be propagated to an ETL engine that can automatically handle subsequent insert/updates, joins, and data mapping considerations without any manual effort.
Streamline Fact Table Loading

All data pipelines lead to fact and dimension tables
Fact table loading is another area that introduces a lot of additional manual effort during data pipeline development. This process involves engineering multiple joins between dimension tables. Considering that fact tables generally contain millions of records, the high cost of performing this operation is apparent.
Each time the fact table is populated, lookups in the dimensional data model cross-reference every business key against the relevant dimension table and convert it into a surrogate key. Suppose the dimension table is particularly large, or several changes have been made to source records (in the case of slowly changing dimensions). In that case, the lookup can become particularly time-consuming and resource-intensive. Of course, this task will be repeated consistently as transactional data is constantly updated.
In many cases, you may need to create an additional staging table between the source system and data warehouse to store all of this historical data and thus make it easier to process it further during loading.
You could also have to perform advanced hierarchical data mappings from source systems to ensure data at the correct grain is being loaded into the fact table.
Now, if we go back to the metadata-driven approach outlined previously, we can find a way to accelerate this process radically. If, instead, you configure fact attributes within the dimensional data model, then use these entities in the data pipeline the joins and lookups required for data warehouse population can be carried out automatically by the underlying ETL/ELT engine.
Put Processes in Place to Deal with Early Arriving Facts

Sometimes, the reality of your business environment may not fit neatly into the requirements of a standard schema.
For example, an employee ID might be generated for a recruit before the organization has any information on who they are or even a specific joining date for the candidate. If you’ve built a dimensional data model to reflect your HR process, this scenario will result in a fact table record without any related dimensional attributes. Essentially, a failed foreign key lookup.
Now, in this case, it’s a matter of waiting for the desired information to arrive, so the best approach is to replace the missing data with a placeholder dimension containing default values. Then, once the employee’s details are recorded in their entirety, the attributes can be updated in the relevant table. In other cases, you may not want to process the record at all, in which case you would want the entry to be flagged or omitted altogether during the data warehouse population.
Regardless of how you deal with these situations, your dimensional data model must allow for dynamic configurations that reflect the nature of your business.
Engineer Metadata-Enriched Dimensional Data Models at Speed with Astera DW Builder
Astera DW Builder is a comprehensive dimensional data modeling tool that allows you to engineer comprehensive dimension models from a transactional system in minutes.
Our intuitive engine can automatically develop a best-fit schema assigning facts and dimensions based on the entity relationships contained within the source database. Alternatively, you can make use of ADWB’s feature-rich toolbox to create your own dimensional model from scratch, complete with fact, dimension, and date dimension tables. Then, simply configure each entity with necessary attributes, including SCD types, surrogate keys, business keys, and other identifying metadata.
We also offer various functionalities to accelerate the data warehouse loading process, including dedicated fact and dimension loaders to expedite data transfer into your destination. ADWB also provides a purpose-built data model query object which allows you to join multiple source system tables to create a hierarchical source entity that you can easily map to relevant data warehouse tables.
To get a closer look at Astera DW Builder’s dimensional modeling and data warehouse automation capabilities, get in touch with us now. Or check out the product for yourself.
Authors:
Adnan Sami Khan



 Nov 11th
Nov 11th 