
The Automated, No-Code Data Stack
Learn how Astera Data Stack can simplify and streamline your enterprise’s data management.

Synonym-Driven File Reading and Mapping in Astera Centerprise
Data is the lifeblood of the modern economy, and any enterprise that aims to gain tangible value from its information assets must learn how to manage and maximize the various inputs arriving across their functions. However, this task has become increasingly challenging in today’s globalized market where most companies operate within dispersed networks consisting of business partners, resellers, suppliers, sister concerns, and more. These networks are often subjected to varying regulatory, geopolitical, and economic factors that affect how each party prepares and presents their data.
In this environment, large organizations must ensure that they have effective processes in place to gather and integrate data from disparate third-party sources in a timely and cost-effective manner. Otherwise, potential risks and opportunities that might have been uncovered may be missed altogether.
With Astera Centerprise’s new smart match functionality, clients can automate how data inconsistencies and formatting irregularities are treated in their ETL and ELT pipelines.
In this document, we will provide a quick overview of a few reasons that make third-party application integration complex, along with a detailed use-case on how synonym-driven file reading and mapping feature can be employed in Astera Centerprise to address the challenge.
Managing External Data: Advantages and Challenges
From The Washington Post that uses data on readers’ clicks and engagement to improve newsroom workflows to The Climate Corporation that uses geopolitical, weather, and IoT data to help farmers predict and optimize crop yields, there are several examples available that demonstrate how optimizing internal and external data integration creates competitive advantages. Unfortunately, the tremendous amount and variety of data that is generated externally can make this an extremely resource-intensive process.
The challenges faced in dealing with external data can be categorized based on the phase of the data lifecycle in which they occur, i.e. extraction, transformation, and loading/integration. Figure 1 contains a non-exhaustive overview of these challenges.
Figure 1: Challenges of Using External Data |
|
| Phase 1: Extraction or Acquisition of External Data | Inability to integrate external data sources |
| Multiple users have access to the same dataset (data duplication) | |
| Different versions of a single dataset | |
| Phase 2: Transforming External Data | Inconsistencies between external and internal data |
| Handling inaccuracies in external data | |
| Phase 3: Loading data into a centralized data repository | Designing a data warehouse to handle structured and unstructured data streams |
|
Serving custom datasets to business users via APIs |
|
We will be focusing on the challenge of handling variation in data collected from third-party applications and ensuring consistency between internal and external data using the synonym-driven file reading and mapping feature in Astera Centerprise.
Achieving Data Consistency with Synonym-Driven File Reading and Mapping
Layout synonym inconsistencies occur between source systems and reporting structures in both single repositories, such as databases, as well as consolidated architectures such as data warehouses and federated database systems. In the latter case where multiple data sources are brought together and combined for reporting and analytics, there are likely to be far more variations in the naming and formatting of incoming data layouts.
One of the ways to achieve layout consistency is to analyze individual sources, and identify and resolve all header inconsistencies manually, and then rebuild the related dataflows based on corrected inputs. In addition, data consistency cannot be achieved by a process that works in isolation and must be based on comprehensive standards that are applied across all datasets coming into the organization. These issues will only become more pronounced as the number of external sources increases.
Synonym-driven file reading and mapping provide an intuitive and scalable method of resolving naming conflicts and inconsistencies that arise during high-volume data integrations through data-driven synonym. With this synonym driven feature, users can build a custom library that contains values for current and alternative values that may appear in the header field of an input table. Centerprise will then automatically match irregular headers to the correct column at run-time and extract data from them as normal.
Variant source objects can also be easily integrated into existing dataflows through a new automapping feature that allows anomalous fields to be matched to corresponding values in subsequent transformations and target entities.
The SmartMatch Feature: A Multi-Client Use Case
To gain better understanding of how the feature works in Astera Centerprise, let’s consider the example of a car insurance company by the name of XYZ that provides insurance claims processing for its client companies, as well as individual customers. The company receives claims data that needs to be extracted, filtered, cleansed, and delivered to concerned departments.
The rest of the process then comprises of analyzing the data, printing the appropriate forms and mailing them to the claimant. A critical bottleneck that impacts efficiency for such an organization is integrating claims data received from various client companies and customers for further processing.
Many of the larger clients still rely on manual data entry to gather claims data into spreadsheets before emailing them to the insurance company. As a result, much of the policy information received follows a non-standard format, with naming conventions varying significantly based on the claimant. Currently, XYZ’s IT administrators are forced to resolve these discrepancies by creating new dataflow pipelines for each individual source.
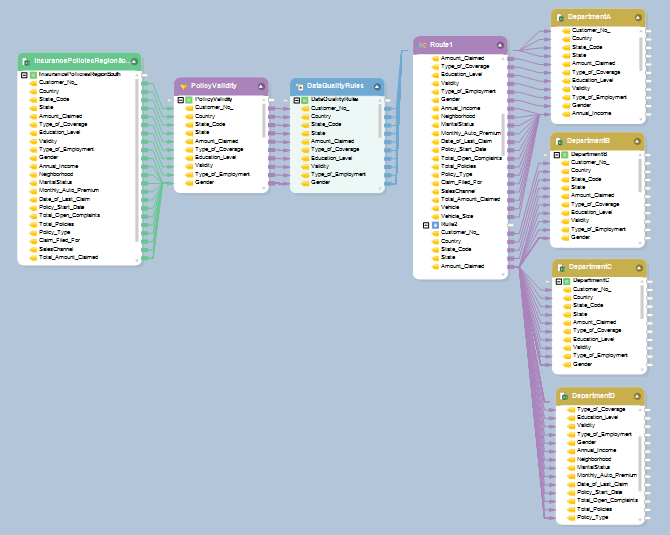
Claims Processing Dataflow for Large Clients – XYZ Insurers
With SmartMatch functionality enabled, a single dataflow can be used to process multiple claimant files despite different naming conventions. To do so, it simply creates a synonym for the insurance industry in terms of file dictionary that can be implemented across its claims processing project.
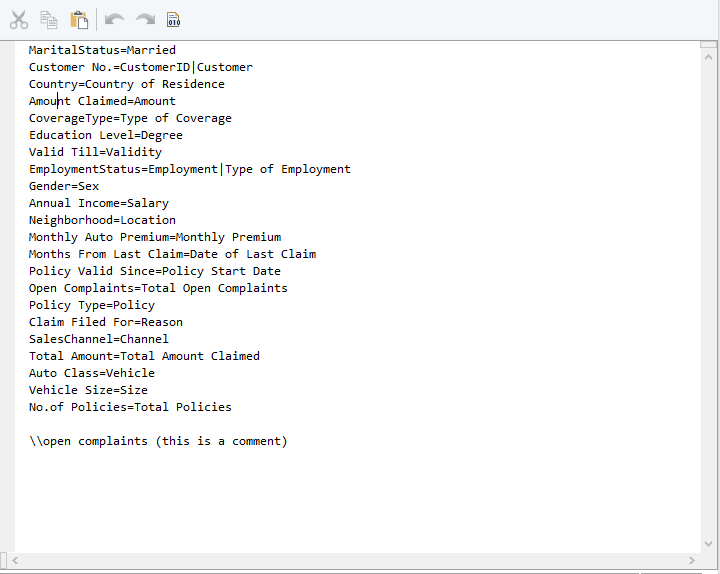
Synonym File Dictionary for XYZ Insurers
Next, they create a looped workflow that is set to pick up Excel files transmitted from various claimants and run them through the original dataflow on a continuous basis.
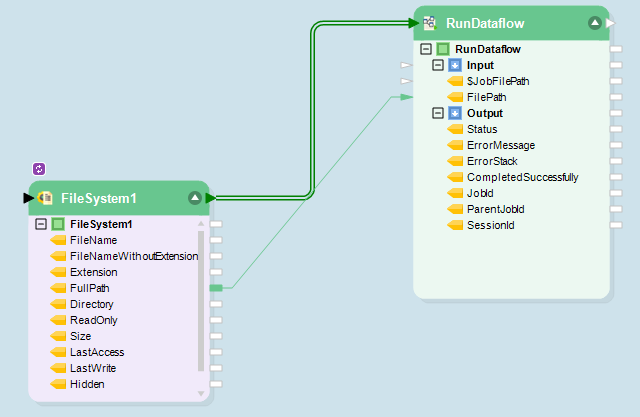
XYZ Insurer Workflow
When the workflow is initiated, the dataflow source object will first look for an exact header match in the incoming Excel file columns as specified in the original layout. If this isn’t found, then Centerprise will search for headers that exactly match the alternative definitions provided in the synonym file dictionary above i.e. “Annual Income = Salary”. Additional definitions are created using the ‘’|’’ command – i.e. “Customer No. = CustomerID|Customer”

SmartMatch also allows for token matching, which means that alternative definitions can be set up for partial values that may be repeated across multiple headers in an input source object. For example “No.=Number|#” If XYZ used this token in their synonym dictionary, then any input sources that used the provided alternative naming conventions for the value No. could be integrated into the existing dataflow without any manual adjustment.
If the SmartMatch feature is still unable to resolve header inconsistencies in new input files, then Centerprise will employ compact string matching. This means that all punctuation marks and spaces will be removed from input column names and then matched against definitions in the original layout and dictionary. For example, a claimant may define their Policy Valid Since field under the header Policy: Start Date – as you can see this value does not match any of the definitions described above. As a result, the compact string match will remove the colon and attempt to reconcile the irregularities.
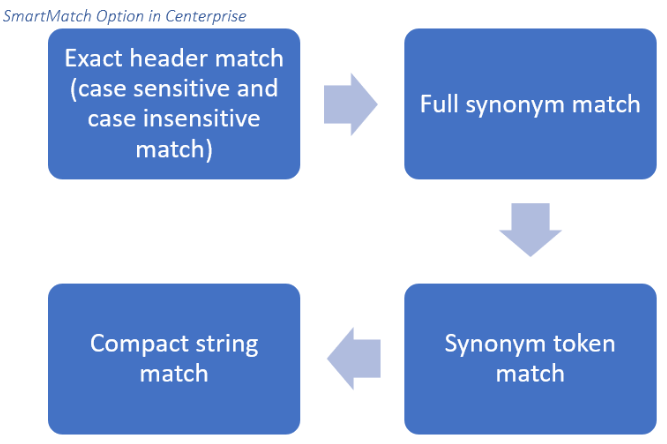
Smart Matching Process
SmartMatch and Auto-Mapping
SmartMatch is also effective in reconciling any irregularities that occur between two objects in a dataflow. For example, if one of XYZ’s receiving departments defines certain fields differently from the source object then the auto-mapping option can help isolate these discrepancies. Once these are identified, users can add the missing definition to their synonym dictionary and ensure uninterrupted dataflow execution.
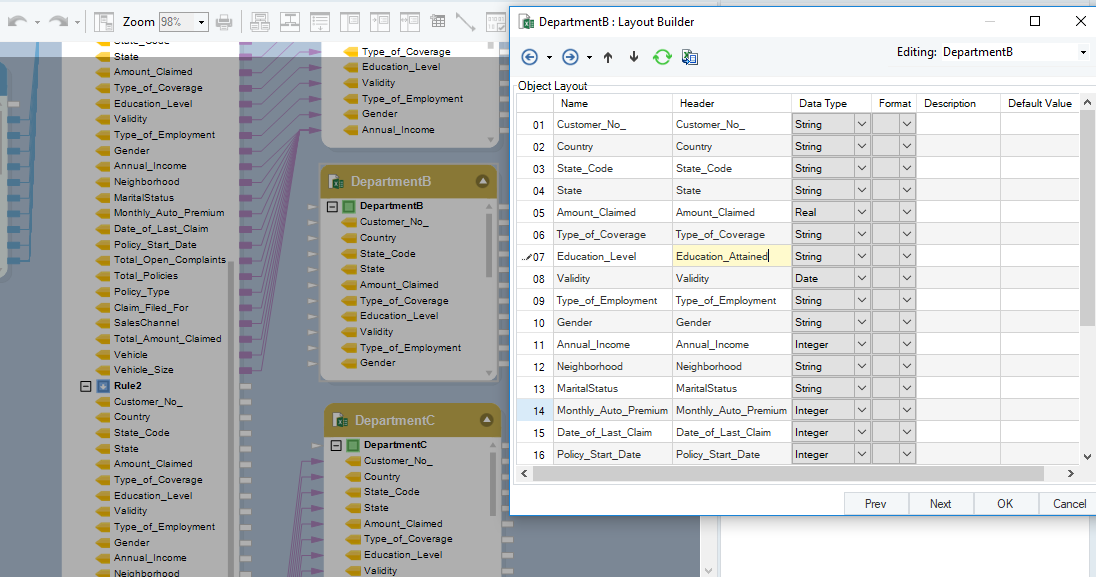
Auto-mapping Shows Discrepancies
As you can see, the Education_Level field is defined as Education_Attained in Department B’s layout. This difference in naming conventions can be sorted out in the dictionary file either through an exact or token match definition. Auto-mapping is then simply performed again and the unmapped field will be integrated into the dataflow.
The array of SmartMatch features described in this blog can help organizations in any industry create more adaptable, scalable data pipelines that are better designed to handle a wide variety of external and internal sources. Explore this feature first-hand by downloading the trial version of Astera Centerprise 8.0.
Authors:
Adnan Sami Khan



