
The Automated, No-Code Data Stack
Learn how Astera Data Stack can simplify and streamline your enterprise’s data management.

Document Data Extraction 101: Understanding the Basics

What is Document Data Extraction?
Document data extraction refers to the process of extracting relevant information from various types of documents, whether digital or in print. It involves identifying and retrieving specific data points such as invoice and purchase order (PO) numbers, names, and addresses among others.
The process enables businesses to unlock valuable information hidden within unstructured documents. The ultimate goal is to convert unstructured data into structured data that can be easily housed in data warehouses or relational databases for various business intelligence (BI) initiatives.
Types of Documents
A typical business deals with various unstructured documents. Some of these documents include:
- Invoices and POs: Key information extracted from these documents often include vendor details, including names, contact information, tax numbers, invoice and PO numbers, line-item details, discounts, subtotals, and payment terms.
- Legal Documents: Contracts, licensing agreements, service-level agreements (SLA), and non-disclosure agreements (NDA) are some of the most common legal documents that businesses extract data from.
- Healthcare Records: These include medical documents, such as electronic health records (EHR), prescription records, and lab reports, among others.
- Banking and Finance Documents: Typically, these include financial statements, loan applications, and account opening application forms.
- Insurance Documents: Insurance companies frequently extract data from insurance applications, policy documents, claim forms, and medical records.
Manual Document Data Extraction
Before the advent of automated extraction technologies, manual methods were the primary way to extract data from documents. While manual extraction provides control and flexibility, it is an error-prone and time-consuming endeavor.
There are two ways to extract data from documents manually:
- Manual Data Entry: This method involves manually entering data from documents into a digital format. It is a labor-intensive process prone to human errors and requires significant resources.
- Copy-pasting: Data is manually copied from documents and pasted into the desired digital format. While it may save some time compared to manual data entry, it is still rife with errors and limits scalability.
Limitations of Manual Document Data Extraction
Besides being error-prone and time-consuming, manual document data extraction has several other challenges and limitations, including:
- Lack of Scalability: Manual methods are not scalable, making it challenging to handle increasing volumes of documents efficiently.
- High Costs: Manually extracting data requires significant human resources, leading to higher costs associated with labor.
- Subjectivity and inconsistency: Human operators will likely have different interpretations and judgments when extracting data from documents, leading to inconsistencies and variations in the extracted information.
- Dependence on skilled resources: Manual extraction often requires experienced operators with domain knowledge to understand the context and extract relevant data accurately. Finding and retaining such resources can be challenging, especially for niche industries or specialized document types.
- Reduced productivity and job satisfaction: Due to its repetitive and monotonous nature, manually extracting data leads to decreased productivity and job satisfaction. This can result in increased fatigue and burnout, further impacting the accuracy and efficiency of the extraction process.
The Shift to Automated Document Data Extraction
Businesses today deal with many documents as part of their operations. Even a medium-sized company can receive hundreds of invoices, POs, or other documents from its vendors every month. Manual data extraction approach can no longer keep up, which is why it is important to embrace automation.
Automated Document Data Extraction Technologies
Automated document data extraction pulls required information from different documents, typically leveraging technologies such as artificial intelligence (AI) and machine learning (ML). Different automated extraction technologies utilize different techniques to extract data from documents with varying levels of accuracy.
Optical Character Recognition (OCR)
Optical Character Recognition (OCR) converts scanned images of text into machine-readable text. For example, businesses can use OCR software to analyze the images of different documents and translate them into digital text, making it possible to extract data from scanned documents.
Businesses also use Intelligent Character Recognition (ICR), also called advanced OCR, when dealing with handwritten documents. ICR converts handwritten characters into machine-readable text with high accuracy.
AI-Based Technologies
Along with OCR and ICR, businesses use various AI-based data extraction techniques depending on their requirements. These techniques help enhance extraction accuracy by enabling systems to understand the context and meaning of the text. AI technologies most used by businesses include:
- Machine Learning: ML is a subset of AI that involves training algorithms to learn from data and make predictions or decisions without explicit programming. ML algorithms are employed in document data extraction to recognize patterns, extract relevant information, and improve accuracy over time. Within the realm of ML, template-based data extraction is another technique that extracts required information based on pre-defined templates.
- Natural Language Processing (NLP): NLP is the branch of AI that focuses on the interaction between computers and human language. It involves programming computers to process and understand large amounts of natural language data. NLP utilizes AI techniques, such as text classification and sentiment analysis, to analyze text and extract relevant information from unstructured documents.
- Intelligent Document Processing Platforms: Intelligent Document Processing (IDP) platforms integrate multiple AI technologies to automate the document data extraction process. For example, an IDP platform may use a combination of all or some of the abovementioned AI-based technologies to extract data. These platforms utilize AI algorithms to improve extraction accuracy over time continuously.
The Process
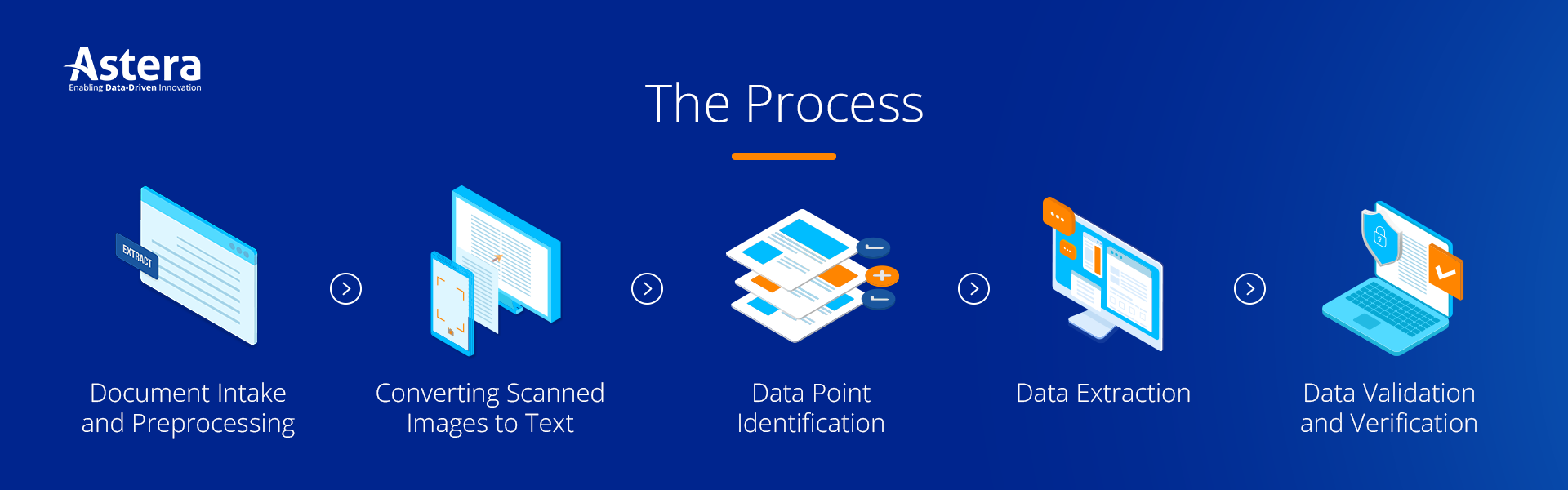
The Document Data Extraction Process
Automated document data extraction involves combining multiple techniques, tools, and algorithms to obtain the required information from complex documents. Here are the key steps:
- Document Intake and Preprocessing: The process begins with gathering and preparing the documents for extraction. Preprocessing can involve tasks such as image enhancement and noise reduction.
- Converting Scanned Images to Text: Optical Character Recognition (OCR) then converts scanned images or PDFs into editable text.
- Data Point Identification: This involves defining the specific data points or fields to be extracted from the document by identifying relevant information.
- Data Extraction: Various document data extraction techniques, including parsing, pattern matching, and rule-based extraction, are applied to extract the identified data accurately. Data parsing involves analyzing the structure of the document to identify and extract relevant data. At the same time, pattern matching matches specific patterns or formats to extract data.
- Data Validation and Verification: Post extraction, the data is validated and verified to ensure accuracy and consistency by comparing the extracted data against pre-defined validation rules and performing data quality checks.
Best Practices to Optimize the Process
Consider the following best practices to maximize extraction accuracy and efficiency:
- Utilize high-quality document scans or images to achieve better OCR results and improve data extraction accuracy.
- Regularly update and train machine learning models with diverse and representative data sets to adapt them to new document layouts and formats, improving extraction performance over time.
- Use a hybrid extraction approach to maximize extraction accuracy. For example, use rule-based extraction for structured data fields with predictable patterns and ML algorithms for handling unstructured or complex data.
- Implement robust data validation mechanisms to ensure data accuracy and integrity.
- Make sure that the data extraction process is designed in a way that it can handle large volumes of documents without breaking down.
Benefits of Automated Document Data Extraction
Automated document data extraction enables businesses to effortlessly process and extract data from multiple types of documents and their variations, requiring minimal manual intervention.
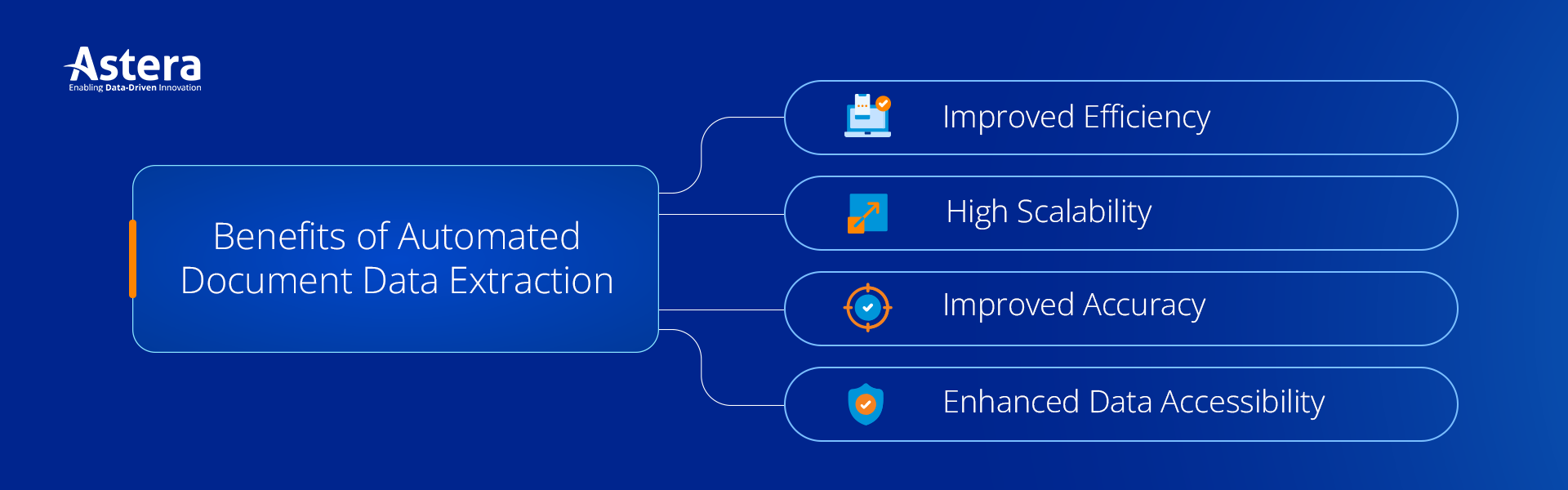
Benefits of Automated Document Data Extraction
It offers numerous advantages over manual methods, including:
- Improved Efficiency: By eliminating manual tasks, automated extraction reduces document processing time and costs associated with labor. It also allows resource allocation to more valuable activities.
- High Scalability: Automated extraction solutions can handle large volumes of documents consistently and efficiently, ensuring scalability as the business and number of documents continue to grow.
- Improved Accuracy: With automated document data extraction, businesses minimize human errors and inconsistencies in their data, ensuring higher data accuracy. As a result, they get high-quality data and they reduce the risk of costly mistakes and rework.
- Enhanced Data Accessibility: Extracted data can be easily accessed, organized, and analyzed. It provides valuable insights, facilitating data-driven decision-making.
- Flexibility and adaptability: Automated data extraction systems can be configured and trained to handle different document types and layouts. They offer flexibility and adaptability, enabling organizations to process diverse document sources efficiently.
Apart from automatically extracting relevant information, automated document data extraction solutions offer another significant benefit to businesses—they can seamlessly integrate with existing systems, including ERPs, CRMs, and more. This integration streamlines dataflows by automating workflows, enabling efficient data processing and analysis.
Use Cases
Extracting key information from documents at scale is an important data management task across industries, as it can significantly improve operational efficiency. Given the benefits it offers, automated document data extraction has applications in:
Financial Services
Automated document data extraction can accelerate multiple tasks in the financial sector by reducing manual effort. These tasks commonly include invoice processing, expense management, and loan application processing.
In banking and finance, document data extraction streamlines loan and mortgage processing. Analysts and auditors frequently need to access financial statements and reports for analysis and audit, making accurate data extraction from these documents a top priority.
Healthcare
Obtaining accurate healthcare data is especially important as it can impact patient outcomes. Automated document data extraction delivers accurate patient data quickly from a large number of medical records. It can also help automate the population of electronic health records and enable faster processing of insurance claims, reducing administrative burden.
Additionally, healthcare organizations need to consolidate and analyze patient health information and data, such as disease prevalence, to facilitate ongoing research programs and clinical trials. This enables them to gain actionable insights, leading to streamlined operations and enhanced patient care. All of this can be accelerated with automated document data extraction.
Logistics and Supply Chain
In the logistics and supply chain industry, automated document data extraction plays a vital role in extracting relevant information from shipping documents, invoices, and customs forms. It can also help track shipments and automate inventory management, improving supply chain visibility.
Legal
Law firms and legal departments deal with massive amounts of various legal contracts and agreements. With automated document data extraction, they can quickly analyze and extract key information about parties involved, legal clauses, key terms and conditions, and important dates. This simplifies the due diligence process, ultimately improving productivity.
Insurance
Automated document data extraction assists insurance companies in extracting relevant information from insurance claim forms. This streamlines the claim intake process, expedites assessment, and enables faster claims settlement.
How Astera ReportMiner Can Help
Astera ReportMiner is an industry-leading document data extraction platform capable of handling a variety of different types of documents seamlessly. Its advanced Auto Generate Layout (AGL) feature, powered by AI Capture, automates data extraction from complex and unstructured documents.
With ReportMiner, you get:
- An intuitive, user-friendly interface
- Automation and workflow orchestration
- Seamless template creation, verification, and adjustment
- A simplified way to specify the data layout
Whether it’s streamlining invoice processing or obtaining critical information from other business documents, Astera ReportMiner makes document data extraction effortless.
Try ReportMiner or get in touch with our sales team directly.
Authors:
Khurram Haider



 Nov 11th
Nov 11th 