
The Automated, No-Code Data Stack
Learn how Astera Data Stack can simplify and streamline your enterprise’s data management.

Introducing the New Dynamic Layout Feature in Astera Centerprise 8.0
In a conventional ETL or ELT pipeline, all data mapping is tightly bound to a statically defined schema. Data types, number of columns, and column names are generated based on the original layout of corresponding source tables.
Under this approach, any modifications in source files or tables must be manually reflected in related dataflows and workflows. While these tasks are generally limited, in situations where transactional data is being received from various locations, some input feeds may contain additional columns or follow different recording conventions for specific fields. What’s more, concerned departments are usually more than willing to adjust how their data is communicated on an ongoing basis.
With static layouts in place, users may be required to make several manual adjustments to their existing data mappings and transformations to resolve the updated schema’s deviations.
Astera’s new dynamic layout option streamlines these time-consuming tasks with intuitive features that allow parameter configuration for source and destination entities. All changes are automatically propagated throughout linked data maps. These changes are initiated based on the paths and relationships that are already incumbent on existing fields within your dataflows and workflows, regardless of the visible structure of source entities.
With dynamic layouts enabled, these differentials can be automatically identified and implemented in your ETL and ELT processes without disrupting your data integrations.
Dynamic Layout Use Cases
We’ve identified several scenarios in which the ability to automate structural changes to layouts would be advantageous to our users. Potential uses for this feature include:
- Quickly updating dataflow layouts when columns are added, removed, or modified at the source.
- Performing similar processes (cleansing, transformations, migrations) across multiple dataflows with minimal manual adjustment.
- Creating a dynamic ETL or ELT process that automatically picks disparate files from a given location and loads them into new destinations.
These use cases are explained in more detail below.
Dealing with Layout Anomalies
In the following dataflow, you can see that the source entity allows for three default fields, which are then enhanced with a variable and constant value transformation.
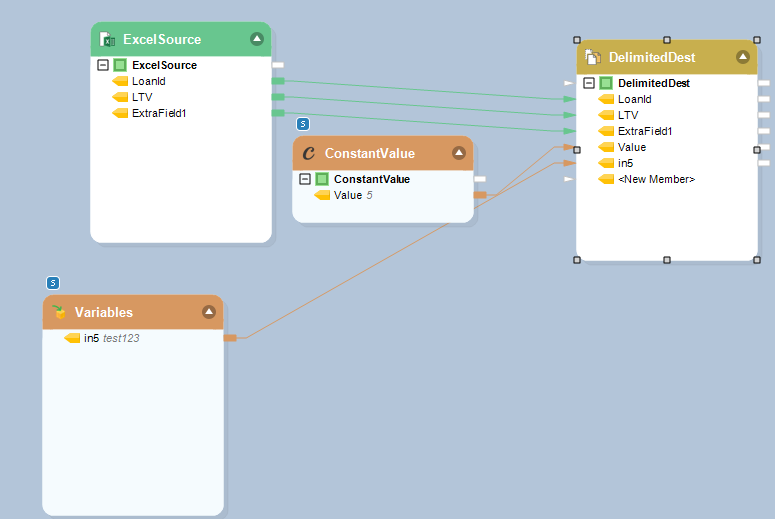
Single Object Updated in a Dynamic Layout
Now, we can use the layout builder screen to set up a new parameter for the source, as shown below.
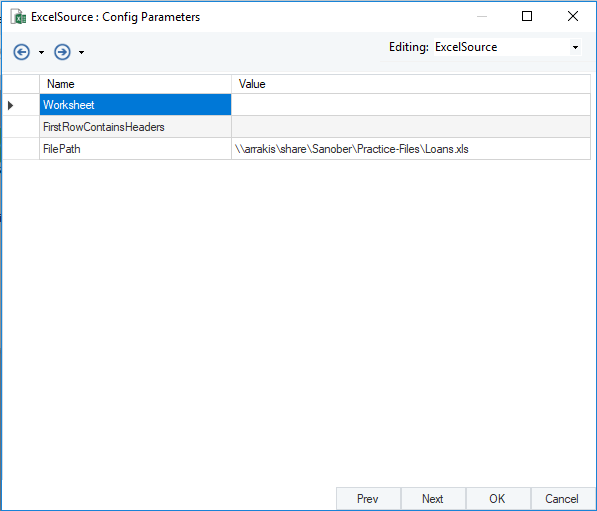
Parameter Configuration in Source Entity Layout Builder
Once dynamic layouts are enabled, the output for this entity is automatically updated with all new fields pushed through the same mapping logic. The new table structure appears as follows:
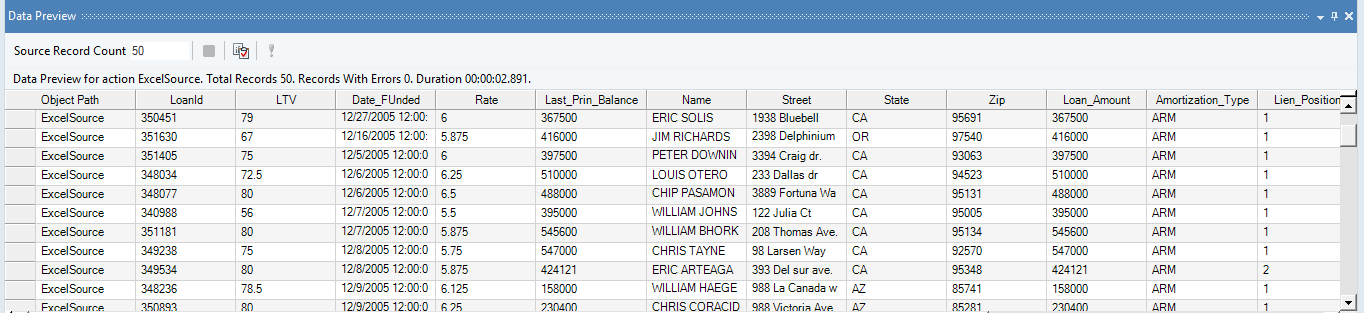
Data Preview Showing Added Fields for Source Entity in Dynamic Layout
We can further test this feature by adding a field to the source file without changing the layout of the source object in Astera Centerprise. This will show us if the change is accurately reflected in dataflow.
Suppose we check the output at the destination after re-running the dataflow. In that case, we can see that a differential has been automatically executed to resolve any discrepancies between the source entity and the Excel file. The additional field is then seamlessly incorporated into the existing mapping. The exact process will occur whenever fields are removed from the source file.
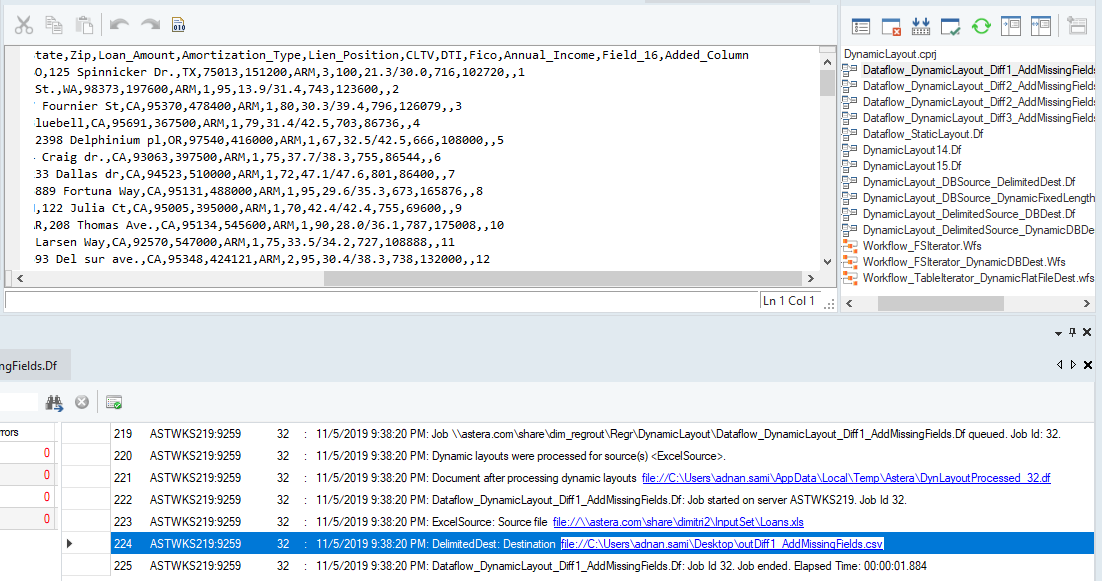
Dynamically Updated Output
Dynamic Layouts in High-Volume Data Migrations
Dynamically Updated Databases
The actual effectiveness of this feature becomes apparent when we implement it in a workflow object, which picks an array of source files from a repository and runs them through a series of pre-set transformations.
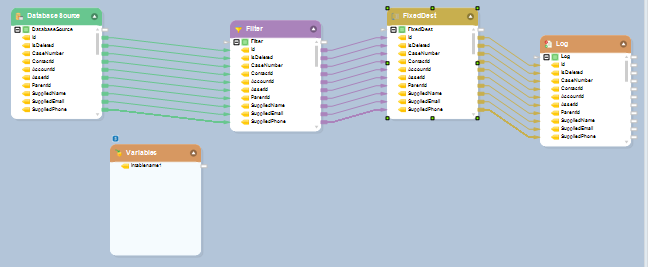
Multiple Source Objects Updated in a Dynamic Layout
Above, we have a dynamic database source configured to point towards an input defined in the variable transformation.
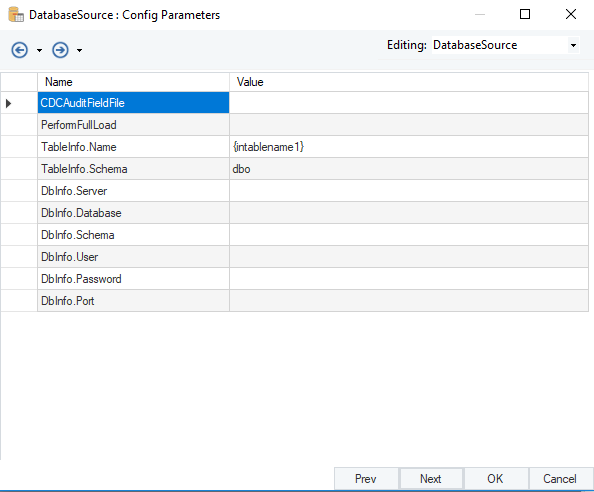
Config Parameters for Database Source
However, the variable transformation contains no definitions for a source file or directory.
In this case, the definitions are supplied by an external File System Items Source in a workflow (See below)
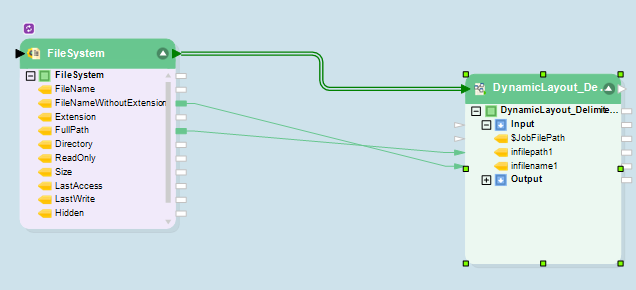
External File System Source Supplying Definitions to Dynamically Updated Dataflow
This source object is set up to point toward a directory containing 26 different files, each with a different layout.
As you can see above, the full path and the input filename has been linked to a variable object in the dataflow. This workflow has also been set up to run on a loop, so each file in the source directory will be picked up and run through the dataflow object, which will dynamically adapt to the new layout and run the source file through the transformations provided in the last use case without the need for any manual adjustment by the user.
We have also configured the destination table in our original dataflow to load all transformed files into a CSV target, defined as an uppercase version of the source filename as denoted by a different expression in the variable entity.
Dynamically Updated SQL Queries
We’ve used the SQL Query Source object to select all fields from the Employees table in the source database in the diagram below.
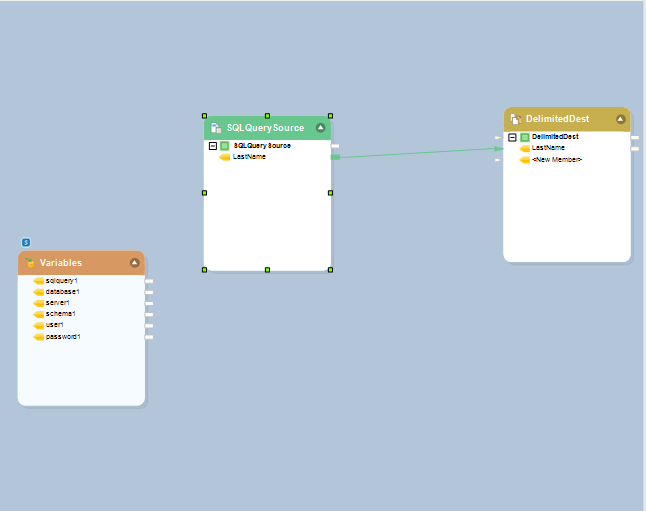
SQL Query Source in a Dynamic Dataflow
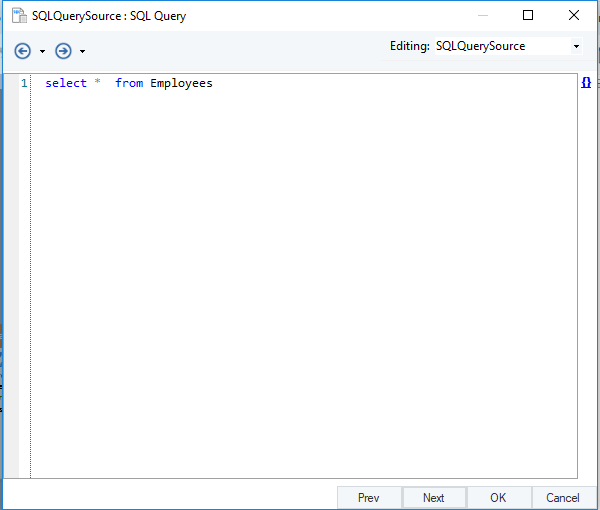
SELECT statement
Once again, the parameter paths in the variable are dependent on inputs from an external workflow object, as seen below.
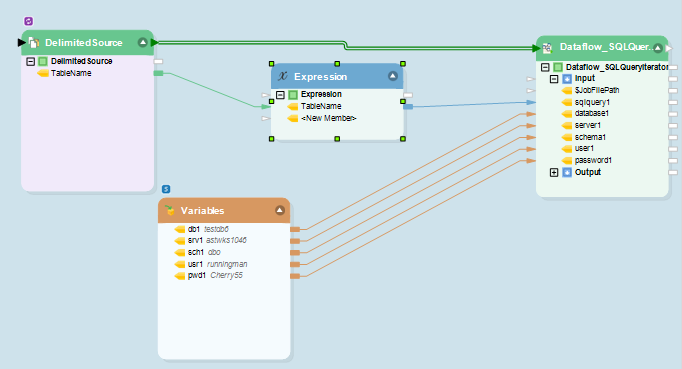
External Workflow Source Providing Parameter Values for Dynamic Dataflow
In this case, we have selected a delimited source that contains a total of 26 table names. This object is passed through an expression transformation that places the supplied table name in a SELECT statement
This statement is then linked to the sqlquery1 input variable field in the dataflow. As a result, the select statement performed at the source in Fig 4 will be updated dynamically to pick data from a new table each time the dataflow is executed.
Each new dynamically generated dataflow can also be accessed individually if additional adjustments are required based on the input table.
As you can see, the source file in Fig 5 has been set to run on a loop, so the workflow will continue to supply new table names, which will be used in Fig 4’s SQL query source. By implementing dynamic layouts, users can save themselves the time and effort spent on building several individual dataflows to perform the same operations on disparate source tables.
Data Cleansing and Dynamic Layouts
Another highly effective implementation of dynamic layouts is in large-scale data cleansing operations. A constantly updated dataset must be validated for accuracy and consistency before being passed onto reporting and analytics systems.
In a conventional schema, the layout must be manually updated whenever source data is updated. In cases where the concerned function made structural changes to their tables without informing developers, data cleansing activities may be disrupted altogether. This will create a sizeable impact on decision-making at both executive and operational levels.
What’s more, if multiple tables need to be cleansed in the same manner, then the developers would need to create individual processes to deal with each source.
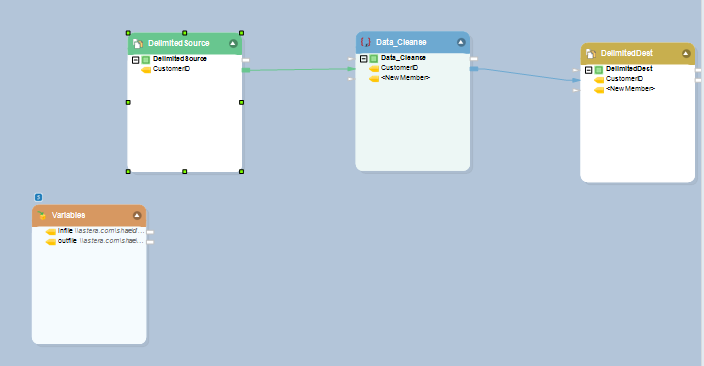
Data Cleansing in Dynamically Updated Dataflow
The figure above shows a source object which is configured to pick CSV files from an input source based on values provided in the variable transformation.
The target entity has been similarly configured to create a new destination based on the definitions provided in the variable transformation.
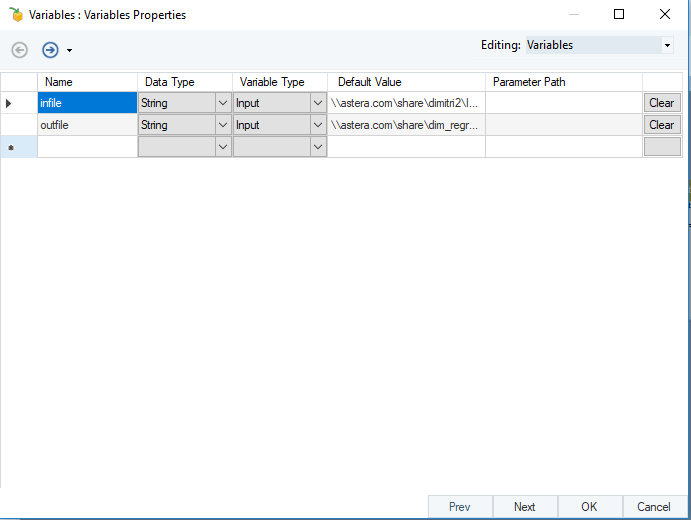
Variable Values for Input and Output
Data Cleansing of Input Fields
While the dataflow currently shows only one field being pushed through this process, we can add several additional columns to the source without any issue.
These will be integrated seamlessly into the existing mapping based on the CustomerID guide field, transformed, and output to the newly configured destination.
Astera Centerprise’s Dynamic Layouts Feature
Looking to propagate changes to a destination object or build a complete dataflow pipeline that can respond in real-time to updates and modifications to your source datasets? Astera Centerprise lets you add dynamic layouts which add flexibility to even the most complex data mappings.
You can schedule a no-obligation consultation with our technical team today for more information on this and other features.



