
The Automated, No-Code Data Stack
Learn how Astera Data Stack can simplify and streamline your enterprise’s data management.

Data Extraction Template: Get PDF Data from Forms & Tables
Businesses regularly get product and consumer data from a multitude of sources like production facilities, distribution centers, retailers, partners, and other third-party vendors. This data is usually in the form of Excel spreadsheets, PDFs, PDF forms, TXT and RTF files. Extracting information from this data deluge usually takes longer; because before analysis, it needs to be transformed into structured data—which is done manually by data entry. Modern data pulling tools use data extraction templates to can cut down the time on data extraction by automating various tasks involved in the data extraction process such as manual entry, data transformation, data cleansing, and data validation.
Data volumes increase exponentially with time, and enterprises require a data extraction approach that process large volumes of data for analysis and reporting. Moreover, post-COVID-19, the increasing trend in online activity has resulted in more unstructured data for industries like education. To meet these growing needs, a robust document data capture solution is required. While manual data entry and coded solutions can certainly do the job, document extraction software that work on pattern-based templates are significantly more efficient and don’t run the chance of human-based errors.
Benefits of Using a Data Extraction Template
Data extraction templates assist in a company’s data extraction strategy by streamlining and accelerating the process. Here is how:
- Reusable: Once a template is created, it can be used for as long as needed, removing the need to process individual files separately
- Easy to use: Data extraction templates are simple to use and do not need to be changed once set up unless the data demands modifications—which can be done effortlessly
- Saves time and resources: Templates deal with all files with the same pattern without any intervention and saves significant employee time that can be set to other important tasks
When Do You Need Data Extraction Templates?
In financial data extraction, retail data extraction or data parsing in any other industry where there are unstructured documents in a similar format—like PDF invoices—using a template is extremely effective. For example, PDF data extraction can act as a guide for data mining of documents that match an initial pattern and removes the need to instruct the tool about where to extract data from for every new file.
Different templates can be created for different document types like invoices, purchase orders, production data and customer data, which will then process all documents that match its category.
With data extraction templates in place for all possible patterns of data that are received, enterprises can save plenty of time and resources and allocate them elsewhere. However, certain idiosyncrasies of data pose great challenges when creating a template. Let’s discuss them.
Challenges of Document Data Capture
There are numerous sources from which you can extract data, like PDFs, RTFs, and TXT. Apart from the varying origins, capturing information from these documents brings about specific challenges that need to be resolved for a successful data extraction process. The extracted data should be standardized so that it can be processed further for analysis and reporting. Of course, standardization creates multiple issues. Following are the most common challenges in extracting data that businesses should keep in mind before implementing a solution.
- Floating Fields
Usually, data like invoices and customer information follow the same format, but in some documents, data may be placed in varying locations and therefore, cannot be processed uniformly. For example, the field location may vary in a single row or column, apart from the rest of the fields.
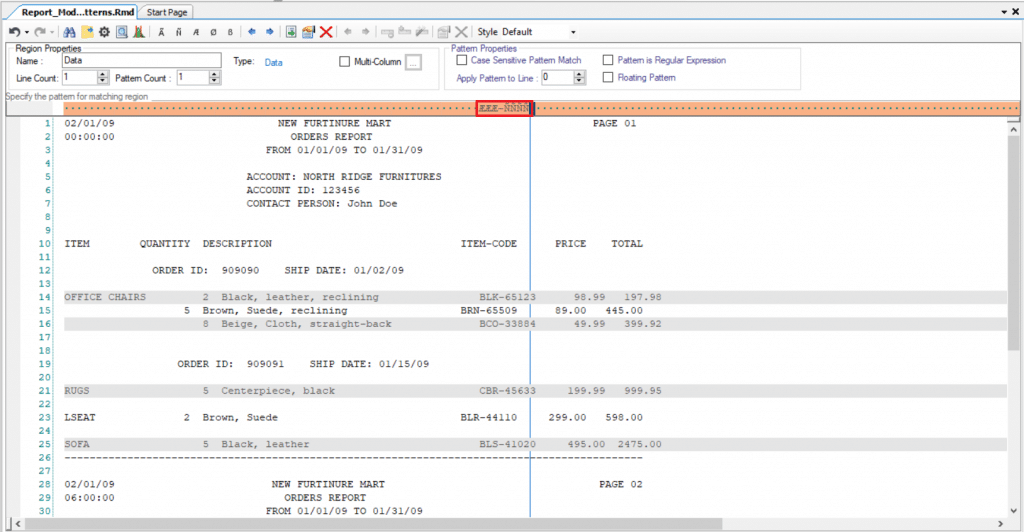
Floating fields
This disruption in pattern can be problematic when creating data extraction templates and it is important to deal with these discrepancies and find a way to incorporate into the pattern.
- Documents Containing Disjoint Data Sets
There can be records that contains disparate data. A data extraction table example can be a pdf file where the first page lists down columns of information and the second page does the same except one alignment error: the last column wraps down to the next line.
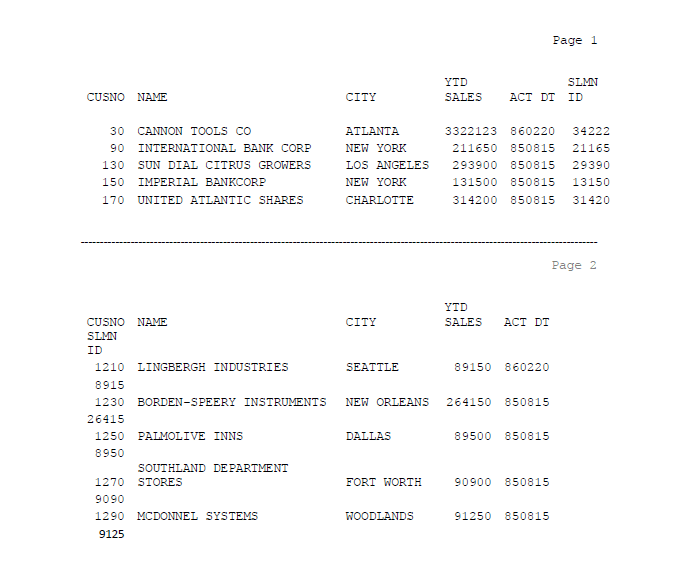
Disjoint data sets in a file
For such data sets with similar data but independent patterns in the same files, it becomes difficult to create a data extraction template that meets the criteria for both pages.
- Data Verification
Once the task of creating a data extraction template is complete, it is important to run the data in real time and set some data qualification rules in place to validate the accuracy of data. Smart data file extractors will offer built-in features for customizable data verification and allow businesses to flag incorrect data. After that, automation can help either drop the erroneous records or email the logs to the concerned authorities to be reviewed.
While data capture can be done by code, it is easier to mitigate all the aforementioned challenges with a powerful template-based data extraction tool.
Transform data into actionable insights in minutes with ReportMiner
Convert data into insights. Automate data extraction from PDFs, forms, and tables, saving time and reducing errors with Astera ReportMiner.
Claim Your Free Trial Now
How Data Extraction Tools Can Help?
Choosing the right tool can make or break an enterprise’s data extraction strategy, so it is important to make the selection after careful consideration of the business use case and the tool’s features. Ideally, it should be able to meet all the challenges listed above, and any other requirement of the company’s data extraction jobs.
It is also important to look into the data sources supported by the report extraction software, like RTFs, PDFs, XLS, and XLSX, and content types like text, scanned documents, and forms. Astera ReportMiner is a robust solution that automates the entire data extraction process and offers support to a multitude of sources and destinations. Whether it’s extracting data from regular sources or from MS Word or OCR scanned files, Astera ReportMiner is able to automate the processes and simplify enterprise data extraction.
Use Case: Pulling Data from PDFs
Consider a growing retail company, Shazz, that sells clothing aimed for children and teenagers. The company processes purchase orders and invoices in PDFs for reporting and analysis. Initially, they started with using data entry specialists to convert the pdf tables and other data into a standardized format, but with the increasing demand, the company struggled to meet the requirements. They decided to research content extraction tools in the market and came across Astera ReportMiner.
The Operations Manager started with the free trial and after playing around with the features, requested a walkthrough of the product’s data extraction features using samples from the company. They were happy to find that the platform offered connectivity to various destinations, and was able to automate the entire process with help of data extraction templates. Astera ReportMiner was able to pick pdfs from designated folders whenever a pdf drops into the folder. With data extraction workflows, extracting information from the data and transforming it becomes easier and quicker. Decision-making options allowed Shazz to send the transformed data to one destination for review (in case of errors) or to the other destination for further processing.
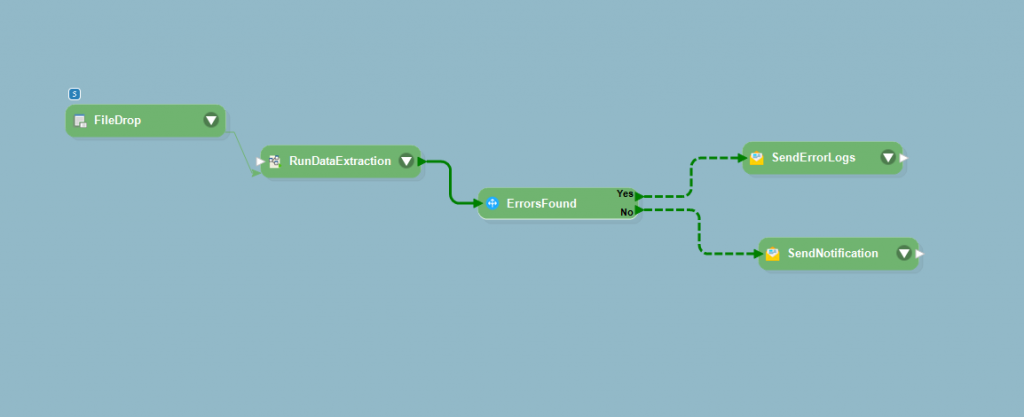
The in-built features of auto-parsing of name and addresses and the auto-creation of document extraction patterns made the process easier for Shazz.
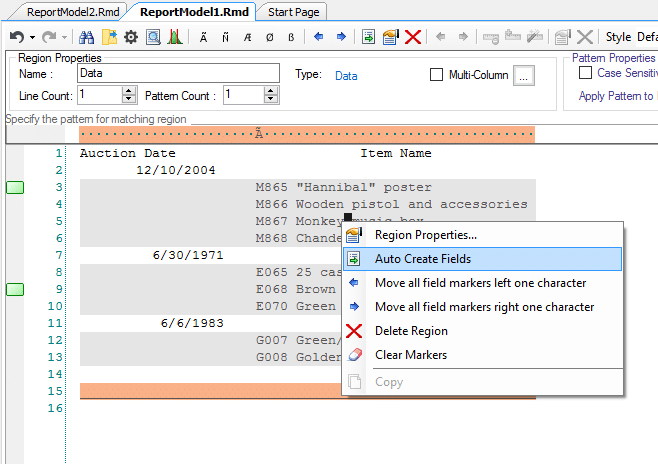
Auto-creation of fields
With instant data preview, Shazz was able to view output data quickly. This helped them create templates that best suited the project’s purpose, and identify errors if any, before the actual execution.
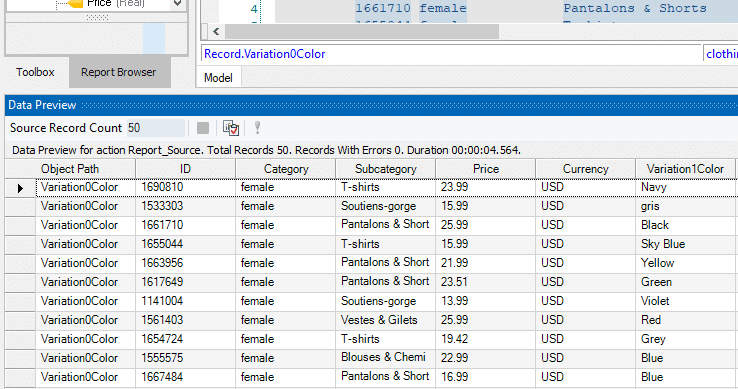
Start Template-Based Data Extraction with ReportMiner
Whether the data in documents reside in a single column or multi-column, with similar format or with disjoint data dets, with proper alignment or with floating fields, Astera ReportMiner is the document extraction software that simplifies template-based extraction for enterprise data. Powered by its industry-grade ETL engine, its automation features allow businesses to handle large volumes of data and scale up easily, and get crucial insights faster.
Get started today with a free, 14-day trial and explore the product’s extensive data extraction features on your own. If you have a use case and would like to discuss it with our experts, feel free to contact us for a no-obligation discovery call.
Authors:
Aelia Haider




 Nov 11th
Nov 11th 