The Automated, No-Code Data Stack
Learn how Astera Data Stack can simplify and streamline your enterprise’s data management.

What is Data Warehousing? Concepts, Features, and Examples
In today’s business environment, an organization must have reliable reporting and analysis of large amounts of data. Businesses collect and integrate their data for different levels of aggregation, from customer service to partner integration to top-level executive business decisions. This is where data warehousing comes in to make reporting and analysis easier.
To understand the importance of data storage, let’s first discuss the important data warehousing concepts.
What is Data Warehousing?
Data Warehousing is the process of collecting, organizing, and managing data from disparate data sources to provide meaningful business insights and forecasts to respective users.
Data stored in the DWH differs from data found in the operational environment. It’s organized so that relevant data is clustered to facilitate day-to-day operations, data analysis, and reporting. This helps determine the trends over time and allows users to create plans based on that information. Hence, reinforcing the importance of data warehouse use to business decision-makers.
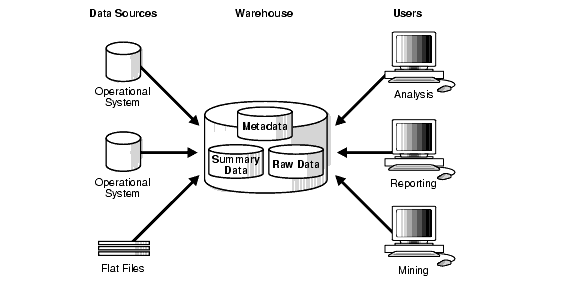
Data Warehouse Architecture
How to Combine Heterogeneous Databases
There are two popular approaches to combining heterogeneous databases:
- Query-driven: A query-driven approach in data warehousing is traditional to creating integrators and wrappers on top of different databases.
- Update-driven: An update-driven approach to integrating data is an alternative to the query-driven approach and is more frequently used today. In this approach, the data from diverse sources is combined or integrated beforehand and stored in a data warehouse. Later, employees can access this data for querying and data analysis.
Data Warehouse Architecture
Data warehouse architecture is the structured design that defines how data is collected, stored, managed, and accessed in a data warehouse. It typically includes:
- Data sources → operational systems, external data, etc.
- ETL/ELT processes → extract, transform, load data into the warehouse.
- Data storage → centralized warehouse or data marts for organized, historical data.
- Metadata & management layer → governs data quality, security, and lineage.
- Presentation layer → reporting, dashboards, and analytics tools.
It uses dimensional models to identify the best technique for extracting and translating information from raw data. However, there are three main types of architecture to consider when designing a business-level real-time data warehouse.
- Single-tier Architecture
- Two-tier Architecture
- Three-tier Architecture
Data Warehouse Features at a Glance
A data warehouse’s key features include the following:
- Subject-Oriented: It provides information catered to a specific subject instead of the organization’s ongoing operations. Examples of subjects include product information, sales data, customer and supplier details, etc.
- Integrated: It is developed by combining data from multiple sources, such as flat files and relational databases.
- Time-Variant: The data in a DWH gives information from a specific historical point in time. Therefore, the data is categorized within a particular time frame.
- Non-volatile: Non-volatile refers to historical data that is not omitted when newer data is added. A DWH is separate from an operational database. This means that any regular changes in the operational database are not seen in the data warehouse.
The Role of Data Pipelines in the EDW
A lot of effort goes into ensuring your data warehouse keeps performing optimally. One strategy involves building reliable, flexible, low-latency ETL pipelines using a metadata-driven ETL approach.
A data warehouse is populated using data pipelines. They transport raw data from disparate sources to a centralized data warehouse for reporting and analytics. Along the way, the data is transformed and optimized.
However, the volume, velocity, and variety increase has rendered the traditional approach to building data pipelines —involving manual coding and reconfiguration — ineffective and obsolete.
Automation is integral to building efficient data pipelines that match your business processes’ agility and speed.
Data Pipeline Automation
You can seamlessly transport data from source to visualization through data pipeline automation. It is a modern approach to populating data warehouses and requires designing functional and efficient dataflows.
As we all know, timeliness is one of the crucial elements of high-quality business intelligence. Automated data pipelines help you make data available in the data warehouse quickly.
You can eliminate obsolete, trivial, or duplicated data by leveraging the power of automated and scalable data pipelines. This maximizes data accessibility and consistency to ensure high-quality analytics.
With a metadata-driven ETL process, you can seamlessly integrate new sources into your architecture and support iterative cycles to fast-track your BI reporting and analysis.
Also, you can follow the ELT approach. In ELT, you can load the data directly to the warehouse to leverage the computing capacity of the destination system to carry out data transformations efficiently.
Optimizing Data Pipelines
An enterprise must focus on building automated data pipelines that can dynamically adapt to changing circumstances—for instance, adding and removing data sources or changing transformations.
Of course, moving entire databases when you need data for reporting or analysis can be highly inefficient.
The best practice is to load data incrementally using change data capture to populate your data warehouse. It helps eliminate redundancy and ensures maximum data accuracy.
Other essential capabilities needed to create automated data pipelines are incremental loading, job monitoring, and job scheduling.
- Incremental loading ensures you don’t have to copy all the data to your data warehouse every time the source table changes. This ensures your data warehouse is always accurate and up-to-date.
- Job monitoring helps you understand any issues with your current system and allows you to optimize the process.
- Job scheduling allows users to process data daily, weekly, monthly, or only when data meets specific triggers or conditions.
Orchestrating and automating your data pipelines can eliminate manual work, introduce reproducibility, and maximize efficiency.
Examples of Data Warehousing in Various Industries
Big data has become vital to data warehousing and business intelligence across several industries. Let’s review some examples of data warehousing in various sectors.
Investment and Insurance sector
Firms primarily use a data warehouse to analyze customer and market trends and other data patterns in these sectors. Forex and stock markets are two major sub-sectors. Here data warehouses play a crucial role because a single point difference can lead to massive losses across the board. DWHs are usually shared in these sectors and focus on real-time data streaming.
Retail chains
Retail chains use DWHs for distribution and marketing. Common uses are tracking items, examining pricing policies, tracking promotional deals, and analyzing customer buying trends. Retail chains usually incorporate EDW systems for business intelligence and forecasting needs.
Healthcare
Healthcare businesses use a DWH to forecast patient outcomes. They also use it to generate treatment reports and share data with insurance providers, research labs, and other medical units. EDWs are the backbone of healthcare systems because the latest, up-to-date treatment information is crucial for saving lives.
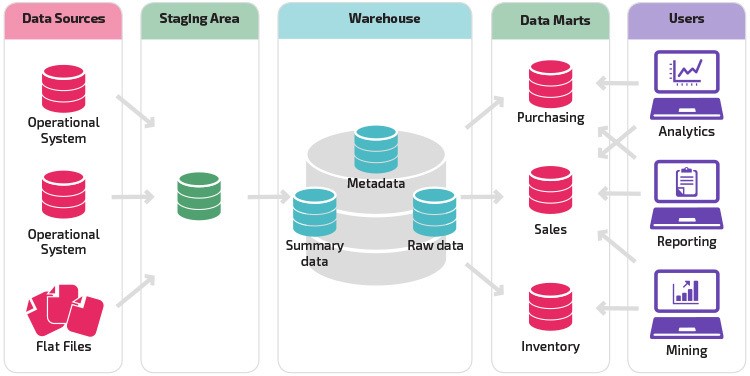
Types of Data Warehouses
There are three main types of data warehouses. Each has its specific role in data management operations.
1- Enterprise Data Warehouse
An enterprise data warehouse (EDW) is a central or main database to facilitate decisions throughout the enterprise. Key benefits of having an EDW include the following:
- Access to cross-organizational information.
- The ability to run complex queries.
- The enablement of enriched, far-sighted insights for data-driven decisions and early risk assessment.
2- ODS (Operational Data Store)
In ODS, the DWH refreshes in real time. Therefore, organizations often use it for routine enterprise activities, such as storing records of employees. Business processes also use ODS to provide data to the EDW.
3- Data Mart
It is a subset of a DWH that supports a particular department, region, or business unit. Consider this: You have multiple departments, including sales, marketing, product development, etc. Each department will have a central repository where it stores data. This repository is a data mart.
The EDW stores the data from the data mart in the ODS daily/weekly (or as configured). The ODS acts as a staging area for data integration. It then sends the data to the EDW to store for BI purposes.
warehouse in 4 easy steps
Why do Businesses Need Data Warehousing and Business Intelligence?
A lot of business users wonder why data warehousing is essential. The simplest way to explain this is through the various benefits to the end-users. These include:
- Improved end-user access to a wide variety of enterprise data
- Increased data consistency
- Additional documentation of the data
- Potentially lower computing costs and increased productivity
- Providing a place to combine related data from separate sources
- Creation of a computing infrastructure that can support changes in computer systems and business structures
- Empowering end-users to perform ad-hoc queries or reports without impacting the performance of the operational systems
Data Warehousing Tools and Techniques
The data infrastructure of most organizations is a collection of different systems. For example, an organization might have one system that handles customer relationships, human resources, sales, production, finance, partners, etc. These systems are often poorly or not integrated at all. This makes it difficult to answer simple questions even though the information is available “somewhere” within the disparate data systems.
Enterprises can use DWH tools to solve these issues by creating a single database of homogeneous data. The software tools for extracting and transforming the data into a homogeneous format for loading into the DWH are also vital components of a data warehousing system.
Enterprise Data Warehousing Automation Tool by Astera
Astera Data Warehouse Builder expedites data warehousing by unifying sources, transformations, and destinations in one intuitive platform. It provides drag-and-drop modeling and pipeline design, or you can simply ask its chat-based AI to generate models and pipelines using natural-language prompts.
ADWB also comes with built-in data cleansing and validation, plus a mapping UI that gives you full control over exact or semantic source-to-target mappings. Whether you’re a developer or a business user, you can skip the heavy SQL coding, cut down on manual errors, and move from design and testing to deployment much faster.
ADWB is a metadata-driven data warehousing automation tool with a rich data modeler and includes all the key features of a data warehouse mentioned above. The reverse-engineer functionality allows users to create databases in a few clicks without writing codes. Similarly, users can quickly develop schemas from scratch with the easy drag-and-drop option. The images below briefly depict how the ADWB works.
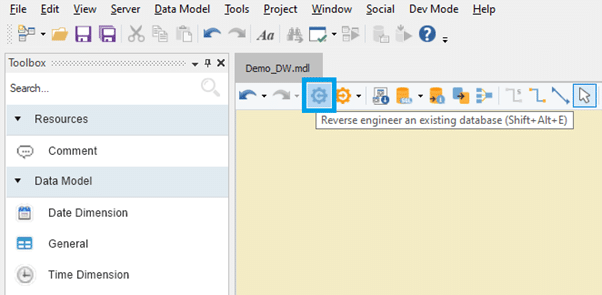
Reverse-engineering feature in Astera DWB
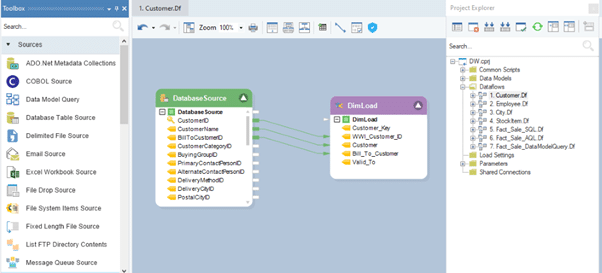
Dataflow to populate dimension table in ADWB
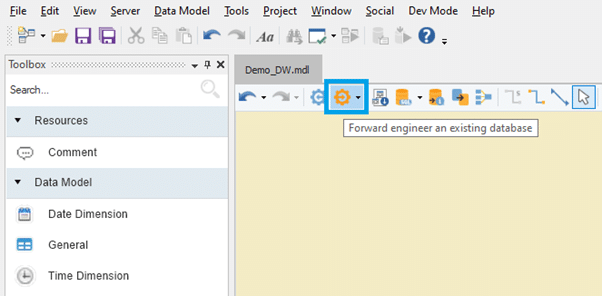
Once the schema is built and data is populated, the data model can be forward engineered just as quickly to the business’ database.
Learn more about how to build your data warehouse from scratch with Astera Data Warehouse Builder, a high-performance solution that facilitates all your business needs. For a personalized experience, contact us to discuss your specific use case and find out how Astera can help!
How do I get started with or evaluate a data warehousing solution?
Is data warehousing secure and compliant?
How often should my data warehouse be updated: batch or real-time?
What is the difference between ETL and ELT, and which should I choose?
What role do data pipelines play, and why should they be automated?
Authors:
Astera Marketing Team