
The Automated, No-Code Data Stack
Learn how Astera Data Stack can simplify and streamline your enterprise’s data management.

What is Star Schema? Advantages and Disadvantages
What is a Star Schema?
Introduced in 1996 by Ralph Kimball, a star schema is a multi-dimensional data modeling technique. It is the simplest schema type businesses use in data warehousing.
Based on its name, a star schema is like a star when visualized. It has a fact table in the middle and many dimension tables attached to it. This simple, denormalized structure makes it very efficient for querying data.
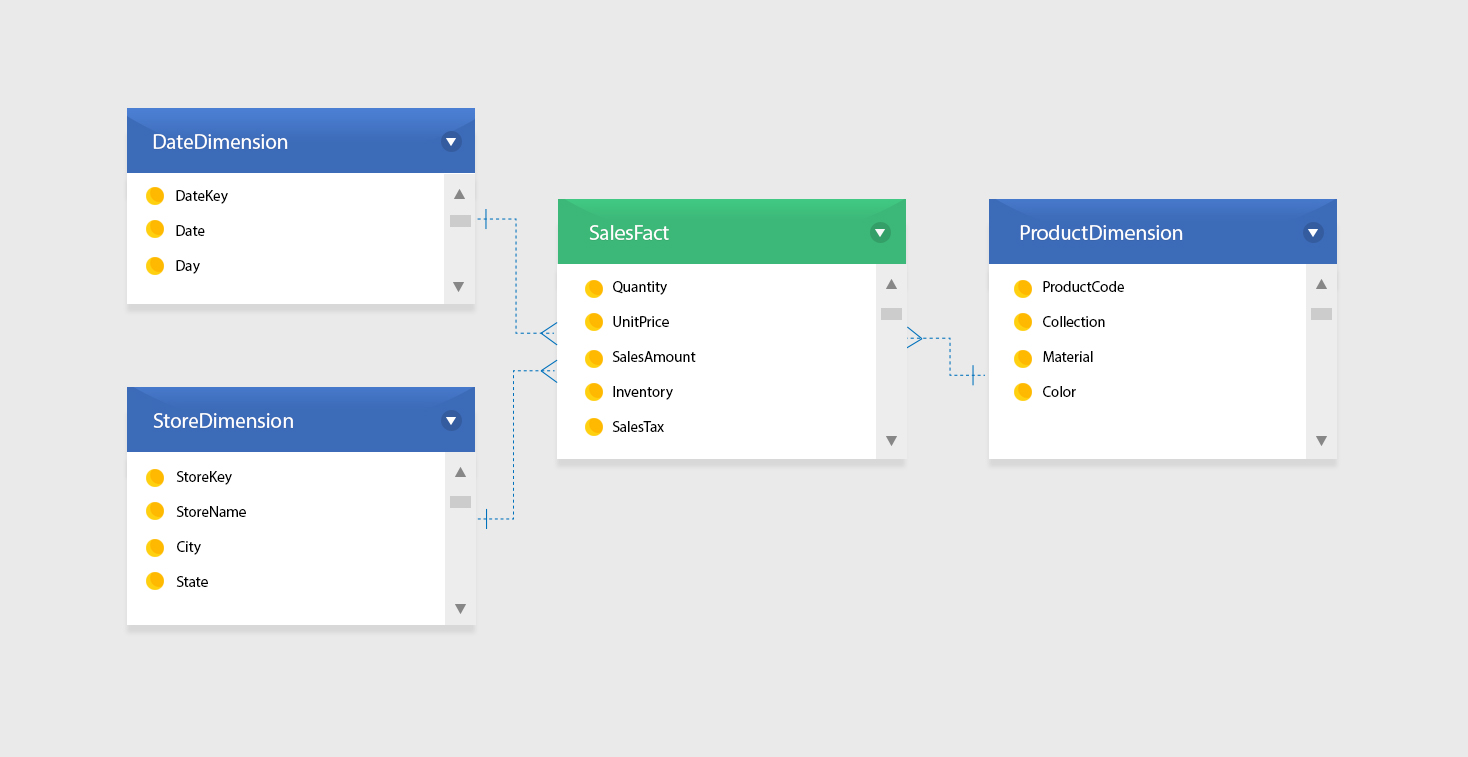
Star schema with fact and dimension tables
Star Schema Structure: Fact and Dimension Tables
Fact Tables
Fact tables, or fact entities, serve as the centerpiece of the star schema. A typical fact table contains quantitative data or metrics that represent business events, transactions, or measurements. These facts are typically numeric values, such as sales revenue, profit, or units sold.
We can see an example of a fact table below. It contains measurable facts, such as the price of a unit sold and the sales tax.
| Date | Store Location | Product Type | Quantity | Unit Price | Sales Amount | Inventory | Sales Tax |
| 8/4/2023 | CA | Nylon | 5 | 100 | 500 | 30 | 7.75% |
| 8/4/2023 | CA | Polyester | 7 | 250 | 1750 | 50 | 7.75% |
| 8/4/2023 | PA | Nylon | 6 | 100 | 600 | 65 | 6.00% |
Dimension Tables
Dimension tables are the auxiliary tables that provide context and descriptive attributes for the data in the fact table. They help to answer questions like “who,” “what,” “when,” “where,” and “how” related to business events. Dimension tables hold categorical data, like customer names, product categories, time periods, and geographic locations.
Example: the two dimension tables below provide details on the product info in the fact table above.
| Date Dimension | ||
| Date Key | Date | Day |
| 10201 | 8/4/2023 | Saturday |
| 10202 | 8/4/2023 | Saturday |
Dimension table for Date
| Store Dimension | |||
| Store Key | Store Name | City | State |
| 151 | AngAngie’sparel | Los Angeles | California |
| 152 | AngAngie’sparel | Pittsburgh | Pennsylvania |
Dimension table for Store
Advantages of Using Star Schemas
-
Simplified querying: Star schemas are easy to understand and implement. Their denormalized structure reduces the number of joins required to retrieve data. This simplifies and leads to faster data aggregation and reporting.
- Faster performance: The reduced join complexity and efficient indexing of fact and dimension tables enhance data retrieval. This is particularly important for decision-makers who require quick access to insights.
- Intuitive analysis: Star schemas enable intuitive and straightforward data analysis. Users can easily understand relationships and hierarchies among dimensions.
- Robust support: Star schemas provide support for OLAP structures such as data cubes – multi-dimensional arrays used to improve data analysis.
Disadvantages of Using Star Schemas
- Lack of integrity: Denormalization can cause data redundancy. Dimensional attributes are often repeated across multiple records within a dimension table which can cause data quality issues. Since data is duplicated in denormalization, frequent changes can also cause certain tables to display out-of-date information.
- Increased costs: Adding redundant data increases computing and storage costs. This can be especially troubling when handling large datasets.
- Limited flexibility: Star schemas are relatively less robust than normalized structures since they are built for specific use cases. Other approaches might be more effective for complex querying involving multiple joins.
- Maintenance difficulties: As data changes over time, maintaining a star schema can become challenging. Updates to dimension attributes might require changes in multiple places.
When to Use Star Schema
This dimensional modeling technique is the best option when:
- Users have a clear understanding of the required data. For example: the number of products sold by state.
- The data is structured and quantitative with some categorical attributes.
- They want the data quickly and easily, without creating multiple joins. Query performance is the top priority.
- Data redundancy will not be an issue.
Analysts and business users that want higher data rigidity can opt for a more normalized approach. Snowflake schema is an extension of star schema – it comprises of a normal star model with additional sub-dimension tables.
Snowflake schemas use a more normalized approach suitable for less redundancy and more complex queries.
Learn more about the pros and cons of Star Schema vs. Snowflake Schema and when to use them.
Conclusion
Star schemas are but one approach to dimensional modeling. Other approaches, like snowflake and 3NF, are also widely used in building data marts and data warehouses. The important task for data teams is to find the best approach based on their use case and resources.
Selecting the right modeling technique is vital in automating data warehousing and BI initiatives. Check out our toolkit guide on creating effective data models and pipelines for data warehouse automation and improving your reporting and analytics.
Authors:
Junaid Baig




 Oct 2nd
Oct 2nd 