

The Automated, No-Code Data Stack
Learn how Astera Data Stack can simplify and streamline your enterprise’s data management.
What is Data Warehouse Architecture?
For the past few decades, the data warehouse architecture has been the pillar of corporate data ecosystems. And despite numerous alterations over the last five years in the arena of big data, cloud computing, predictive analysis, and information technologies, data warehouses have only gained more significance.
Today, the importance of data warehousing cannot be denied, and there are more possibilities available for storing, analyzing, and indexing data than ever.
This article will discuss the various basic concepts of an enterprise data warehouse architecture, different enterprise data warehouse (EDW) models, their characteristics, and significant components, and explore the primary purpose of a data warehouse in modern industries.
Data Warehouse Architecture Theories
To understand data warehouse architecture, it is important to know about Ralph Kimball and Bill Inmon, the two prominent figures in the field of data warehousing. These two proposed different approaches to designing data warehousing architectures.
Kimball Approach
Ralph Kimball is known for his dimensional modeling approach, which focuses on delivering data in a way that is optimized for end-user query and reporting. The Kimball approach focuses on creating data warehouses using star schema structures, where a central fact table holds quantitative measures, and dimension tables describe related attributes. It is a top-down, iterative, and agile approach that emphasizes the rapid delivery of business value by building subject-specific data marts to cater to specific user reporting needs.
Inmon Approach
Bill Inmon’s approach, on the other hand, emphasizes a more centralized, comprehensive, and structured data warehousing environment. It advocates a normalized data model where data is organized into separate tables to eliminate redundancy and maintain data integrity. It uses a “data warehouse bus” concept to create standardized, reusable components and emphasizes data integration, transformation, and governance to ensure data accuracy and consistency.
Components of DWH Architecture
Before we move on to the specifics of the architecture, let’s understand the basics of what makes a data warehouse—the skeleton behind that structure.
The different layers of a data warehouse or the components in a DWH architecture are:
- Data Warehouse Database
The central component of a typical data warehouse architecture is a database that stocks all enterprise data and makes it manageable for reporting. Obviously, this means you need to choose which kind of database you’ll use to store data in your warehouse.
The following are the four database types that you can use:
- Typical relational databases are the row-centered databases you perhaps use on an everyday basis —for example, Microsoft SQL Server, SAP, Oracle, and IBM DB2.
- Analytics databases are precisely developed for data storage to sustain and manage analytics, such as Teradata and Greenplum.
- Data warehouse applications aren’t exactly storage databases, but several dealers now offer applications that offer software for data management as well as hardware for storing data. For example, SAP Hana, Oracle Exadata, and IBM Netezza.
- Cloud-based databases can be hosted and retrieved on the cloud so that you don’t have to procure any hardware to set up your data warehouse—for example, Amazon Redshift, Google BigQuery, and Microsoft Azure SQL.
2. Extraction, Transformation, and Loading Tools (ETL)
ETL tools are central components of an enterprise data warehouse design. These tools help extract data from different sources, transform it into a suitable arrangement, and load it into a data warehouse.
The ETL tool you choose will determine the following:
- The time expended in data extraction
- Approaches to extracting data
- Kind of transformations applied and the simplicity of doing so
- Business rule definition for data validation and cleansing to improve end-product analytics
- Filling mislaid data
- Outlining information distribution from the fundamental depository to your BI applications

3. Metadata
In a typical data warehouse architecture, metadata describes the data warehouse database and offers a framework for data. It helps in constructing, preserving, handling, and making use of the data warehouse.
There are two types of metadata in data warehousing:
- Technical Metadata comprises information that can be used by developers and managers when executing warehouse development and administration tasks.
- Business Metadata includes information that offers an easily understandable standpoint of the data stored in the warehouse.

Role of Metadata in a Data Warehouse
Metadata plays an important role for businesses and technical teams to understand the data present in the warehouse and convert it into information.
Your data warehouse isn’t a project; it’s a process. To make your implementation as effective as possible, you need to take a truly agile approach, which necessitates a metadata-driven data warehouse architecture.
This is a visual approach to data warehousing that leverages metadata-enriched data models to drive every aspect of the development process, from documenting source systems to replicating schemas in a physical database and facilitating data mapping from source to destination.
The data warehouse schema is set up at the metadata level, which means you don’t have to worry about code quality and how it will stand up to high volumes of data. In fact, you can manage and control your data without going into the code.
Also, you can test data warehouse models concurrently before deployment and replicate your schema in any leading database. A metadata-driven approach leads to an iterative development culture and futureproofs your data warehouse deployment, so you can update the existing infrastructure with the new requirements without disrupting your data warehouse’s integrity and usability.
Coupled with automation capabilities, a metadata-driven data warehouse design can streamline design, development, and deployment, leading to a robust data warehouse implementation.
4. Data Warehouse Access Tools
A 0data warehouse uses a database or group of databases as a foundation. Data warehouse corporations generally cannot work with databases without the use of tools unless they have database administrators available. However, that is not the case with all business units.
This is why they use the assistance of several no-code data warehousing tools, such as:
- Query and reporting tools help users produce corporate reports for analysis that can be in the form of spreadsheets, calculations, or interactive visuals.
- Application development tools help create tailored reports and present them in interpretations intended for reporting purposes.
- Data mining tools for data warehousing systematize the procedure of identifying arrays and links in huge quantities of data using cutting-edge statistical modeling methods.
- OLAP tools help construct a multi-dimensional data warehouse and allow the analysis of enterprise data from numerous viewpoints.
5. Data Warehouse Bus
It defines the data flow within a data warehousing bus architecture and includes a data mart. A data mart is an access level that allows users to transfer data. It is also used for partitioning data that is produced for a particular user group.
6. Data Warehouse Reporting Layer
The reporting layer in the data warehouse allows the end-users to access the BI interface or BI database architecture. The purpose of the reporting layer in the data warehouse is to act as a dashboard for data visualization, create reports, and take out any required information.
Characteristics of Data Warehouse Design
The following are the main characteristics of data warehousing design, development, and best practices:
Theme-Focused
A data warehouse design uses a particular theme. It provides information concerning a subject rather than a business’s operations. These themes can be related to sales, advertising, marketing, and more.
Instead of focusing on business operations or transactions, data warehousing emphasizes business intelligence (BI), i.e., displaying and analyzing data for decision-making. It also offers a straightforward and concise interpretation of a particular theme by eliminating data that may not be useful for decision-makers.
Unified
Using data warehouse modeling, a data warehouse design unifies and integrates data from different databases in a collectively suitable manner.
It incorporates data from diverse sources, such as relational and non-relational databases, flat files, mainframes, and cloud-based systems. Besides, a data warehouse must maintain consistent classification, layout, and coding to facilitate efficient data analysis.
Time Variance
Unlike other operational systems, the data warehouse stores centralized data from a certain time period. Therefore, The data warehouse identifies the gathered data within a specific time duration and provides insights from the past perspective. Moreover, it does not allow the structure or alteration of the data after it enters the warehouse.
Non-volatility
Non-volatility is another important characteristic of a data warehouse, meaning that it does not remove the primary data when new information is loaded. Moreover, it only allows data reading and intermittent refreshing to provide a complete and updated picture to the user.
Types of Data Warehouse Architecture
The architecture of a typical data warehouse defines the arrangement of data in different databases. To extract valuable information from raw data, a modern data warehouse structure identifies the most effective technique for organizing and cleansing the data.
Using a dimensional model, the data warehouse extracts and converts the raw data in the staging area into a simple consumable warehousing structure to deliver valuable business intelligence.
Moreover, unlike a cloud data warehouse, a traditional data warehouse model requires on-premises servers for all warehouse components to function.
When designing a corporate data warehouse, there are three different types of models to consider:
Single-tier data warehouse
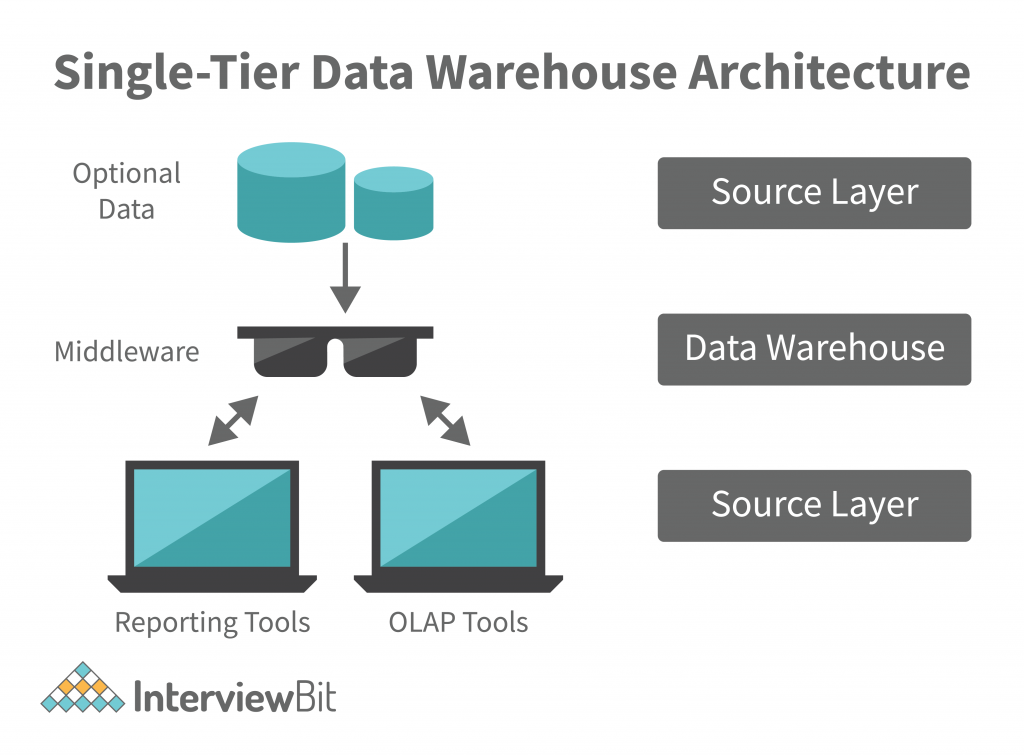
Source: InterviewBit
The structure of a single-tier data warehouse architecture produces a dense set of data and reduces the volume of the deposited data.
Although it is beneficial for eliminating redundancies, this type of warehouse design is not suitable for businesses with complex data requirements and numerous data streams. This is where multi-tier data warehouse architectures come in as they deal with more complex data streams.
Two-tier data warehouse

Source: InterviewBit
In comparison, the data structure of a two-tier data warehouse model splits the tangible data sources from the warehouse itself. Unlike a single-tier, the two-tier design uses a system and a database server.
Small organizations where a server is used as a data mart typically use this type of data warehouse architecture type. Although it is more efficient at data storage and organization, the two-tier structure is not scalable. Moreover, it only supports a nominal number of users.
Three-tier data warehouse

The three-tier data warehouse architecture type is the most common type of modern DWH design as it produces a well-organized data flow from raw information to valuable insights.
The bottom tier in the data warehouse model typically comprises the databank server that creates an abstraction layer on data from numerous sources, like transactional databanks utilized for front-end uses.
The middle tier includes an Online Analytical Processing (OLAP) server. This level alters the data into a more suitable arrangement for analysis and multifaceted probing from a user’s perspective. Since it includes an OLAP server pre-built in the architecture, we can also call it the OLAP-focused data warehouse.
The third and topmost tier is the client level which includes the tools and Application Programming Interface (API) used for high-level data analysis, inquiring, and reporting.
However, people barely include the 4th-tier in the data warehouse architecture as it is often not considered as integral as the other three types.
Now, let’s learn about the major components of a data warehouse (DWH) and how they help build and scale a data warehouse in detail.

Cloud Based Data Warehouse Architecture
A cloud-based data warehouse architecture leverages cloud computing resources to store, manage, and analyze data for business intelligence and analytics. The foundation of this data warehouse is the cloud infrastructure provided by cloud service providers like AWS (Amazon Web Services), Azure, or Google Cloud. These providers offer on-demand resources such as computing power, storage, and networking.
Here are the major components of the cloud-based data warehouse architecture:
- Data Ingestion: The first component is a mechanism for ingesting data from various sources, including on-premises systems, databases, third-party applications, and external data feeds.
- Data Storage: The data is stored in the cloud data warehouse, which typically uses distributed and scalable storage systems. The choice of storage technology may vary based on the cloud provider and architecture, with options like Amazon S3, Azure Data Lake Storage, or Google Cloud Storage.
- Compute Resources: Cloud-based data warehouses provide flexible and scalable compute resources for running analytical queries. These resources can be provisioned on-demand, so businesses can adjust processing power based on workload requirements.
- Auto-Scaling: Cloud-based data warehouses often support auto-scaling, which makes it easier for businesses to dynamically adjust to meet the demands of the workload.
Traditional vs. Cloud Data Warehouse Architecture Models
While traditional data warehouses offer full control over hardware and data location, they often come with higher upfront costs, limited scalability, and slower deployment times. Cloud data warehouses, on the other hand, provide advantages in terms of scalability, cost-effectiveness, global accessibility, and ease of maintenance, with the trade-off of potentially reduced control over data location and residency.
The choice between the two architectures depends on an organization’s specific needs, budget, and preferences. Here is a deeper look of the differences between the two:
| Aspect | Traditional Data Warehouse | Cloud Data Warehouse |
| Location and Infrastructure | On-premises, with dedicated hardware | Cloud-based, utilizing cloud provider’s infrastructure |
| Scalability | Limited scalability, hardware upgrades required for growth | Highly scalable, with on-demand resources to scale up or down |
| Capital Expenses | High initial capital costs for hardware and infrastructure | Lower upfront capital costs, pay-as-you-go pricing model |
| Operational Expenses | Ongoing operational costs for maintenance, upgrades, and power/cooling | Reduced operational costs as cloud provider handles infrastructure maintenance |
| Deployment Time | Longer deployment times for hardware procurement and setup | Faster deployment due to readily available cloud resources |
| Global Accessibility | Access limited to on-premises locations, may require complex setups for global access | Easily accessible from anywhere in the world, with the ability to distribute data globally |
| Scalability | Limited scalability, hardware upgrades required for growth | Highly scalable, with on-demand resources to scale up or down |
| Data Integration | Integration with external data sources can be complex and resource-intensive | Streamlined data integration with cloud-based ETL tools and services |
| Data Security | Security and compliance are managed in-house, potentially complex | Cloud providers offer robust security features, with encryption, access controls, and compliance measures |
| Backup and Disaster Recovery | Involves setting up and managing backup and disaster recovery solutions | Cloud providers offer built-in backup and disaster recovery options |
| Resource Provisioning | Manual provisioning and capacity planning for hardware resources | Automatic resource provisioning, scaling, and management |
| Flexibility and Agility | Limited flexibility, less agile in responding to changing business needs | Greater flexibility and agility, with the ability to scale resources on-demand |
| Cost Model | Capital expenditure model, where costs are upfront and fixed | Operating expenditure model, with flexible pay-as-you-go pricing |
| Maintenance and Updates | In-house responsibility for hardware maintenance, updates, and patches | Cloud provider handles infrastructure maintenance, updates, and patching |
| Integration with BI Tools | Integration with BI tools may require additional setup and management | Seamless integration with a wide range of BI and analytics tools |
| Data Governance | Requires in-house governance processes and tools | Cloud-based data warehouses often provide data governance features and tools |
| Data Location Control | Full control over data location and residency | Cloud-based data may be distributed across regions, with data residency subject to cloud provider policies |
| Resource Monitoring | Requires setting up monitoring tools and systems | Cloud providers offer built-in monitoring and analytics for resource usage |
Customizing DW Architecture with staging area & Data Marts
You can customize your data warehouse architecture with a staging area and data marts. With this customization, you can provide the right data to the right users, which makes it more efficient and effective for business intelligence and analytics.
Staging Area:
- Purpose: A staging area is an intermediate storage space within the data warehouse architecture where raw or minimally processed data is temporarily stored before being loaded into the main data warehouse.
- Customization: You can customize the staging area based on your organization’s data integration needs. For example, you can design the staging area to accommodate data transformation, data cleansing, and data validation processes that prepare the data for analysis.
Data Marts:
- Purpose: Data marts are subsets of a data warehouse that are specifically designed to serve the analytical needs of business departments, functions, or user groups. They contain pre-aggregated and tailored data for specific types of analysis.
- Customization: To customize the data warehouse architecture with data marts, you need to design and populate these data marts based on the unique requirements of each department or user group.

Best Practices of Data Warehouse Architecture
- Create data warehouse models that are optimized for information retrieval in both dimensional, de-normalized, or hybrid approaches.
- Decide between an ETL or an ELT approach to data integration.
- Select a single approach for data warehouse designs, such as the top-down or the bottom-up approach, and stick with it.
- If using an ETL approach, always cleanse and transform data using an ETL tool before loading the data to the data warehouse.

Photo taken from medium.com/@vishwan/data-preparation-etl-in-business-performance-37de0e8ef632
- Create an automated data cleansing process where all data is uniformly cleaned before loading.
- Allow sharing of metadata between different components of the data warehouse for a smooth extraction process.
- Adopt an agile approach instead of a fixed approach to building your data warehouse.
- Always make sure that data is properly integrated and not just consolidated when moving it from the data stores to the data warehouse. This would require the 3NF normalization of data models.
Automating Data Warehouse Design
Automating data warehouse design can jumpstart your data warehouse development. It’s essential to get your approach right.
First, identify where your critical business data resides and which data is relevant for your BI initiatives. Then, create a standardized metadata framework that provides critical context for this data at the data modeling stage.
Such a framework would match your data warehouse model to the source system, ensuring appropriate construction of relationships between entities with correctly defined primary and foreign keys. It would also establish correct table joins and accurately assign entity-relationship types.
Also, you need to have processes in place that allow you to integrate new sources and other modifications into your source data model and redeploy it. Taking an iterative approach will provide a more granular outlook on the data delivered for BI purposes and materialized views.
You may adopt a 3NF or dimensional modeling approach, depending on your BI requirements. The latter is better as it will help you create a streamlined, denormalized structure for your data warehouse model.
While you’re at it, here are some essential tips that you should keep in mind:
- Maintain a consistent grain in dimensional data models
- Apply the correct SCD-handling technique to your dimensional attributes
- Streamline fact table loading using a metadata-driven approach
- Put processes in place to deal with early-arriving facts
Finally, team members can test data quality and the integrity of data models before they are deployed on the target database. Having an automated data model verification tool can provide significant time savings.
Following these best practices when automating schema modeling will help you seamlessly update your model and propagate changes across your data pipelines.
The next step in the data warehouse designing process is selecting the right data warehousing architecture.
Build Your Data Warehouse with Astera DW Builder

Astera DW Builder is an end-to-end data warehousing solution that automates the designing and deployment of a data warehouse in a code-free environment.
It uses a meta-driven approach that enables users to manipulate data using a comprehensive set of built-in transformations without complex ETL scripting or SQL scripting.
Learn More About The Best Data Warehouse Architecture For Reporting.




