
The Automated, No-Code Data Stack
Learn how Astera Data Stack can simplify and streamline your enterprise’s data management.

ETL Batch Processing: A Comprehensive Guide
Did you know that the world is creating more data than ever before? If you want to know the exact figures, data is estimated to grow beyond a staggering 180 zettabytes by 2025! Handling all that information needs robust and efficient processes. That’s where ETL comes in. ETL—Extract, Transform, Load— is a pivotal mechanism for managing vast amounts of information. Now, imagine taking this powerful ETL process and putting it on repeat so you can process huge amounts of data in batches. That’s ETL batch processing. Let’s explore this topic further!
What is ETL?
ETL refers to a process used in data integration and warehousing. It gathers data from various sources, transforms it into a consistent format, and then loads it into a target database, data warehouse, or data lake.
- Extract: Gather data from various sources like databases, files, or web services.
- Transform: Clean, validate, and reformat the data for consistency and quality.
- Load: Transfer the transformed data into a target database or warehouse for analysis and reporting.
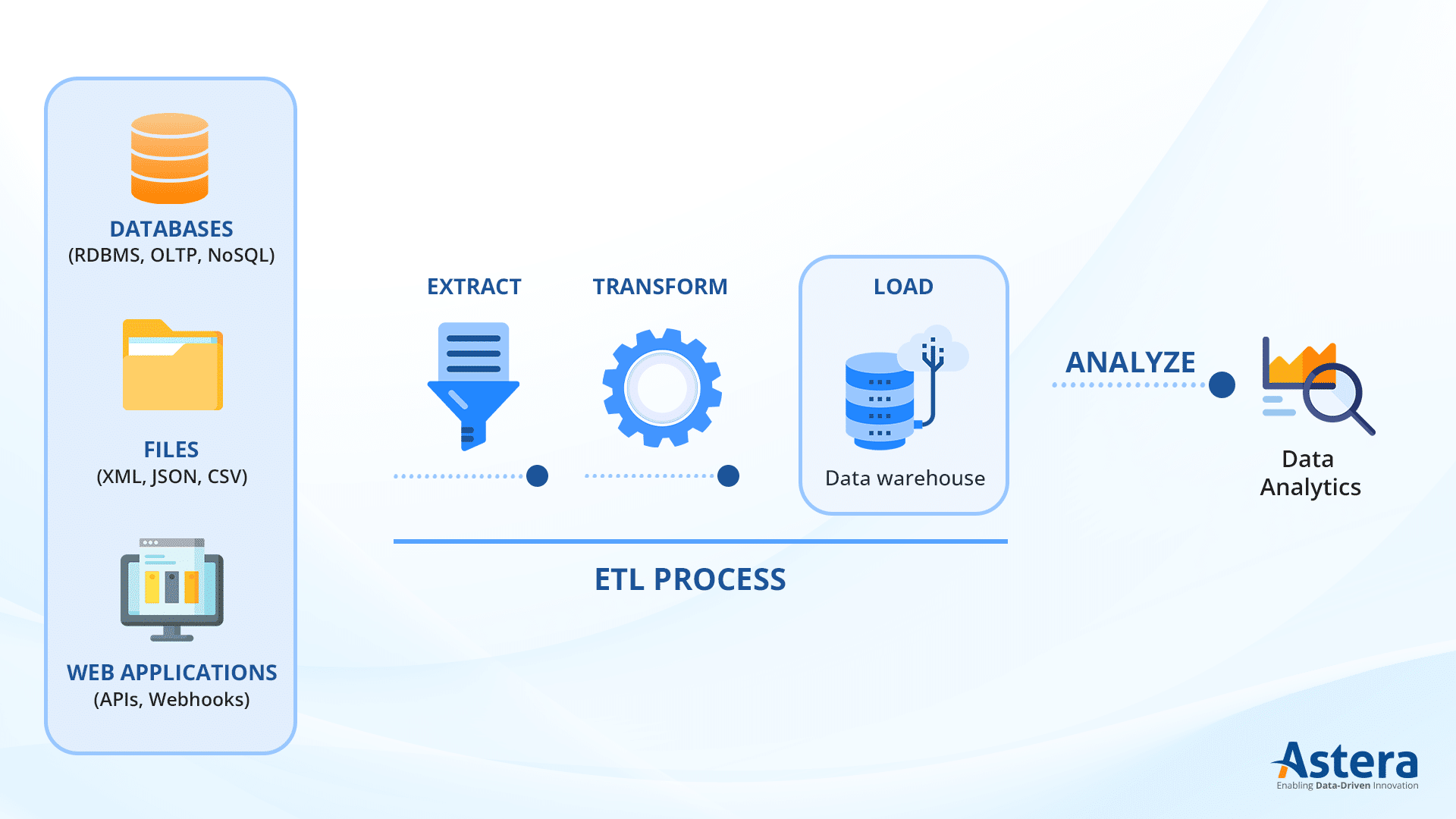
What is ETL Batch Processing?
ETL batch processing involves handling data in predefined chunks or batches instead of real-time. It collects data over specific periods—like hourly or daily intervals—and then processes it as a batch. It’s particularly useful when real-time processing isn’t essential or when dealing with large volumes of data that demand significant processing time.
Batch processing is efficient for handling large volumes of data as it provides ample time for comprehensive data transformation and quality checks and ensures that only clean and accurate data is loaded into the target system. Since it doesn’t demand immediate processing upon data arrival, it can be scheduled during off-peak hours, reducing system strain and optimizing resource usage.
Batch processing is an ideal strategy when workloads are predictable and can be forecasted in advance. It is also well-suited for generating periodic reports and analytics, as it provides insights into historical trends and patterns rather than immediate updates.
How does ETL Batch Processing work?
When it comes to ETL batch processing, the workflow generally consists of three main ETL steps: extraction, transformation, and loading.
- Extraction
In this step, data is extracted from various sources such as databases, files, APIs, or web services, based on predefined criteria, such as specific tables, files, or time frames. ETL tools such as Astera extract the required information from databases. These no-code tools can make data extraction simple, whether it is just selecting all rows from a table, or as complex as joining multiple tables and applying filters. The extracted data is then fetched and stored in memory or temporary files, ready for the next step. When it comes to extracting data from files, ETL tools support a wide range of formats, such as CSV, Excel, XML, JSON, and more. The tools parse these files, extracting the relevant data and converting it into a structured format that can be easily processed further. Additionally, ETL tools can also extract data from external sources such as APIs or web services. They make HTTP requests to retrieve data in a specific format, such as JSON or XML, and then parse and extract the required information. - Transformation
Once the data is extracted, it goes through a transformation process, which involves cleaning the data, validating its integrity, and transforming it into a standardized format so that it is compatible with the target database or data warehouse. Data cleaning is an important aspect of the transformation process. It involves removing any inconsistencies, errors, or duplicates from the extracted data. ETL tools provide various functionalities to handle data cleaning, such as removing special characters, correcting misspellings, or applying data validation rules. It is important to ensure data integrity during the transformation process. You need to check for referential integrity and data type consistency and ensure that the data adheres to business rules or constraints. You can automate the process if you are using an ETL tool. Furthermore, the transformation process often involves enriching the data by combining it with additional information through lookups in reference tables, merging data from multiple sources, or applying complex calculations or aggregations. - Loading
The final step is to load the transformed data into the target system, such as a data warehouse, a database, or any other storage system that allows for efficient analysis and reporting. When loading data into a data warehouse, ETL tools use various techniques to optimize performance. They employ bulk loading methods, which allow for faster insertion of large volumes of data. Additionally, they utilize indexing strategies to improve query performance and enable efficient data retrieval. ETL tools also provide mechanisms for handling data updates and incremental loading. This means that only the changed or newly added data is loaded into the target system, minimizing the processing time and reducing the impact on system resources.
Streaming ETL Processing
Streaming ETL processing, also known as real-time ETL or continuous ETL, involves handling data in a continuous flow rather than in batches. It’s designed to process and analyze data as it arrives, enabling near-instantaneous transformations and loading into the target system. Streaming ETL is valuable in scenarios where real-time or near real-time insights are essential, such as:
- Fraud Detection: Analyzing transactions in real-time to detect fraudulent activities.
- IoT Data Processing: Handling and analyzing data from sensors or connected devices as it arrives.
- Real-time Analytics: Making immediate business decisions based on the most current data.
- Log Monitoring: Analyzing logs in real-time to identify issues or anomalies.
By processing data as it streams in, organizations can derive timely insights, react promptly to events, and make data-driven decisions based on the most up-to-date information.
Batch Processing vs. Streaming Processing
Whether you choose batch processing or streaming processing depends on your use case and the capacity of your processor. Here is a list of differences between the two to help you make an informed choice:
Data Size
Batch processing deals with large, predefined data sets while streaming processing manages smaller, continuous data streams. The finite nature of batch data makes it easier for bulk operations, whereas streaming processing adapts to potentially infinite and variable data volumes, demanding a more adaptable approach.
Time of Execution
ETL batch processing tackles data in bulk at scheduled intervals or manually triggered, contrasting with streaming ETL, which instantly starts processing upon the introduction of new records. Batch operations are discrete and periodic, while stream operations run continuously as data arrives.
Processing Time
Batch ETL can span minutes to hours while streaming ETL completes tasks within milliseconds or seconds. Batch processing shines when dealing with massive data volumes, while streaming’s real-time analytics, like in fraud detection, prompt immediate action.
Data Processing Order
Batch processing lacks sequential processing guarantees, which can potentially alter the output sequence. Stream ETL ensures real-time data processing in the order it’s received, which is crucial for maintaining data accuracy, notably in financial services where transaction order matters.
Here’s a comparison table summarizing the key differences between ETL batch processing and streaming ETL processing:
| ETL Batch Processing | Streaming ETL Processing | |
|---|---|---|
| Latency | Higher (minutes to days) | Lower (seconds to milliseconds) |
| Data Size | Handles large, finite data sets in bulk | Manages smaller, continuous, and potentially infinite data streams |
| Time of Execution | Processes data in bulk at scheduled intervals | Instantly starts processing upon arrival of new records |
| Processing Time | Longer (minutes to hours) | Shorter (milliseconds to seconds) |
| Data Processing Order | Doesn’t ensure the original data sequence | Processes data in real-time in the order it arrives |
| Suitability | Well-suited for handling massive data quantities | Ideal for real-time analytics and immediate actions. |
How to Build an ETL Pipeline with Batch Processing
Building an ETL pipeline for batch processing involves several steps. Here’s a general outline of the process:
- Understanding Requirements: Define data sources and destinations and determine the batch run frequency to establish the ETL’s framework.
- Extract Data: Retrieve data from various sources, ensuring integrity and compliance with defined criteria in batches.

- Transform Data: Clean, filter, aggregate, and apply business logic while normalizing formats as necessary.
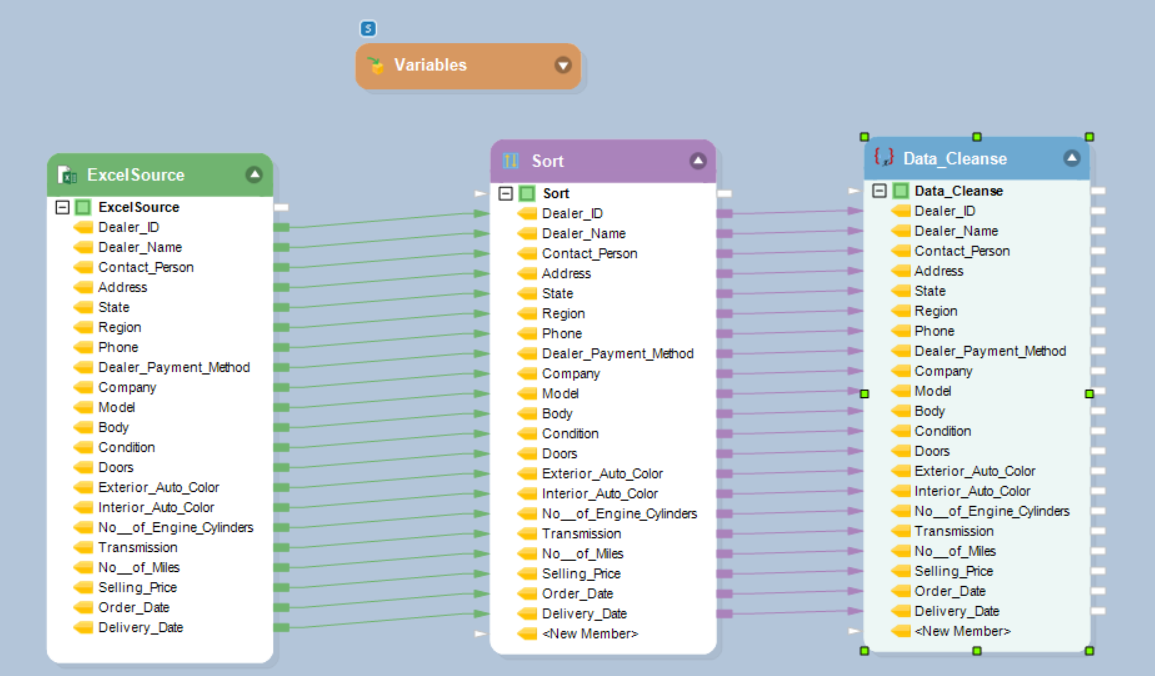
- Load Data: Prepare and update destination schemas, loading transformed data in batches into storage.
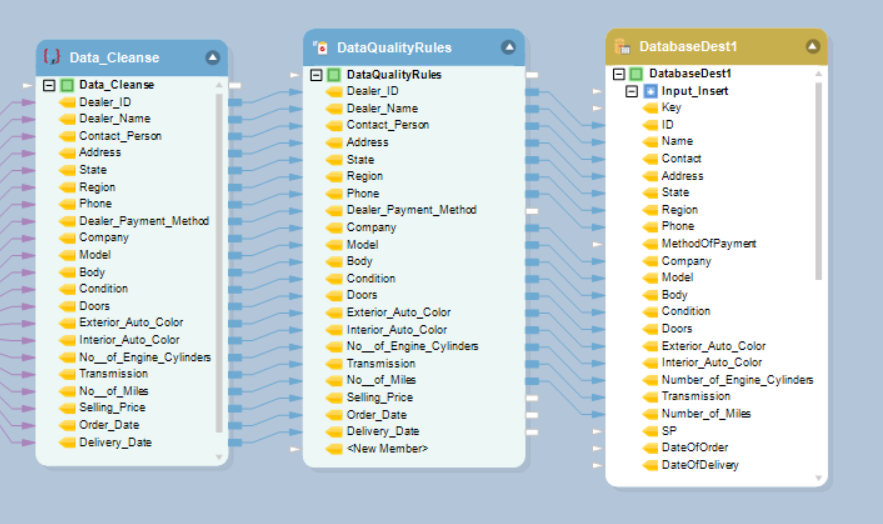
- Orchestration: Utilize workflow tools for managing and scheduling batch runs and monitoring for quality and performance.
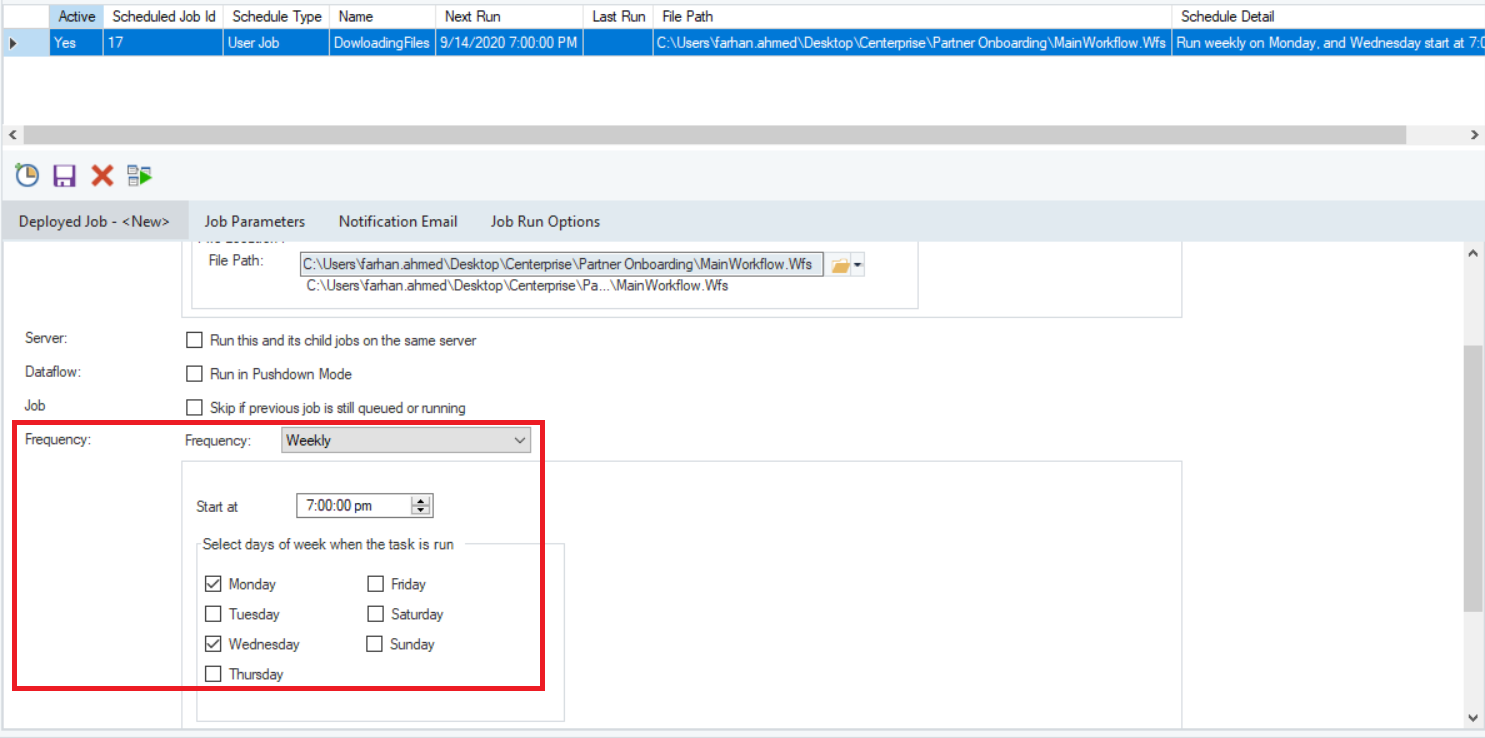
- Error Handling and Monitoring: Implement mechanisms to address inconsistencies and failures, monitor performance, and generate alerts for anomalies.
- Optimization and Scalability: Regularly optimize for better performance and scalability, adapting to larger data volumes or new sources.
- Testing and Validation: Thoroughly test and validate the ETL pipeline to ensure accurate, complete, and consistent output.
For more clarity, here is a step-by-step guide to using Astera to Create and Orchestrate an ETL Process for Partner Onboarding with product screenshots.
Use Cases of ETL Batch Processing
Let’s explore some common scenarios where ETL batch processing is widely used.
Healthcare Data Management
In healthcare, ETL batch processing is used to aggregate patient records, medical histories, treatment data, and diagnostics from diverse sources. This supports comprehensive analysis for better patient care, research, and compliance with regulatory standards like HIPAA. Batch processing generates periodic reports and analytics that provide insights into trends, outcomes, and performance over specific time intervals.
Logistics and Supply Chain Management
Batch processing helps optimize logistics operations by analyzing supply chain data. It supports the regular update of inventory data, allowing organizations to reconcile stock levels, identify discrepancies, and adjust inventory records in a controlled and efficient manner. It also provides a structured and organized way to exchange data between supply chain partners. Batch files can be transmitted at agreed-upon intervals which improves collaboration while minimizing the impact on real-time operations.
E-commerce and Retail
For e-commerce businesses, ETL aids in analyzing transactional data, customer behavior, purchase patterns, and product preferences. This enables targeted marketing strategies, personalized recommendations, and inventory management based on consumer trends.
Social Media and Marketing Analysis
ETL batch processing assists in analyzing social media data to gauge customer sentiment, engagement metrics, and the effectiveness of marketing campaigns. It consolidates data from multiple platforms to derive actionable insights for marketing strategies.
Real-time Data Processing Augmented by Batch Analysis
While ETL batch processing typically operates on scheduled intervals, it also complements real-time data processing. Batch analysis of collected real-time data offers deeper insights, allowing businesses to derive trends, patterns, and predictive models for future strategies.
Compliance and Regulatory Reporting
In industries subject to stringent regulations like finance and healthcare, batch processing ensures the consolidation and accurate reporting of data required for compliance. This includes generating reports, audits, and regulatory submissions from diverse data sources.
Educational Institutions and Learning Management Systems
For educational institutions and online learning platforms, ETL aids in consolidating student records, course data, assessments, and learning analytics. It supports personalized learning experiences, performance tracking, and curriculum improvements.
Astera—the Automated ETL Solution for All Businesses

Astera is a 100% no-code ETL solution that streamlines the creation of comprehensive data pipelines. The platform seamlessly integrates data from diverse sources—be it on-premises or in the cloud—enabling effortless movement to preferred destinations such as Amazon Redshift, Google BigQuery, Snowflake, and Microsoft Azure. Astera’s prowess lies in its ability to construct fully automated ETL pipelines, accelerate data mapping through AI Auto Mapper, establish connections across multiple sources and destinations, elevate data quality for a reliable single source of truth, and effortlessly manage vast data volumes with its parallel processing ETL engine. Here are some of the key features:
- Visual Interface that simplifies the end-to-end data management process, allowing for drag-and-drop functionality at every stage of the ETL lifecycle.
- Extensive connectors, ensuring seamless connectivity to diverse data sources and destinations including databases, applications, and cloud services.
- Built-in Scheduler, which allows you to run your jobs once, in batch processing or repetitively according to selected schedule. Among the available schedules are: ”Run Once”, ”Hourly”, ”Daily”, ”Weekly”, ”Monthly”, and ”When file is dropped”.
- Advanced data validation capabilities that ensure data accuracy and integrity throughout the integration process by enabling users to define and implement complex validation rules.
Ready to build end-to-end ETL pipelines with a 100% no-code data pipeline builder? Download a 14-day free trial or sign up for a demo.
Streamline your ETL Pipelines
Whether its streaming processing or batch processing – Astera Centerprise allows you to streamline your ETL processes, providing connectivity to multitudes of sources, automation, scheduling and more – without writing a single line of code!
Learn more about Centerprise!
Authors:
Abeeha Jaffery




 Oct 2nd
Oct 2nd 